 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Video Representation Learning with Cross-Stream Prototypical Contrasting
Jun 21, 2021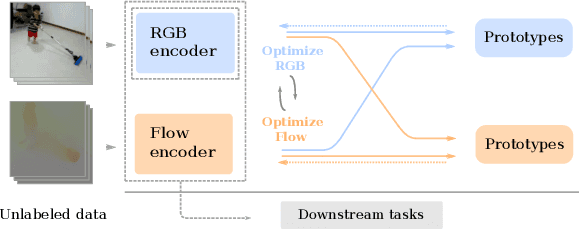
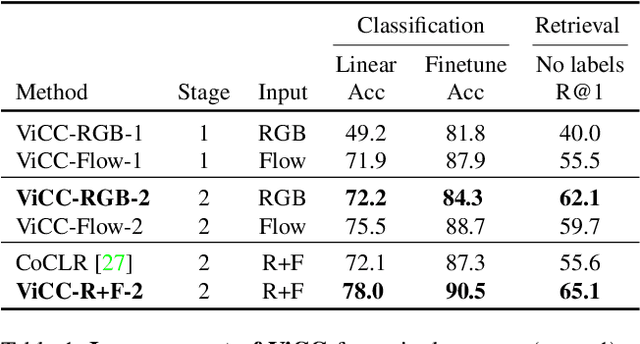
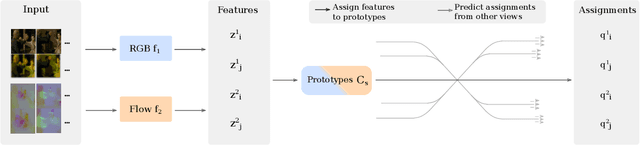
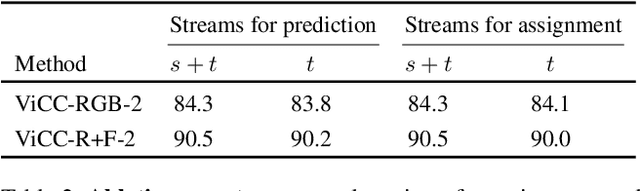
Instance-level contrastive learning techniques, which rely on data augmentation and a contrastive loss function, have found great success in the domain of visual representation learning. They are not suitable for exploiting the rich dynamical structure of video however, as operations are done on many augmented instances. In this paper we propose "Video Cross-Stream Prototypical Contrasting", a novel method which predicts consistent prototype assignments from both RGB and optical flow views, operating on sets of samples. Specifically, we alternate the optimization process; while optimizing one of the streams, all views are mapped to one set of stream prototype vectors. Each of the assignments is predicted with all views except the one matching the prediction, pushing representations closer to their assigned prototypes. As a result, more efficient video embeddings with ingrained motion information are learned, without the explicit need for optical flow computation during inference. We obtain state-of-the-art results on nearest neighbour video retrieval and action recognition, outperforming previous best by +3.2% on UCF101 using the S3D backbone (90.5% Top-1 acc), and by +7.2% on UCF101 and +15.1% on HMDB51 using the R(2+1)D backbone.
Self-Supervised Variational Auto-Encoders
Oct 06, 2020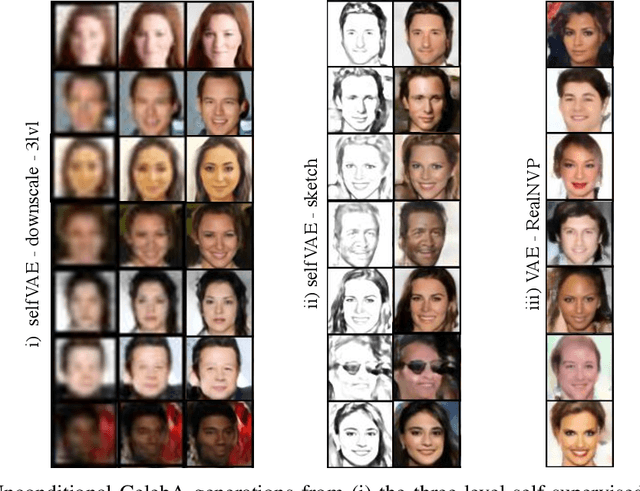


Density estimation, compression and data generation are crucial tasks in artificial intelligence. Variational Auto-Encoders (VAEs) constitute a single framework to achieve these goals. Here, we present a novel class of generative models, called self-supervised Variational Auto-Encoder (selfVAE), that utilizes deterministic and discrete variational posteriors. This class of models allows to perform both conditional and unconditional sampling, while simplifying the objective function. First, we use a single self-supervised transformation as a latent variable, where a transformation is either downscaling or edge detection. Next, we consider a hierarchical architecture, i.e., multiple transformations, and we show its benefits compared to the VAE. The flexibility of selfVAE in data reconstruction finds a particularly interesting use case in data compression tasks, where we can trade-off memory for better data quality, and vice-versa. We present performance of our approach on three benchmark image data (Cifar10, Imagenette64, and CelebA).
Super-resolution Variational Auto-Encoders
Jun 30, 2020

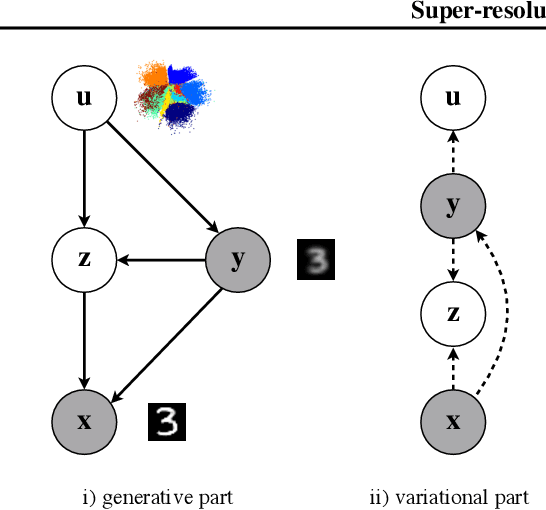
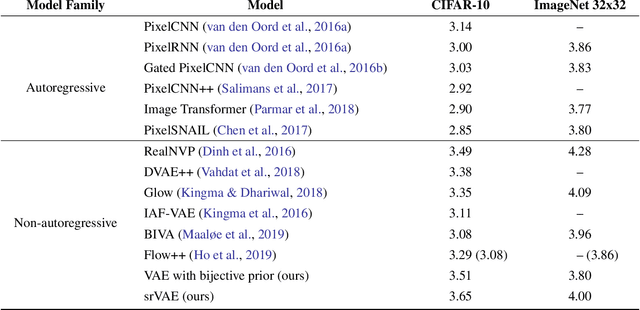
The framework of variational autoencoders (VAEs) provides a principled method for jointly learning latent-variable models and corresponding inference models. However, the main drawback of this approach is the blurriness of the generated images. Some studies link this effect to the objective function, namely, the (negative) log-likelihood. Here, we propose to enhance VAEs by adding a random variable that is a downscaled version of the original image and still use the log-likelihood function as the learning objective. Further, by providing the downscaled image as an input to the decoder, it can be used in a manner similar to the super-resolution. We present empirically that the proposed approach performs comparably to VAEs in terms of the negative log-likelihood, but it obtains a better FID score in data synthesis.