 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA model-based framework for learning transparent swarm behaviors
Mar 09, 2021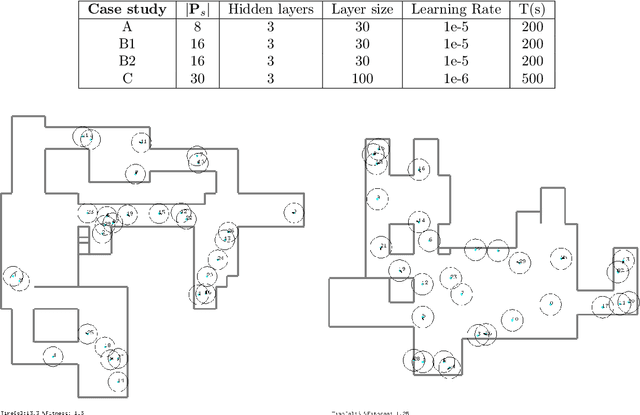
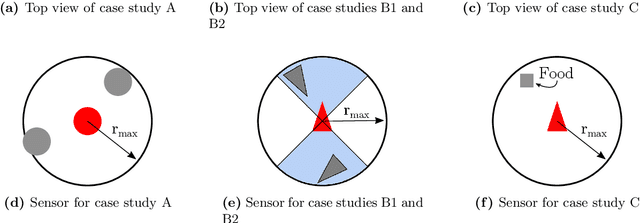
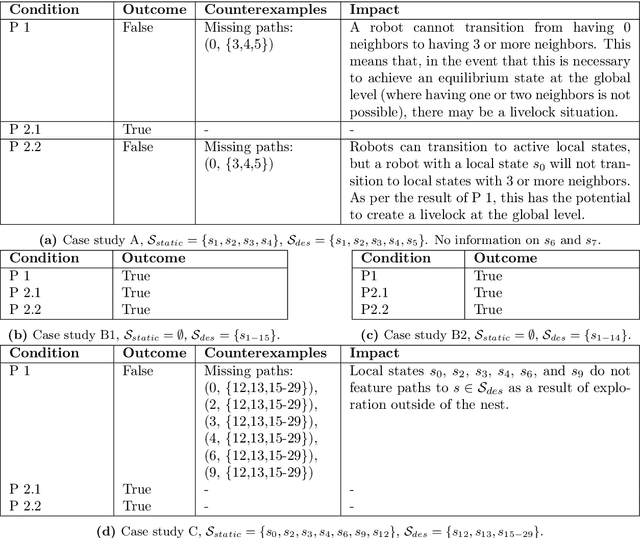
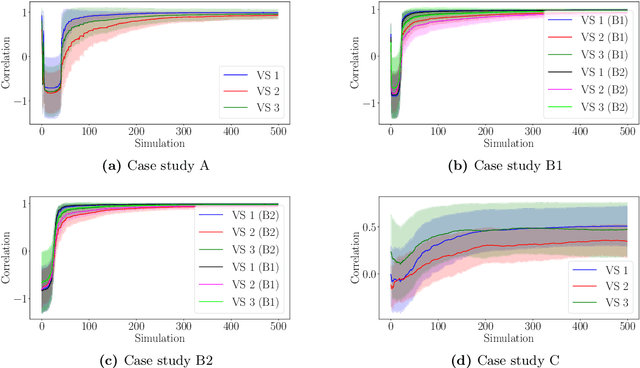
This paper proposes a model-based framework to automatically and efficiently design understandable and verifiable behaviors for swarms of robots. The framework is based on the automatic extraction of two distinct models: 1) a neural network model trained to estimate the relationship between the robots' sensor readings and the global performance of the swarm, and 2) a probabilistic state transition model that explicitly models the local state transitions (i.e., transitions in observations from the perspective of a single robot in the swarm) given a policy. The models can be trained from a data set of simulated runs featuring random policies. The first model is used to automatically extract a set of local states that are expected to maximize the global performance. These local states are referred to as desired local states. The second model is used to optimize a stochastic policy so as to increase the probability that the robots in the swarm observe one of the desired local states. Following these steps, the framework proposed in this paper can efficiently lead to effective controllers. This is tested on four case studies, featuring aggregation and foraging tasks. Importantly, thanks to the models, the framework allows us to understand and inspect a swarm's behavior. To this end, we propose verification checks to identify some potential issues that may prevent the swarm from achieving the desired global objective. In addition, we explore how the framework can be used in combination with a "standard" evolutionary robotics strategy (i.e., where performance is measured via simulation), or with online learning.
