 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Underwater Imaging with 4-D Light Fields: Dataset and Method
Aug 30, 2024In this paper, we delve into the realm of 4-D light fields (LFs) to enhance underwater imaging plagued by light absorption, scattering, and other challenges. Contrasting with conventional 2-D RGB imaging, 4-D LF imaging excels in capturing scenes from multiple perspectives, thereby indirectly embedding geometric information. This intrinsic property is anticipated to effectively address the challenges associated with underwater imaging. By leveraging both explicit and implicit depth cues present in 4-D LF images, we propose a progressive, mutually reinforcing framework for underwater 4-D LF image enhancement and depth estimation. Specifically, our framework explicitly utilizes estimated depth information alongside implicit depth-related dynamic convolutional kernels to modulate output features. The entire framework decomposes this complex task, iteratively optimizing the enhanced image and depth information to progressively achieve optimal enhancement results. More importantly, we construct the first 4-D LF-based underwater image dataset for quantitative evaluation and supervised training of learning-based methods, comprising 75 underwater scenes and 3675 high-resolution 2K pairs. To craft vibrant and varied underwater scenes, we build underwater environments with various objects and adopt several types of degradation. Through extensive experimentation, we showcase the potential and superiority of 4-D LF-based underwater imaging vis-a-vis traditional 2-D RGB-based approaches. Moreover, our method effectively corrects color bias and achieves state-of-the-art performance. The dataset and code will be publicly available at https://github.com/linlos1234/LFUIE.
RainyScape: Unsupervised Rainy Scene Reconstruction using Decoupled Neural Rendering
Apr 17, 2024



We propose RainyScape, an unsupervised framework for reconstructing clean scenes from a collection of multi-view rainy images. RainyScape consists of two main modules: a neural rendering module and a rain-prediction module that incorporates a predictor network and a learnable latent embedding that captures the rain characteristics of the scene. Specifically, based on the spectral bias property of neural networks, we first optimize the neural rendering pipeline to obtain a low-frequency scene representation. Subsequently, we jointly optimize the two modules, driven by the proposed adaptive direction-sensitive gradient-based reconstruction loss, which encourages the network to distinguish between scene details and rain streaks, facilitating the propagation of gradients to the relevant components. Extensive experiments on both the classic neural radiance field and the recently proposed 3D Gaussian splatting demonstrate the superiority of our method in effectively eliminating rain streaks and rendering clean images, achieving state-of-the-art performance. The constructed high-quality dataset and source code will be publicly available.
Enhancing Low-light Light Field Images with A Deep Compensation Unfolding Network
Aug 10, 2023



This paper presents a novel and interpretable end-to-end learning framework, called the deep compensation unfolding network (DCUNet), for restoring light field (LF) images captured under low-light conditions. DCUNet is designed with a multi-stage architecture that mimics the optimization process of solving an inverse imaging problem in a data-driven fashion. The framework uses the intermediate enhanced result to estimate the illumination map, which is then employed in the unfolding process to produce a new enhanced result. Additionally, DCUNet includes a content-associated deep compensation module at each optimization stage to suppress noise and illumination map estimation errors. To properly mine and leverage the unique characteristics of LF images, this paper proposes a pseudo-explicit feature interaction module that comprehensively exploits redundant information in LF images. The experimental results on both simulated and real datasets demonstrate the superiority of our DCUNet over state-of-the-art methods, both qualitatively and quantitatively. Moreover, DCUNet preserves the essential geometric structure of enhanced LF images much better. The code will be publicly available at https://github.com/lyuxianqiang/LFLL-DCU.
Probabilistic-based Feature Embedding of 4-D Light Fields for Compressive Imaging and Denoising
Jun 15, 2023The high-dimensional nature of the 4-D light field (LF) poses great challenges in efficient and effective feature embedding that severely impact the performance of downstream tasks. To tackle this crucial issue, in contrast to existing methods with empirically-designed architectures, we propose probabilistic-based feature embedding (PFE), which learns a feature embedding architecture by assembling various low-dimensional convolution patterns in a probability space for fully capturing spatial-angular information. Building upon the proposed PFE, we then leverage the intrinsic linear imaging model of the coded aperture camera to construct a cycle-consistent 4-D LF reconstruction network from coded measurements. Moreover, we incorporate PFE into an iterative optimization framework for 4-D LF denoising. Our extensive experiments demonstrate the significant superiority of our methods on both real-world and synthetic 4-D LF images, both quantitatively and qualitatively, when compared with state-of-the-art methods. The source code will be publicly available at https://github.com/lyuxianqiang/LFCA-CR-NET.
Learning A Unified 3D Point Cloud for View Synthesis
Sep 12, 2022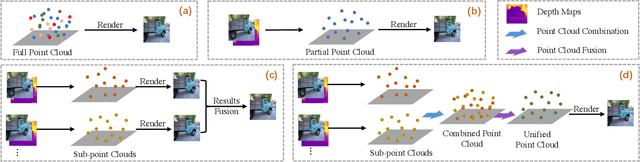


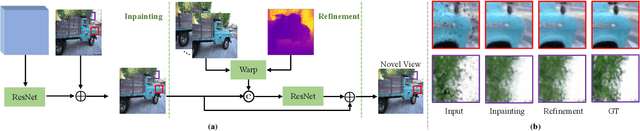
3D point cloud representation-based view synthesis methods have demonstrated effectiveness. However, existing methods usually synthesize novel views only from a single source view, and it is non-trivial to generalize them to handle multiple source views for pursuing higher reconstruction quality. In this paper, we propose a new deep learning-based view synthesis paradigm, which learns a unified 3D point cloud from different source views. Specifically, we first construct sub-point clouds by projecting source views to 3D space based on their depth maps. Then, we learn the unified 3D point cloud by adaptively fusing points at a local neighborhood defined on the union of the sub-point clouds. Besides, we also propose a 3D geometry-guided image restoration module to fill the holes and recover high-frequency details of the rendered novel views. Experimental results on three benchmark datasets demonstrate that our method outperforms state-of-the-art view synthesis methods to a large extent both quantitatively and visually.