 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Video Representation Learning with Cross-Stream Prototypical Contrasting
Jun 21, 2021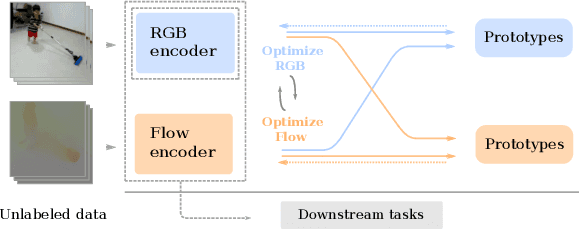
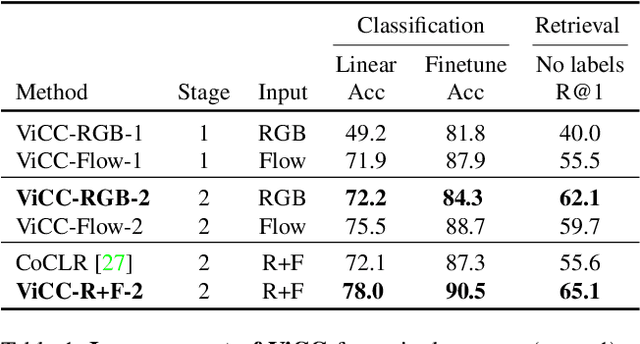
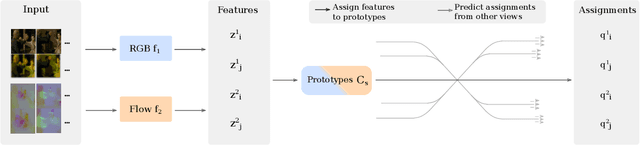
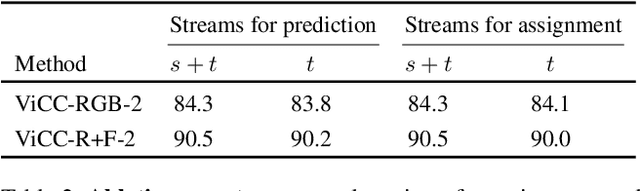
Instance-level contrastive learning techniques, which rely on data augmentation and a contrastive loss function, have found great success in the domain of visual representation learning. They are not suitable for exploiting the rich dynamical structure of video however, as operations are done on many augmented instances. In this paper we propose "Video Cross-Stream Prototypical Contrasting", a novel method which predicts consistent prototype assignments from both RGB and optical flow views, operating on sets of samples. Specifically, we alternate the optimization process; while optimizing one of the streams, all views are mapped to one set of stream prototype vectors. Each of the assignments is predicted with all views except the one matching the prediction, pushing representations closer to their assigned prototypes. As a result, more efficient video embeddings with ingrained motion information are learned, without the explicit need for optical flow computation during inference. We obtain state-of-the-art results on nearest neighbour video retrieval and action recognition, outperforming previous best by +3.2% on UCF101 using the S3D backbone (90.5% Top-1 acc), and by +7.2% on UCF101 and +15.1% on HMDB51 using the R(2+1)D backbone.
Mixing Consistent Deep Clustering
Nov 03, 2020
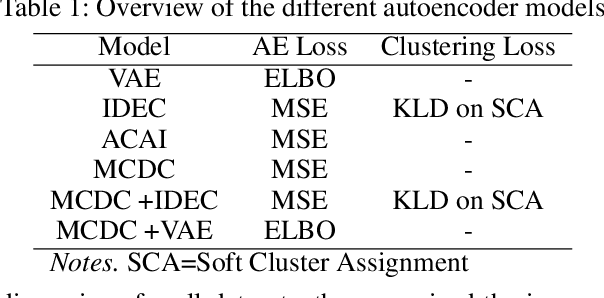
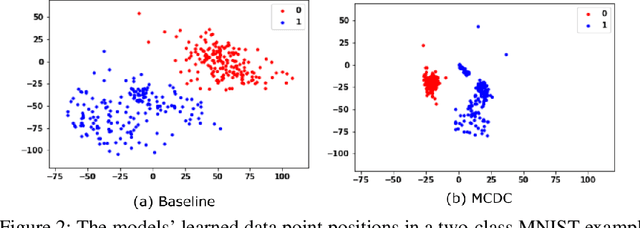
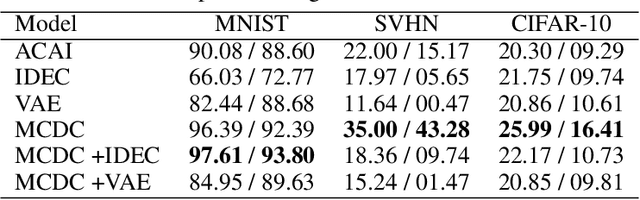
Finding well-defined clusters in data represents a fundamental challenge for many data-driven applications, and largely depends on good data representation. Drawing on literature regarding representation learning, studies suggest that one key characteristic of good latent representations is the ability to produce semantically mixed outputs when decoding linear interpolations of two latent representations. We propose the Mixing Consistent Deep Clustering method which encourages interpolations to appear realistic while adding the constraint that interpolations of two data points must look like one of the two inputs. By applying this training method to various clustering (non-)specific autoencoder models we found that using the proposed training method systematically changed the structure of learned representations of a model and it improved clustering performance for the tested ACAI, IDEC, and VAE models on the MNIST, SVHN, and CIFAR-10 datasets. These outcomes have practical implications for numerous real-world clustering tasks, as it shows that the proposed method can be added to existing autoencoders to further improve clustering performance.
