 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaT-PFN: A Joint Embedding Predictive Architecture for In-context Time-series Forecasting
May 16, 2024We introduce LatentTimePFN (LaT-PFN), a foundational Time Series model with a strong embedding space that enables zero-shot forecasting. To achieve this, we perform in-context learning in latent space utilizing a novel integration of the Prior-data Fitted Networks (PFN) and Joint Embedding Predictive Architecture (JEPA) frameworks. We leverage the JEPA framework to create a prediction-optimized latent representation of the underlying stochastic process that generates time series and combines it with contextual learning, using a PFN. Furthermore, we improve on preceding works by utilizing related time series as a context and introducing an abstract time axis. This drastically reduces training time and increases the versatility of the model by allowing any time granularity and forecast horizon. We show that this results in superior zero-shot predictions compared to established baselines. We also demonstrate our latent space produces informative embeddings of both individual time steps and fixed-length summaries of entire series. Finally, we observe the emergence of multi-step patch embeddings without explicit training, suggesting the model actively learns discrete tokens that encode local structures in the data, analogous to vision transformers.
Pruning via Iterative Ranking of Sensitivity Statistics
Jun 14, 2020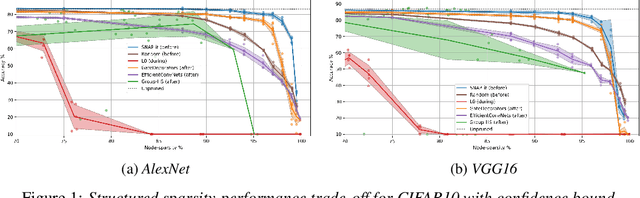
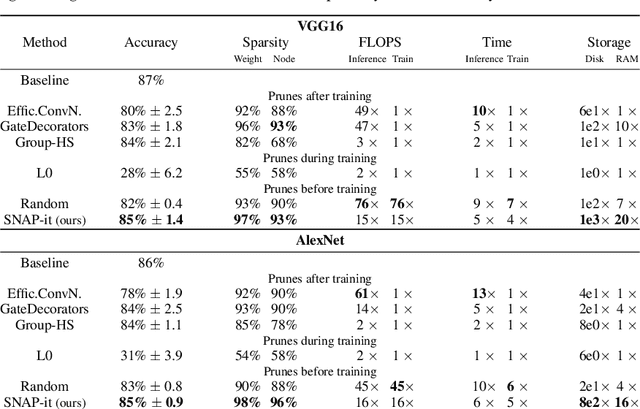
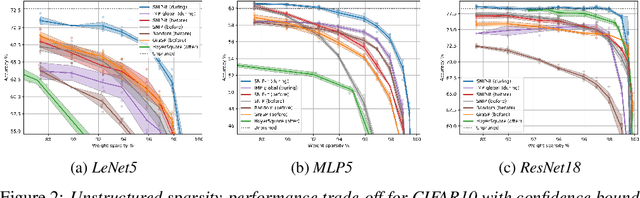
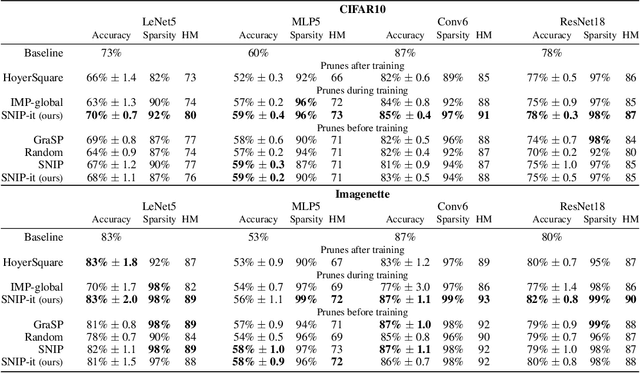
With the introduction of SNIP [arXiv:1810.02340v2], it has been demonstrated that modern neural networks can effectively be pruned before training. Yet, its sensitivity criterion has since been criticized for not propagating training signal properly or even disconnecting layers. As a remedy, GraSP [arXiv:2002.07376v1] was introduced, compromising on simplicity. However, in this work we show that by applying the sensitivity criterion iteratively in smaller steps - still before training - we can improve its performance without difficult implementation. As such, we introduce 'SNIP-it'. We then demonstrate how it can be applied for both structured and unstructured pruning, before and/or during training, therewith achieving state-of-the-art sparsity-performance trade-offs. That is, while already providing the computational benefits of pruning in the training process from the start. Furthermore, we evaluate our methods on robustness to overfitting, disconnection and adversarial attacks as well.