MAMBPO: Sample-efficient multi-robot reinforcement learning using learned world models
Mar 05, 2021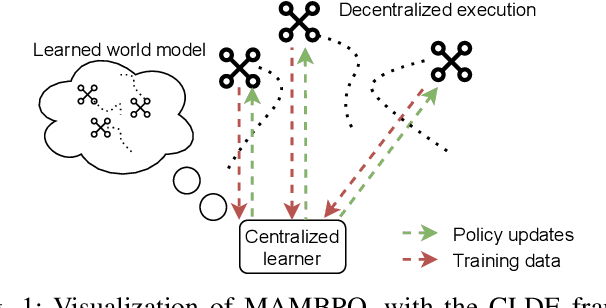
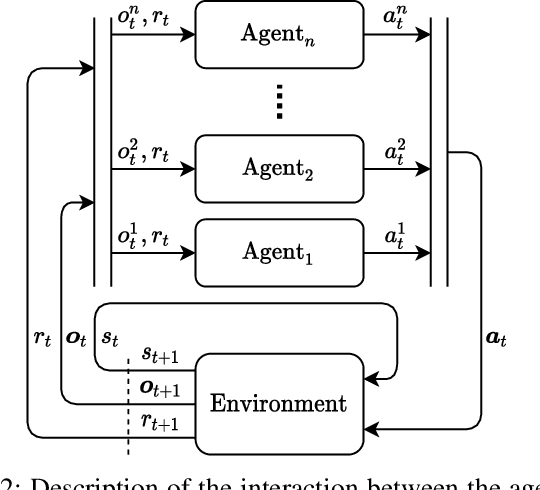
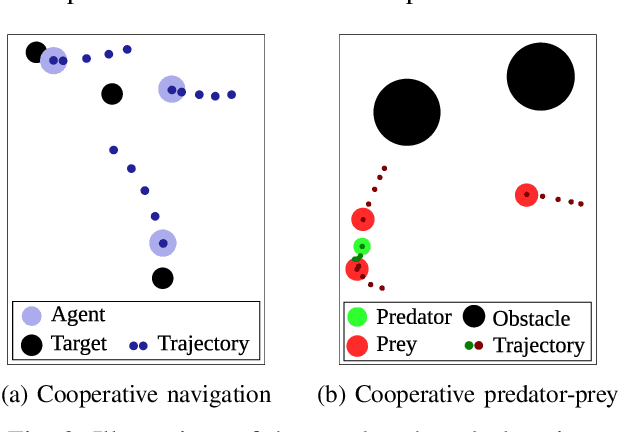
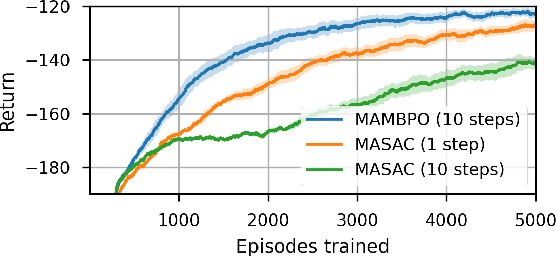
Multi-robot systems can benefit from reinforcement learning (RL) algorithms that learn behaviours in a small number of trials, a property known as sample efficiency. This research thus investigates the use of learned world models to improve sample efficiency. We present a novel multi-agent model-based RL algorithm: Multi-Agent Model-Based Policy Optimization (MAMBPO), utilizing the Centralized Learning for Decentralized Execution (CLDE) framework. CLDE algorithms allow a group of agents to act in a fully decentralized manner after training. This is a desirable property for many systems comprising of multiple robots. MAMBPO uses a learned world model to improve sample efficiency compared to model-free Multi-Agent Soft Actor-Critic (MASAC). We demonstrate this on two simulated multi-robot tasks, where MAMBPO achieves a similar performance to MASAC, but requires far fewer samples to do so. Through this, we take an important step towards making real-life learning for multi-robot systems possible.