FlipOut: Uncovering Redundant Weights via Sign Flipping
Sep 05, 2020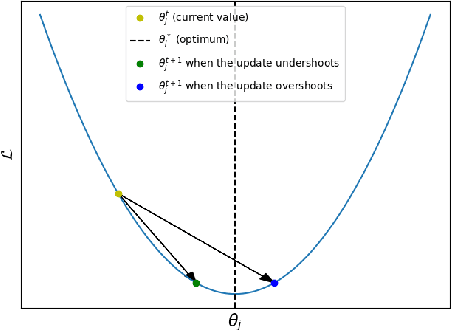

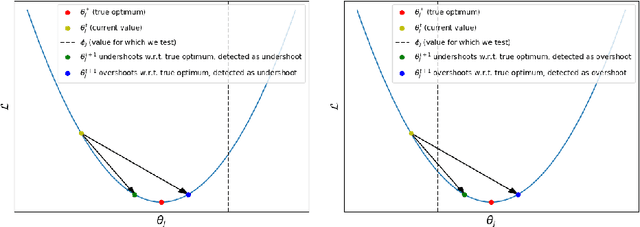
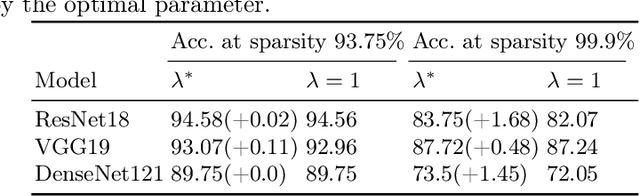
Modern neural networks, although achieving state-of-the-art results on many tasks, tend to have a large number of parameters, which increases training time and resource usage. This problem can be alleviated by pruning. Existing methods, however, often require extensive parameter tuning or multiple cycles of pruning and retraining to convergence in order to obtain a favorable accuracy-sparsity trade-off. To address these issues, we propose a novel pruning method which uses the oscillations around $0$ (i.e. sign flips) that a weight has undergone during training in order to determine its saliency. Our method can perform pruning before the network has converged, requires little tuning effort due to having good default values for its hyperparameters, and can directly target the level of sparsity desired by the user. Our experiments, performed on a variety of object classification architectures, show that it is competitive with existing methods and achieves state-of-the-art performance for levels of sparsity of $99.6\%$ and above for most of the architectures tested. For reproducibility, we release our code publicly at https://github.com/AndreiXYZ/flipout.
Super-resolution Variational Auto-Encoders
Jun 30, 2020

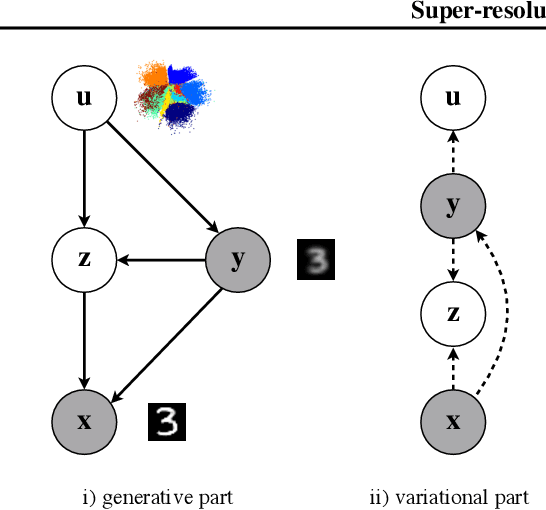
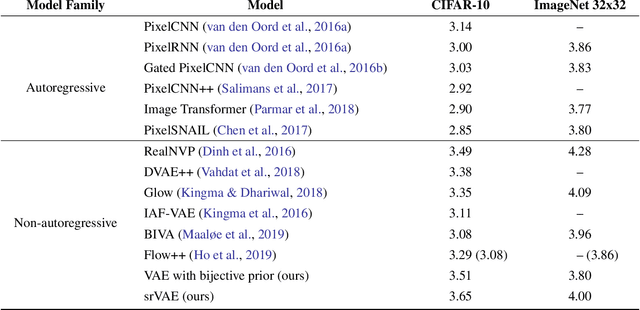
The framework of variational autoencoders (VAEs) provides a principled method for jointly learning latent-variable models and corresponding inference models. However, the main drawback of this approach is the blurriness of the generated images. Some studies link this effect to the objective function, namely, the (negative) log-likelihood. Here, we propose to enhance VAEs by adding a random variable that is a downscaled version of the original image and still use the log-likelihood function as the learning objective. Further, by providing the downscaled image as an input to the decoder, it can be used in a manner similar to the super-resolution. We present empirically that the proposed approach performs comparably to VAEs in terms of the negative log-likelihood, but it obtains a better FID score in data synthesis.
