 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning A Unified 3D Point Cloud for View Synthesis
Sep 12, 2022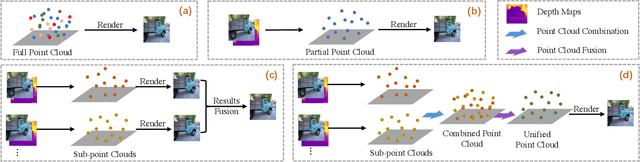


3D point cloud representation-based view synthesis methods have demonstrated effectiveness. However, existing methods usually synthesize novel views only from a single source view, and it is non-trivial to generalize them to handle multiple source views for pursuing higher reconstruction quality. In this paper, we propose a new deep learning-based view synthesis paradigm, which learns a unified 3D point cloud from different source views. Specifically, we first construct sub-point clouds by projecting source views to 3D space based on their depth maps. Then, we learn the unified 3D point cloud by adaptively fusing points at a local neighborhood defined on the union of the sub-point clouds. Besides, we also propose a 3D geometry-guided image restoration module to fill the holes and recover high-frequency details of the rendered novel views. Experimental results on three benchmark datasets demonstrate that our method outperforms state-of-the-art view synthesis methods to a large extent both quantitatively and visually.
Content-aware Warping for View Synthesis
Jan 22, 2022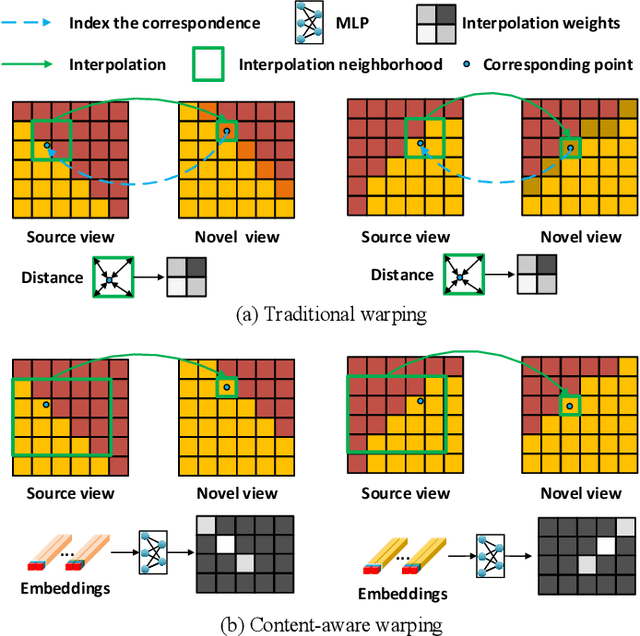
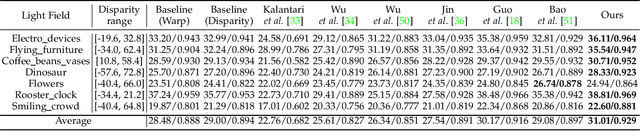


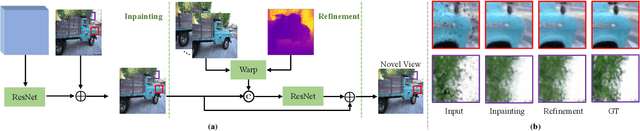
Existing image-based rendering methods usually adopt depth-based image warping operation to synthesize novel views. In this paper, we reason the essential limitations of the traditional warping operation to be the limited neighborhood and only distance-based interpolation weights. To this end, we propose content-aware warping, which adaptively learns the interpolation weights for pixels of a relatively large neighborhood from their contextual information via a lightweight neural network. Based on this learnable warping module, we propose a new end-to-end learning-based framework for novel view synthesis from two input source views, in which two additional modules, namely confidence-based blending and feature-assistant spatial refinement, are naturally proposed to handle the occlusion issue and capture the spatial correlation among pixels of the synthesized view, respectively. Besides, we also propose a weight-smoothness loss term to regularize the network. Experimental results on structured light field datasets with wide baselines and unstructured multi-view datasets show that the proposed method significantly outperforms state-of-the-art methods both quantitatively and visually. The source code will be publicly available at https://github.com/MantangGuo/CW4VS.