An autonomous swarm of micro flying robots with range-based relative localization
Mar 12, 2020
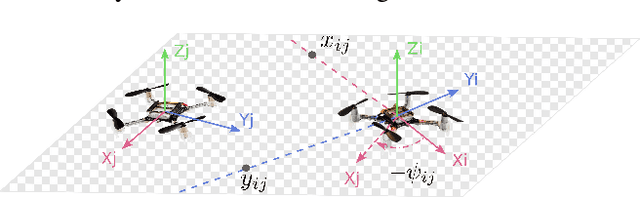
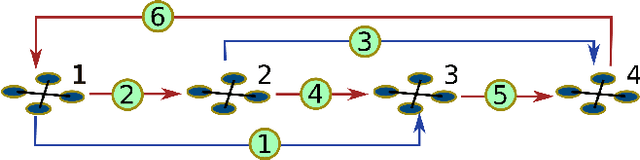
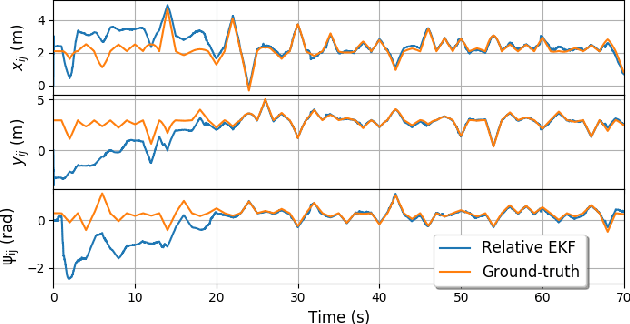
Accurate relative localization is an important requirement for a swarm of robots, especially when performing a cooperative task. This paper presents an autonomous multi-robot system equipped with a fully onboard range-based relative positioning system. It uses onboard sensing of velocity, yaw rate, and height as inputs, and then estimates the relative position of other robots in its own body frame by fusing these quantities with ranging measurements obtained from onboard ultra wide-band (UWB) antennas. Simulations concisely show the high precision, efficiency, and stability of the proposed localization method. Experiments are conducted on a team of 5 Crazyflie 2.0 quadrotors, demonstrating autonomous formation flight and pattern formation, and coordinated flight through a window. All results indicate the effectiveness of the proposed relative positioning method for multi-robot systems.
On-board Range-based Relative Localization for Micro Aerial Vehicles in indoor Leader-Follower Flight
May 18, 2018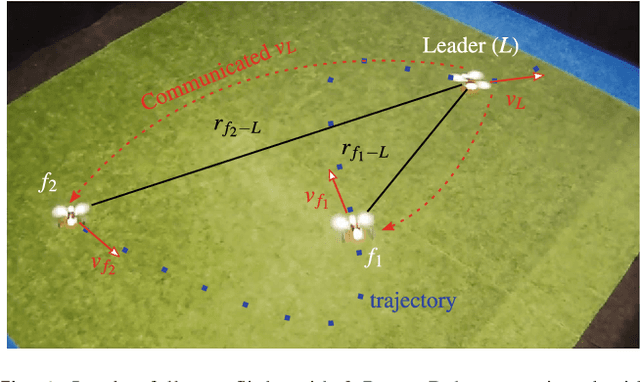

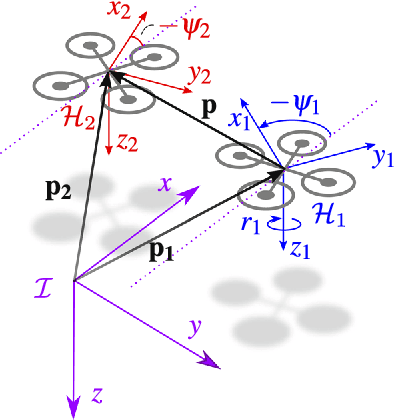

We present a range-based solution for indoor relative localization by Micro Air Vehicles (MAVs), achieving sufficient accuracy for leader-follower flight. Moving forward from previous work, we removed the dependency on a common heading measurement by the MAVs, making the relative localization accuracy independent of magnetometer readings. We found that this restricts the relative maneuvers that guarantee observability, and also that higher accuracy range measurements are required to rectify the missing heading information, yet both disadvantages can be tackled. Our implementation uses Ultra Wide Band, for both range measurements between MAVs and sharing their velocities, accelerations, yaw rates, and height with each other. We used this on real MAVs and performed leader-follower flight in an indoor environment. The follower MAVs could follow the leader MAV in close proximity for the entire durations of the flights. The followers were autonomous and used only on-board sensors to track and follow the leader.
