 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNAP: Sequential Non-Ancestor Pruning for Targeted Causal Effect Estimation With an Unknown Graph
Feb 11, 2025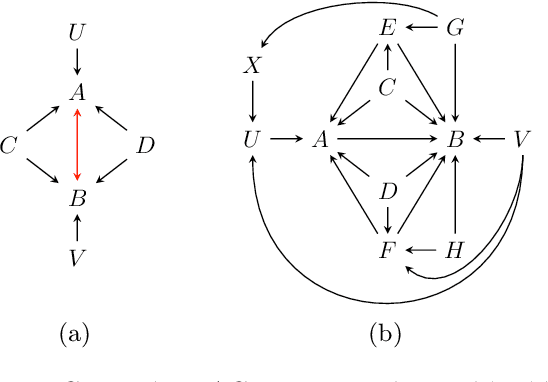
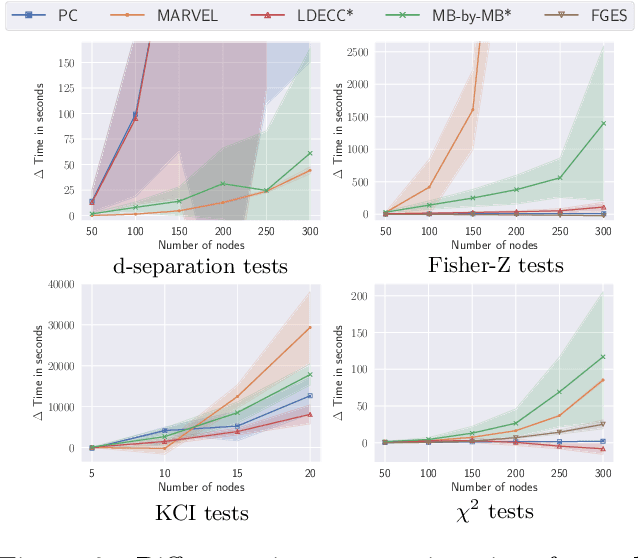
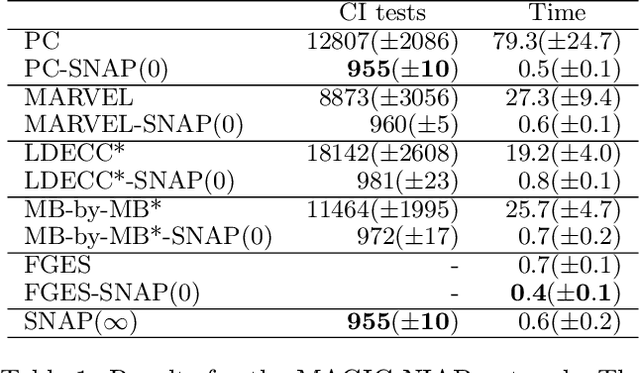
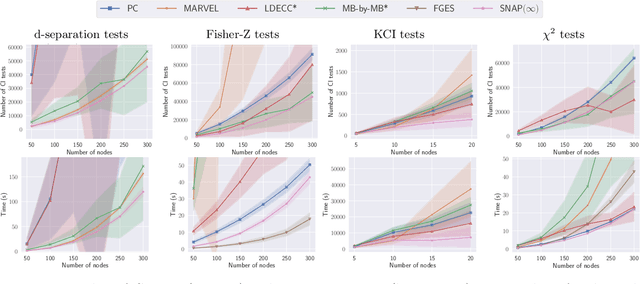
Causal discovery can be computationally demanding for large numbers of variables. If we only wish to estimate the causal effects on a small subset of target variables, we might not need to learn the causal graph for all variables, but only a small subgraph that includes the targets and their adjustment sets. In this paper, we focus on identifying causal effects between target variables in a computationally and statistically efficient way. This task combines causal discovery and effect estimation, aligning the discovery objective with the effects to be estimated. We show that definite non-ancestors of the targets are unnecessary to learn causal relations between the targets and to identify efficient adjustments sets. We sequentially identify and prune these definite non-ancestors with our Sequential Non-Ancestor Pruning (SNAP) framework, which can be used either as a preprocessing step to standard causal discovery methods, or as a standalone sound and complete causal discovery algorithm. Our results on synthetic and real data show that both approaches substantially reduce the number of independence tests and the computation time without compromising the quality of causal effect estimations.
Towards Causal Credit Assignment
Dec 22, 2022



Adequately assigning credit to actions for future outcomes based on their contributions is a long-standing open challenge in Reinforcement Learning. The assumptions of the most commonly used credit assignment method are disadvantageous in tasks where the effects of decisions are not immediately evident. Furthermore, this method can only evaluate actions that have been selected by the agent, making it highly inefficient. Still, no alternative methods have been widely adopted in the field. Hindsight Credit Assignment is a promising, but still unexplored candidate, which aims to solve the problems of both long-term and counterfactual credit assignment. In this thesis, we empirically investigate Hindsight Credit Assignment to identify its main benefits, and key points to improve. Then, we apply it to factored state representations, and in particular to state representations based on the causal structure of the environment. In this setting, we propose a variant of Hindsight Credit Assignment that effectively exploits a given causal structure. We show that our modification greatly decreases the workload of Hindsight Credit Assignment, making it more efficient and enabling it to outperform the baseline credit assignment method on various tasks. This opens the way to other methods based on given or learned causal structures.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.