 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-to-Local Support Spectrums for Language Model Explainability
Aug 12, 2024



Existing sample-based methods, like influence functions and representer points, measure the importance of a training point by approximating the effect of its removal from training. As such, they are skewed towards outliers and points that are very close to the decision boundaries. The explanations provided by these methods are often static and not specific enough for different test points. In this paper, we propose a method to generate an explanation in the form of support spectrums which are based on two main ideas: the support sets and a global-to-local importance measure. The support set is the set of training points, in the predicted class, that ``lie in between'' the test point and training points in the other classes. They indicate how well the test point can be distinguished from the points not in the predicted class. The global-to-local importance measure is obtained by decoupling existing methods into the global and local components which are then used to select the points in the support set. Using this method, we are able to generate explanations that are tailored to specific test points. In the experiments, we show the effectiveness of the method in image classification and text generation tasks.
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024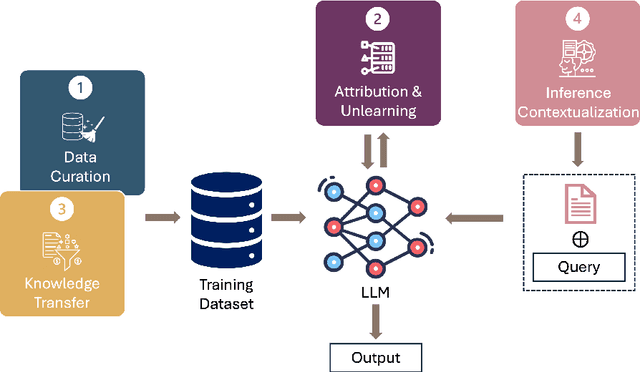
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
On the Convergence of the Shapley Value in Parametric Bayesian Learning Games
May 16, 2022


Measuring contributions is a classical problem in cooperative game theory where the Shapley value is the most well-known solution concept. In this paper, we establish the convergence property of the Shapley value in parametric Bayesian learning games where players perform a Bayesian inference using their combined data, and the posterior-prior KL divergence is used as the characteristic function. We show that for any two players, under some regularity conditions, their difference in Shapley value converges in probability to the difference in Shapley value of a limiting game whose characteristic function is proportional to the log-determinant of the joint Fisher information. As an application, we present an online collaborative learning framework that is asymptotically Shapley-fair. Our result enables this to be achieved without any costly computations of posterior-prior KL divergences. Only a consistent estimator of the Fisher information is needed. The framework's effectiveness is demonstrated with experiments using real-world data.
Toward Large-Scale Agent Guidance in an Urban Taxi Service
Oct 16, 2012



Empty taxi cruising represents a wastage of resources in the context of urban taxi services. In this work, we seek to minimize such wastage. An analysis of a large trace of taxi operations reveals that the services' inefficiency is caused by drivers' greedy cruising behavior. We model the existing system as a continuous time Markov chain. To address the problem, we propose that each taxi be equipped with an intelligent agent that will guide the driver when cruising for passengers. Then, drawing from AI literature on multiagent planning, we explore two possible ways to compute such guidance. The first formulation assumes fully cooperative drivers. This allows us, in principle, to compute systemwide optimal cruising policy. This is modeled as a Markov decision process. The second formulation assumes rational drivers, seeking to maximize their own profit. This is modeled as a stochastic congestion game, a specialization of stochastic games. Nash equilibrium policy is proposed as the solution to the game, where no driver has the incentive to singly deviate from it. Empirical result shows that both formulations improve the efficiency of the service significantly.