 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Future of MLLM Prompting is Adaptive: A Comprehensive Experimental Evaluation of Prompt Engineering Methods for Robust Multimodal Performance
Apr 14, 2025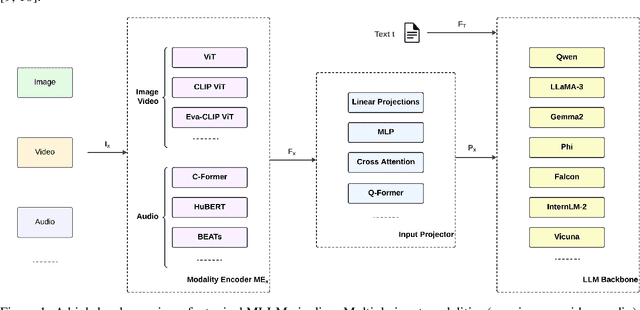
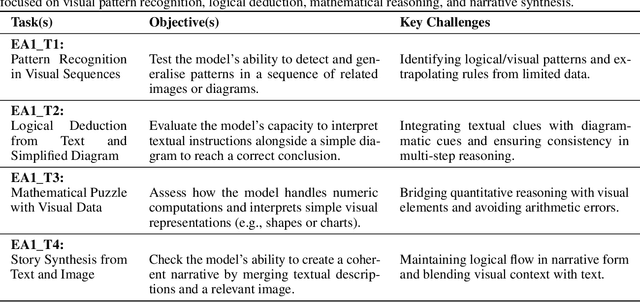

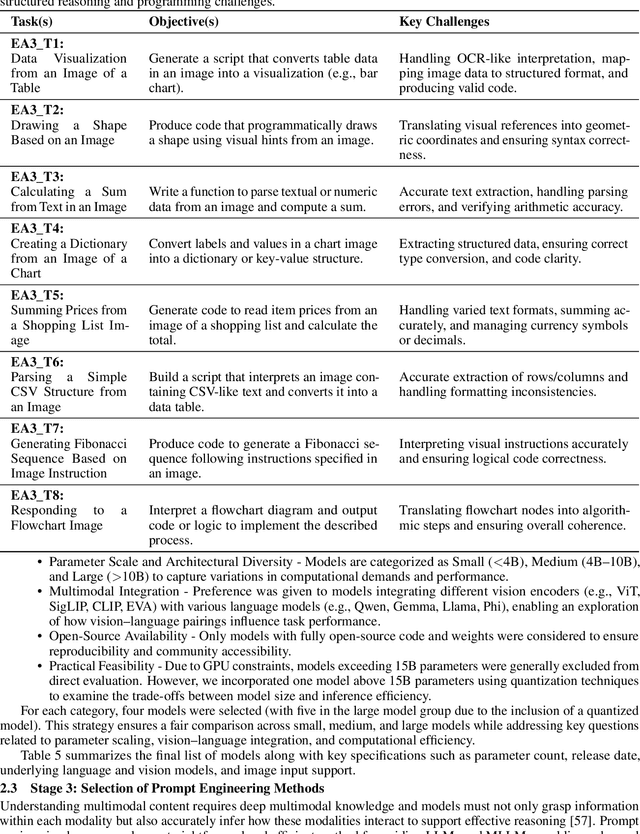
Multimodal Large Language Models (MLLMs) are set to transform how machines process and generate human-like responses by integrating diverse modalities such as text, images, and code. Yet, effectively harnessing their capabilities hinges on optimal prompt engineering. We present a comprehensive experimental evaluation of seven prompt engineering methods applied to 13 open-source MLLMs over 24 tasks spanning Reasoning and Compositionality, Multimodal Understanding and Alignment, Complex Code Generation and Execution, and Knowledge Retrieval and Integration. Our approach stratifies models by parameter count into Small (<4B), Medium (4B-10B), and Large (>10B) categories and compares prompting techniques including Zero-Shot, One-Shot, Few-Shot, Chain-of-Thought, Analogical, Generated Knowledge, and Tree-of-Thought. While Large MLLMs excel in structured tasks such as code generation, achieving accuracies up to 96.88% under Few-Shot prompting, all models struggle with complex reasoning and abstract understanding, often yielding accuracies below 60% and high hallucination rates. Structured reasoning prompts frequently increased hallucination up to 75% in small models and led to longer response times (over 20 seconds in Large MLLMs), while simpler prompting methods provided more concise and efficient outputs. No single prompting method uniformly optimises all task types. Instead, adaptive strategies combining example-based guidance with selective structured reasoning are essential to enhance robustness, efficiency, and factual accuracy. Our findings offer practical recommendations for prompt engineering and support more reliable deployment of MLLMs across applications including AI-assisted coding, knowledge retrieval, and multimodal content understanding.
The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities
Aug 23, 2024



This report examines the fine-tuning of Large Language Models (LLMs), integrating theoretical insights with practical applications. It outlines the historical evolution of LLMs from traditional Natural Language Processing (NLP) models to their pivotal role in AI. A comparison of fine-tuning methodologies, including supervised, unsupervised, and instruction-based approaches, highlights their applicability to different tasks. The report introduces a structured seven-stage pipeline for fine-tuning LLMs, spanning data preparation, model initialization, hyperparameter tuning, and model deployment. Emphasis is placed on managing imbalanced datasets and optimization techniques. Parameter-efficient methods like Low-Rank Adaptation (LoRA) and Half Fine-Tuning are explored for balancing computational efficiency with performance. Advanced techniques such as memory fine-tuning, Mixture of Experts (MoE), and Mixture of Agents (MoA) are discussed for leveraging specialized networks and multi-agent collaboration. The report also examines novel approaches like Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO), which align LLMs with human preferences, alongside pruning and routing optimizations to improve efficiency. Further sections cover validation frameworks, post-deployment monitoring, and inference optimization, with attention to deploying LLMs on distributed and cloud-based platforms. Emerging areas such as multimodal LLMs, fine-tuning for audio and speech, and challenges related to scalability, privacy, and accountability are also addressed. This report offers actionable insights for researchers and practitioners navigating LLM fine-tuning in an evolving landscape.
Building Trust in Conversational AI: A Comprehensive Review and Solution Architecture for Explainable, Privacy-Aware Systems using LLMs and Knowledge Graph
Aug 13, 2023Conversational AI systems have emerged as key enablers of human-like interactions across diverse sectors. Nevertheless, the balance between linguistic nuance and factual accuracy has proven elusive. In this paper, we first introduce LLMXplorer, a comprehensive tool that provides an in-depth review of over 150 Large Language Models (LLMs), elucidating their myriad implications ranging from social and ethical to regulatory, as well as their applicability across industries. Building on this foundation, we propose a novel functional architecture that seamlessly integrates the structured dynamics of Knowledge Graphs with the linguistic capabilities of LLMs. Validated using real-world AI news data, our architecture adeptly blends linguistic sophistication with factual rigour and further strengthens data security through Role-Based Access Control. This research provides insights into the evolving landscape of conversational AI, emphasizing the imperative for systems that are efficient, transparent, and trustworthy.