 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing Consistent Deep Clustering
Nov 03, 2020
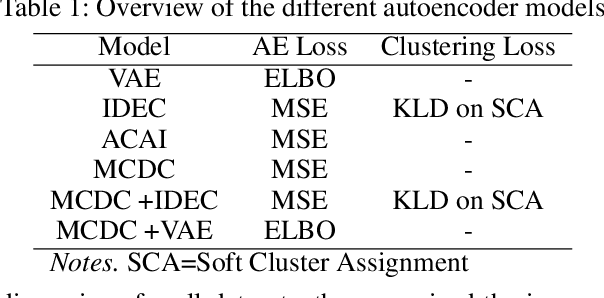
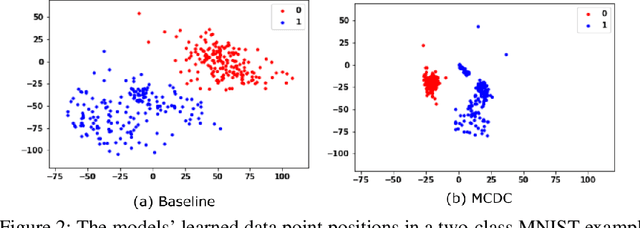
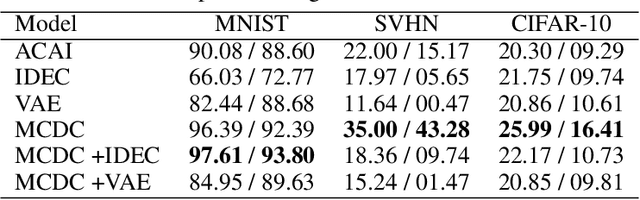
Finding well-defined clusters in data represents a fundamental challenge for many data-driven applications, and largely depends on good data representation. Drawing on literature regarding representation learning, studies suggest that one key characteristic of good latent representations is the ability to produce semantically mixed outputs when decoding linear interpolations of two latent representations. We propose the Mixing Consistent Deep Clustering method which encourages interpolations to appear realistic while adding the constraint that interpolations of two data points must look like one of the two inputs. By applying this training method to various clustering (non-)specific autoencoder models we found that using the proposed training method systematically changed the structure of learned representations of a model and it improved clustering performance for the tested ACAI, IDEC, and VAE models on the MNIST, SVHN, and CIFAR-10 datasets. These outcomes have practical implications for numerous real-world clustering tasks, as it shows that the proposed method can be added to existing autoencoders to further improve clustering performance.