 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Trust in Conversational AI: A Comprehensive Review and Solution Architecture for Explainable, Privacy-Aware Systems using LLMs and Knowledge Graph
Aug 13, 2023Conversational AI systems have emerged as key enablers of human-like interactions across diverse sectors. Nevertheless, the balance between linguistic nuance and factual accuracy has proven elusive. In this paper, we first introduce LLMXplorer, a comprehensive tool that provides an in-depth review of over 150 Large Language Models (LLMs), elucidating their myriad implications ranging from social and ethical to regulatory, as well as their applicability across industries. Building on this foundation, we propose a novel functional architecture that seamlessly integrates the structured dynamics of Knowledge Graphs with the linguistic capabilities of LLMs. Validated using real-world AI news data, our architecture adeptly blends linguistic sophistication with factual rigour and further strengthens data security through Role-Based Access Control. This research provides insights into the evolving landscape of conversational AI, emphasizing the imperative for systems that are efficient, transparent, and trustworthy.
Background Knowledge Injection for Interpretable Sequence Classification
Jun 25, 2020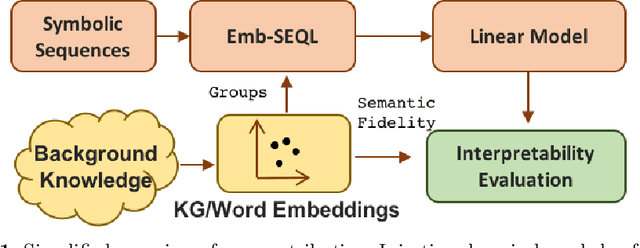
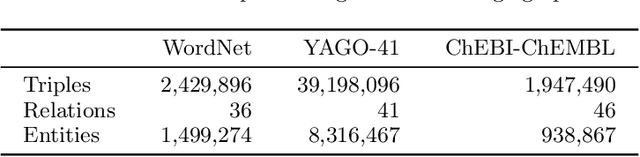
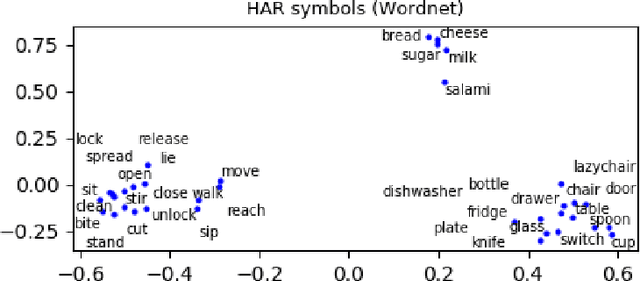
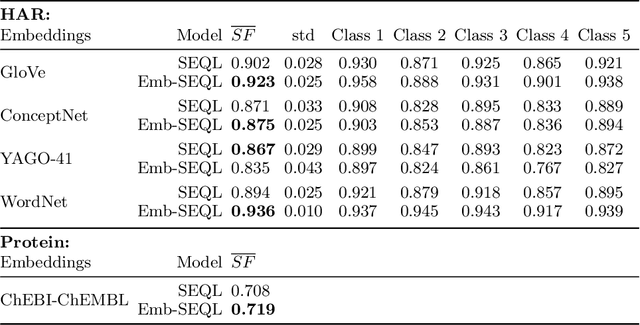
Sequence classification is the supervised learning task of building models that predict class labels of unseen sequences of symbols. Although accuracy is paramount, in certain scenarios interpretability is a must. Unfortunately, such trade-off is often hard to achieve since we lack human-independent interpretability metrics. We introduce a novel sequence learning algorithm, that combines (i) linear classifiers - which are known to strike a good balance between predictive power and interpretability, and (ii) background knowledge embeddings. We extend the classic subsequence feature space with groups of symbols which are generated by background knowledge injected via word or graph embeddings, and use this new feature space to learn a linear classifier. We also present a new measure to evaluate the interpretability of a set of symbolic features based on the symbol embeddings. Experiments on human activity recognition from wearables and amino acid sequence classification show that our classification approach preserves predictive power, while delivering more interpretable models.
Interpretable Credit Application Predictions With Counterfactual Explanations
Nov 16, 2018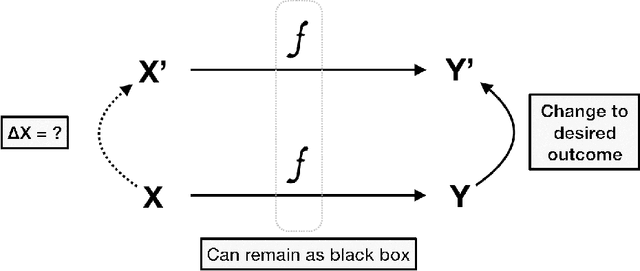

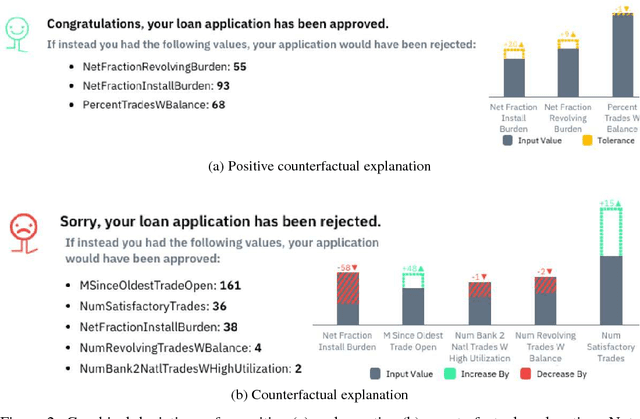

We predict credit applications with off-the-shelf, interchangeable black-box classifiers and we explain single predictions with counterfactual explanations. Counterfactual explanations expose the minimal changes required on the input data to obtain a different result e.g., approved vs rejected application. Despite their effectiveness, counterfactuals are mainly designed for changing an undesired outcome of a prediction i.e. loan rejected. Counterfactuals, however, can be difficult to interpret, especially when a high number of features are involved in the explanation. Our contribution is two-fold: i) we propose positive counterfactuals, i.e. we adapt counterfactual explanations to also explain accepted loan applications, and ii) we propose two weighting strategies to generate more interpretable counterfactuals. Experiments on the HELOC loan applications dataset show that our contribution outperforms the baseline counterfactual generation strategy, by leading to smaller and hence more interpretable counterfactuals.