Learning Dynamic Interpolation for Extremely Sparse Light Fields with Wide Baselines
Aug 18, 2021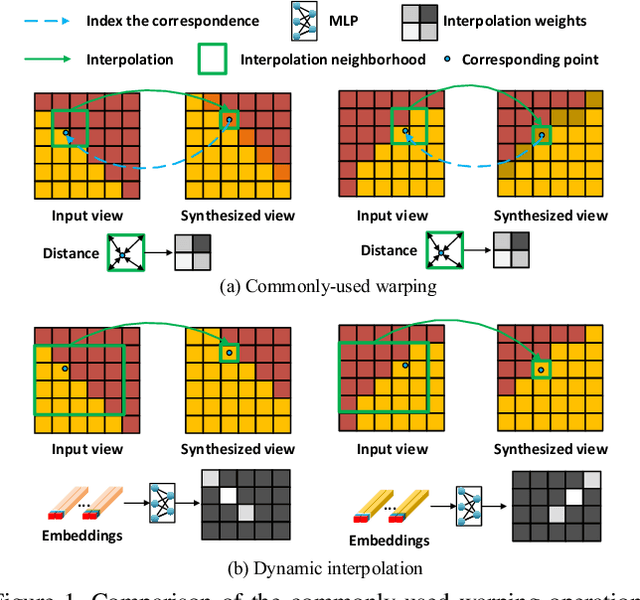
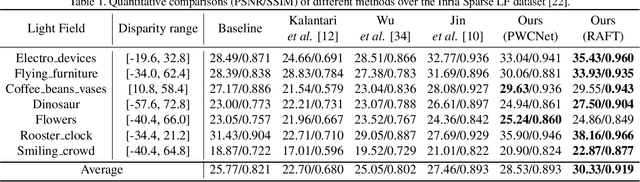
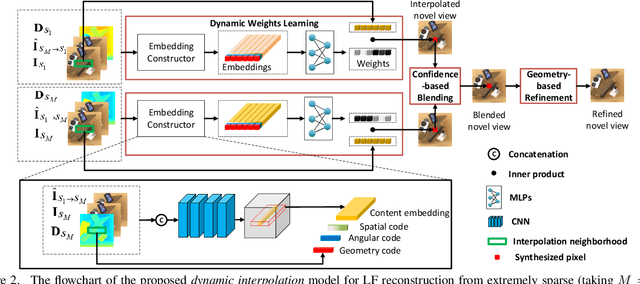
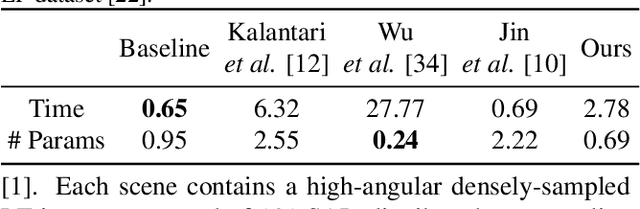
In this paper, we tackle the problem of dense light field (LF) reconstruction from sparsely-sampled ones with wide baselines and propose a learnable model, namely dynamic interpolation, to replace the commonly-used geometry warping operation. Specifically, with the estimated geometric relation between input views, we first construct a lightweight neural network to dynamically learn weights for interpolating neighbouring pixels from input views to synthesize each pixel of novel views independently. In contrast to the fixed and content-independent weights employed in the geometry warping operation, the learned interpolation weights implicitly incorporate the correspondences between the source and novel views and adapt to different image content information. Then, we recover the spatial correlation between the independently synthesized pixels of each novel view by referring to that of input views using a geometry-based spatial refinement module. We also constrain the angular correlation between the novel views through a disparity-oriented LF structure loss. Experimental results on LF datasets with wide baselines show that the reconstructed LFs achieve much higher PSNR/SSIM and preserve the LF parallax structure better than state-of-the-art methods. The source code is publicly available at https://github.com/MantangGuo/DI4SLF.
Breaking the Spatio-Angular Trade-off for Light Field Super-Resolution via LSTM Modelling on Epipolar Plane Images
Feb 15, 2019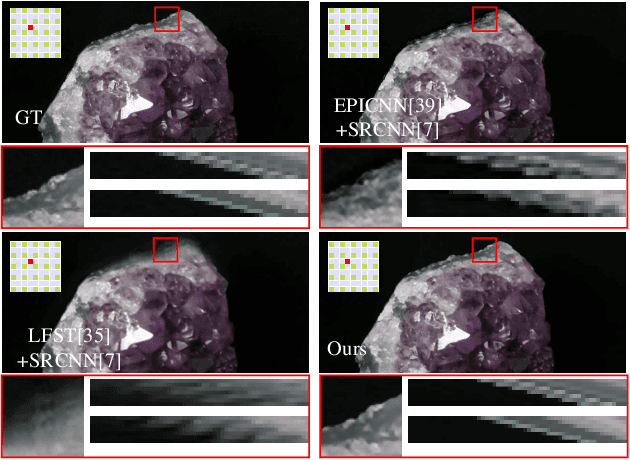
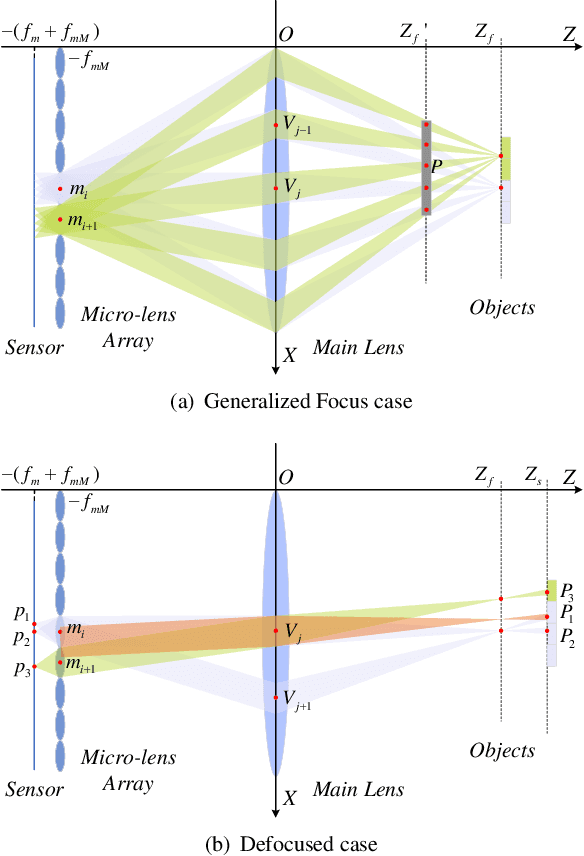

Light-field cameras (LFC) have received increasing attention due to their wide-spread applications. However, current LFCs suffer from the well-known spatio-angular trade-off, which is considered as an inherent and fundamental limit for LFC designs. In this paper, by doing a detailed geometrical optical analysis of the sampling process in an LFC, we show that the effective sampling resolution is generally higher than the number of micro-lenses. This