 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-resolution Variational Auto-Encoders
Paper and Code


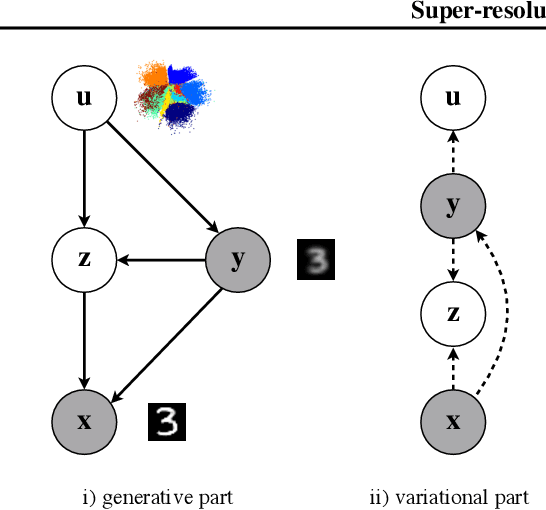
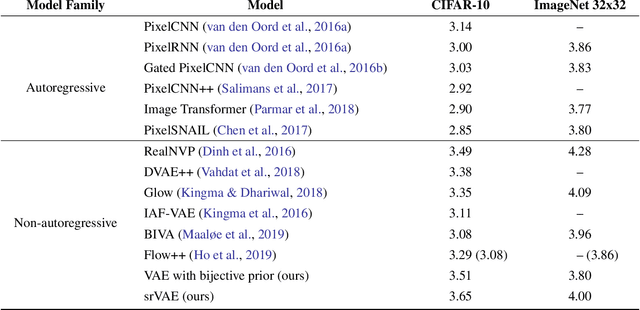
The framework of variational autoencoders (VAEs) provides a principled method for jointly learning latent-variable models and corresponding inference models. However, the main drawback of this approach is the blurriness of the generated images. Some studies link this effect to the objective function, namely, the (negative) log-likelihood. Here, we propose to enhance VAEs by adding a random variable that is a downscaled version of the original image and still use the log-likelihood function as the learning objective. Further, by providing the downscaled image as an input to the decoder, it can be used in a manner similar to the super-resolution. We present empirically that the proposed approach performs comparably to VAEs in terms of the negative log-likelihood, but it obtains a better FID score in data synthesis.