Pruning via Iterative Ranking of Sensitivity Statistics
Jun 14, 2020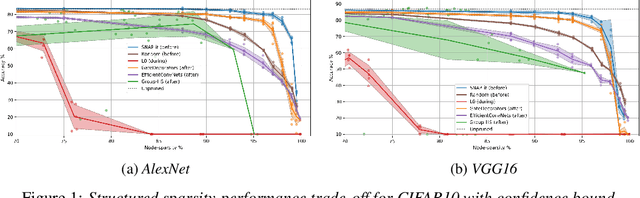
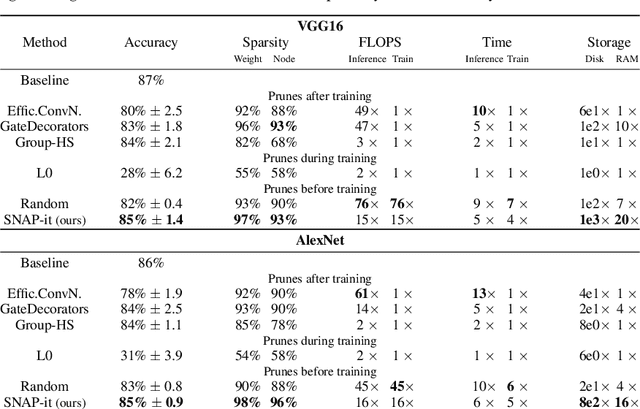
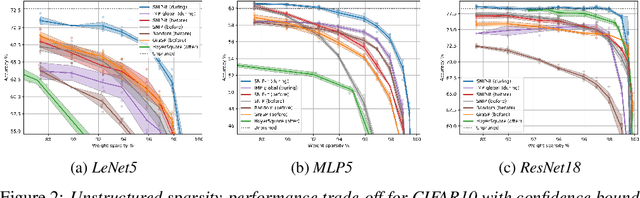
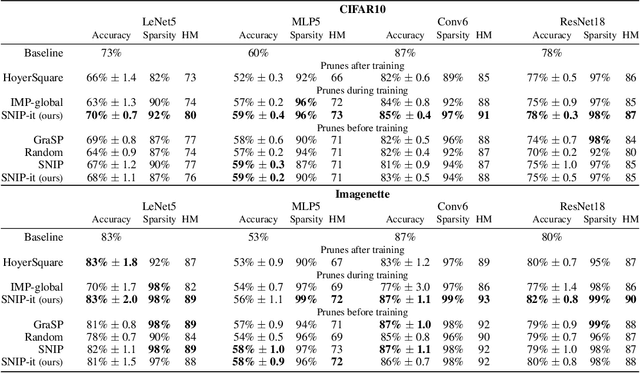
With the introduction of SNIP [arXiv:1810.02340v2], it has been demonstrated that modern neural networks can effectively be pruned before training. Yet, its sensitivity criterion has since been criticized for not propagating training signal properly or even disconnecting layers. As a remedy, GraSP [arXiv:2002.07376v1] was introduced, compromising on simplicity. However, in this work we show that by applying the sensitivity criterion iteratively in smaller steps - still before training - we can improve its performance without difficult implementation. As such, we introduce 'SNIP-it'. We then demonstrate how it can be applied for both structured and unstructured pruning, before and/or during training, therewith achieving state-of-the-art sparsity-performance trade-offs. That is, while already providing the computational benefits of pruning in the training process from the start. Furthermore, we evaluate our methods on robustness to overfitting, disconnection and adversarial attacks as well.