Provable Emergent Pattern Formation by a Swarm of Anonymous, Homogeneous, Non-Communicating, Reactive Robots with Limited Relative Sensing and no Global Knowledge or Positioning
Apr 18, 2018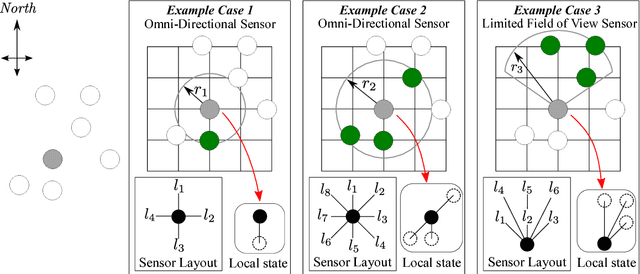
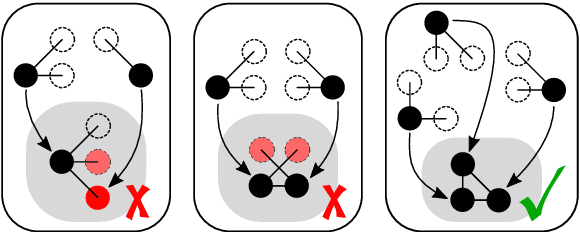
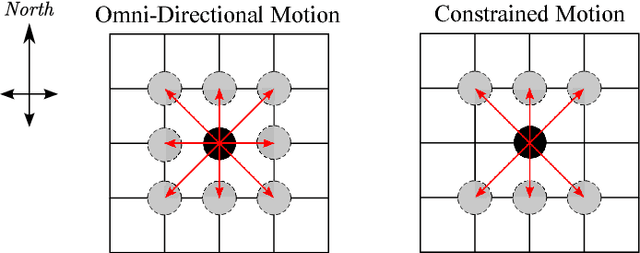
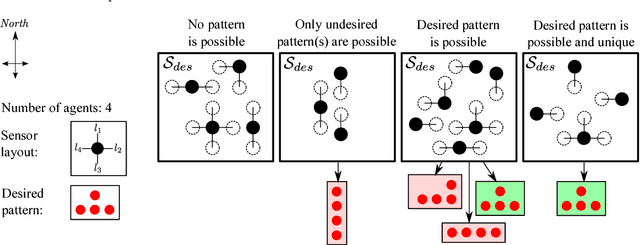
In this work, we explore emergent behaviors by swarms of anonymous, homogeneous, non-communicating, reactive robots that do not know their global position and have limited relative sensing. We introduce a novel method that enables such severely limited robots to autonomously arrange in a desired pattern and maintain it. The method includes an automatic proof procedure to check whether a given pattern will be achieved by the swarm from any initial configuration. An attractive feature of this proof procedure is that it is local in nature, avoiding as much as possible the computational explosion that can be expected with increasing robots, states, and action possibilities. Our approach is based on extracting the local states that constitute a global goal (in this case, a pattern). We then formally show that these local states can only coexist when the global desired pattern is achieved and that, until this occurs, there is always a sequence of actions that will lead from the current pattern to the desired pattern. Furthermore, we show that the agents will never perform actions that could a) lead to intra-swarm collisions or b) cause the swarm to separate. After an analysis of the performance of pattern formation in the discrete domain, we also test the system in continuous time and space simulations and reproduce the results using asynchronous agents operating in unbounded space. The agents successfully form the desired patterns while avoiding collisions and separation.
On-board Communication-based Relative Localization for Collision Avoidance in Micro Air Vehicle teams
Mar 08, 2017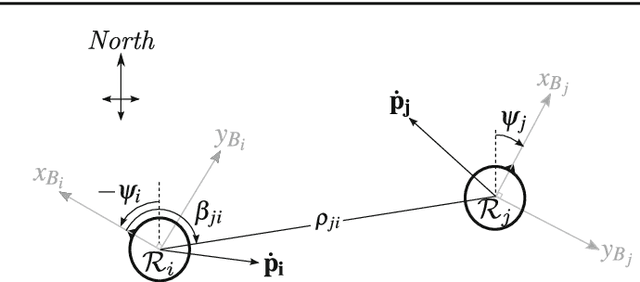
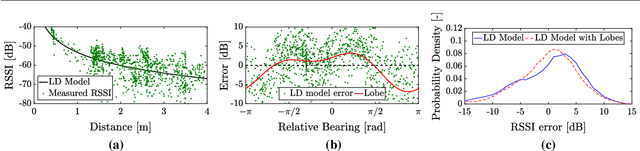
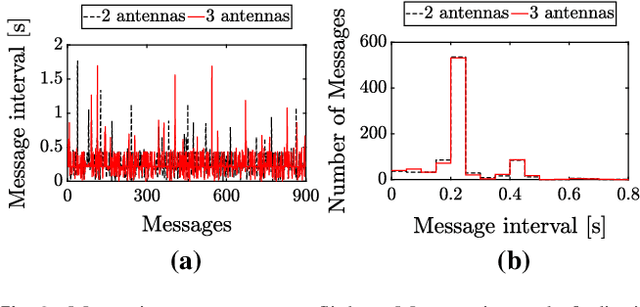
Micro Air Vehicles (MAVs) will unlock their true potential once they can operate in groups. To this end, it is essential for them to estimate on-board the relative location of their neighbors. The challenge lies in limiting the mass and processing burden needed to enable this. We developed a relative localization method that only requires the MAVs to communicate via their wireless transceiver. Communication allows the exchange of on-board states (velocity, height, and orientation), while the signal-strength provides range data. These quantities are fused to provide a full relative location estimate. We used our method to tackle the problem of collision avoidance in tight areas. The system was tested with a team of AR.Drones flying in a 4mx4m area and with miniature drones of ~50g in a 2mx2m area. The MAVs were able to track their relative positions and fly several minutes without collisions. Our implementation used Bluetooth to communicate between the drones. This featured significant noise and disturbances in signal-strength, which worsened as more drones were added. Simulation analysis suggests that results can improve with a more suitable transceiver module.