contribution makes it theoretically possible to break the resolution trade-off. Our second contribution is an epipolar plane image (EPI) based super-resolution method, which can super-resolve the spatial and angular dimensions simultaneously. We prove that the light field is a 2D series, thus, a specifically designed CNN-LSTM network is proposed to capture the continuity property of the EPI. Rather than leveraging semantic information, our network focuses on extracting geometric continuity in the EPI. This gives our method an improved generalization ability and makes it applicable to a wide range of previously unseen scenes. Experiments on both synthetic and real light fields demonstrate the improvements over state-of-the-art, especially in large disparity areas.
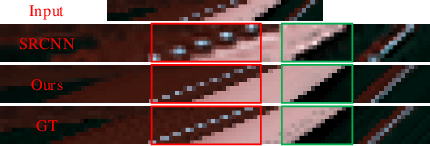
Dense Light Field Reconstruction From Sparse Sampling Using Residual Network
Aug 11, 2018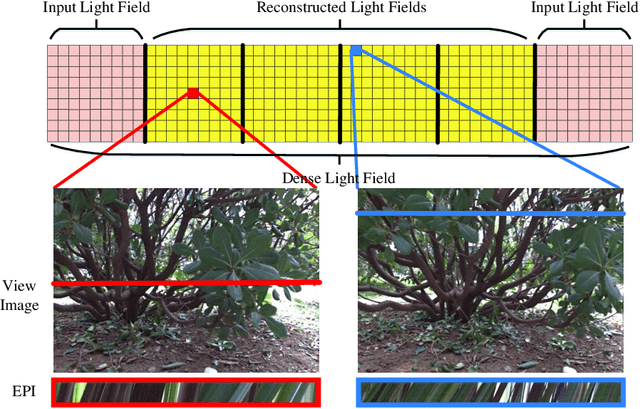
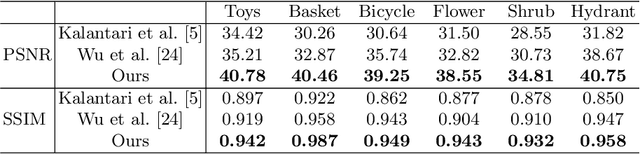
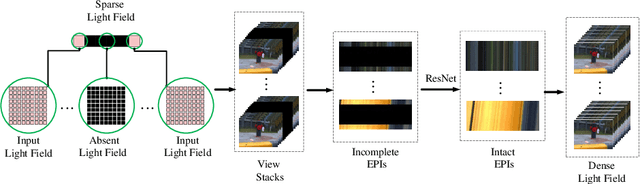
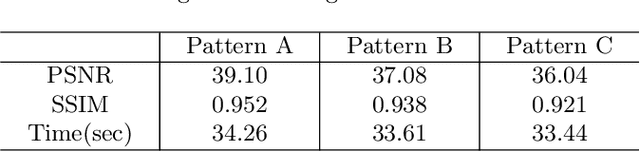
A light field records numerous light rays from a real-world scene. However, capturing a dense light field by existing devices is a time-consuming process. Besides, reconstructing a large amount of light rays equivalent to multiple light fields using sparse sampling arises a severe challenge for existing methods. In this paper, we present a learning based method to reconstruct multiple novel light fields between two mutually independent light fields. We indicate that light rays distributed in different light fields have the same consistent constraints under a certain condition. The most significant constraint is a depth related correlation between angular and spatial dimensions. Our method avoids working out the error-sensitive constraint by employing a deep neural network. We solve residual values of pixels on epipolar plane image (EPI) to reconstruct novel light fields. Our method is able to reconstruct 2 to 4 novel light fields between two mutually independent input light fields. We also compare our results with those yielded by a number of alternatives elsewhere in the literature, which shows our reconstructed light fields have better structure similarity and occlusion relationship.