 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVS-Solver: Video Diffusion Model as Zero-Shot Novel View Synthesizer
May 24, 2024By harnessing the potent generative capabilities of pre-trained large video diffusion models, we propose NVS-Solver, a new novel view synthesis (NVS) paradigm that operates \textit{without} the need for training. NVS-Solver adaptively modulates the diffusion sampling process with the given views to enable the creation of remarkable visual experiences from single or multiple views of static scenes or monocular videos of dynamic scenes. Specifically, built upon our theoretical modeling, we iteratively modulate the score function with the given scene priors represented with warped input views to control the video diffusion process. Moreover, by theoretically exploring the boundary of the estimation error, we achieve the modulation in an adaptive fashion according to the view pose and the number of diffusion steps. Extensive evaluations on both static and dynamic scenes substantiate the significant superiority of our NVS-Solver over state-of-the-art methods both quantitatively and qualitatively. \textit{ Source code in } \href{https://github.com/ZHU-Zhiyu/NVS_Solver}{https://github.com/ZHU-Zhiyu/NVS$\_$Solver}.
Decoupling Dynamic Monocular Videos for Dynamic View Synthesis
Apr 04, 2023

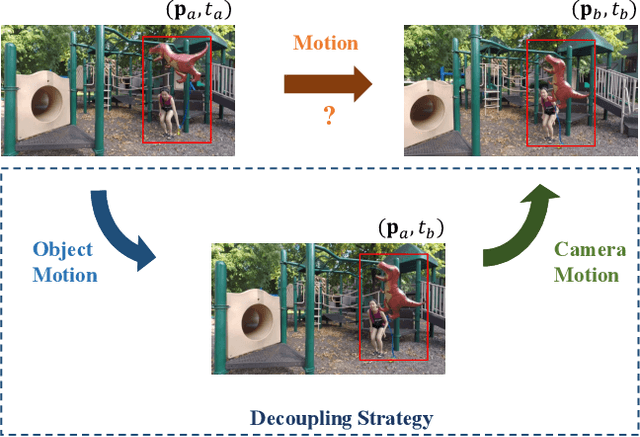
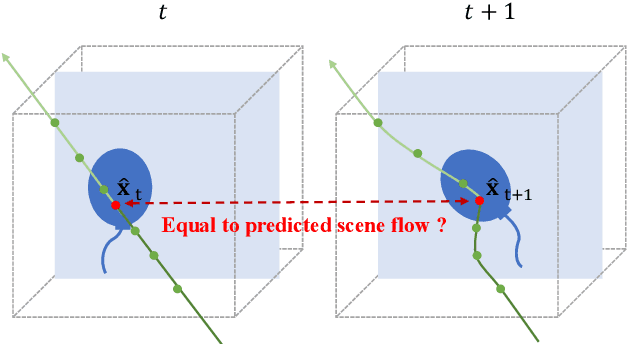
The challenge of dynamic view synthesis from dynamic monocular videos, i.e., synthesizing novel views for free viewpoints given a monocular video of a dynamic scene captured by a moving camera, mainly lies in accurately modeling the dynamic objects of a scene using limited 2D frames, each with a varying timestamp and viewpoint. Existing methods usually require pre-processed 2D optical flow and depth maps by additional methods to supervise the network, making them suffer from the inaccuracy of the pre-processed supervision and the ambiguity when lifting the 2D information to 3D. In this paper, we tackle this challenge in an unsupervised fashion. Specifically, we decouple the motion of the dynamic objects into object motion and camera motion, respectively regularized by proposed unsupervised surface consistency and patch-based multi-view constraints. The former enforces the 3D geometric surfaces of moving objects to be consistent over time, while the latter regularizes their appearances to be consistent across different viewpoints. Such a fine-grained motion formulation can alleviate the learning difficulty for the network, thus enabling it to produce not only novel views with higher quality but also more accurate scene flows and depth than existing methods requiring extra supervision. We will make the code publicly available.
Learning A Unified 3D Point Cloud for View Synthesis
Sep 12, 2022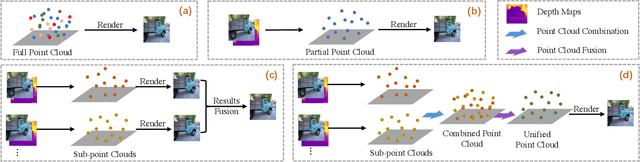


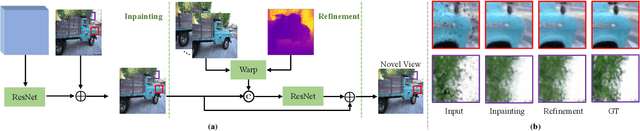
3D point cloud representation-based view synthesis methods have demonstrated effectiveness. However, existing methods usually synthesize novel views only from a single source view, and it is non-trivial to generalize them to handle multiple source views for pursuing higher reconstruction quality. In this paper, we propose a new deep learning-based view synthesis paradigm, which learns a unified 3D point cloud from different source views. Specifically, we first construct sub-point clouds by projecting source views to 3D space based on their depth maps. Then, we learn the unified 3D point cloud by adaptively fusing points at a local neighborhood defined on the union of the sub-point clouds. Besides, we also propose a 3D geometry-guided image restoration module to fill the holes and recover high-frequency details of the rendered novel views. Experimental results on three benchmark datasets demonstrate that our method outperforms state-of-the-art view synthesis methods to a large extent both quantitatively and visually.