 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-spectral Face Completion for NIR-VIS Heterogeneous Face Recognition
Feb 10, 2019
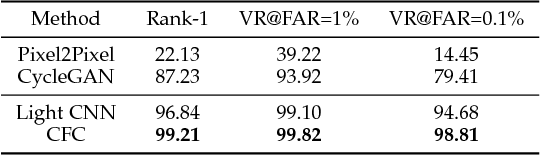
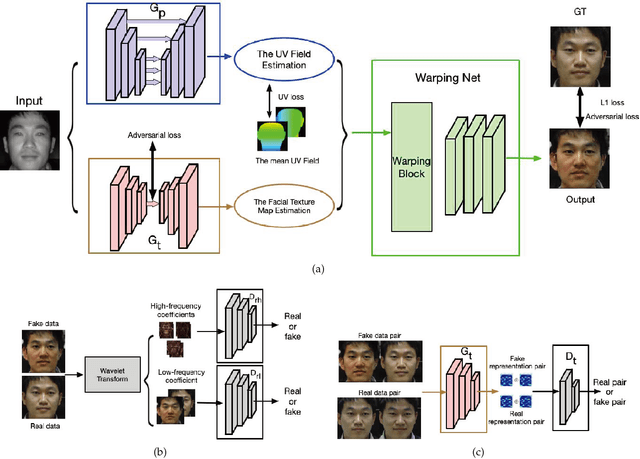
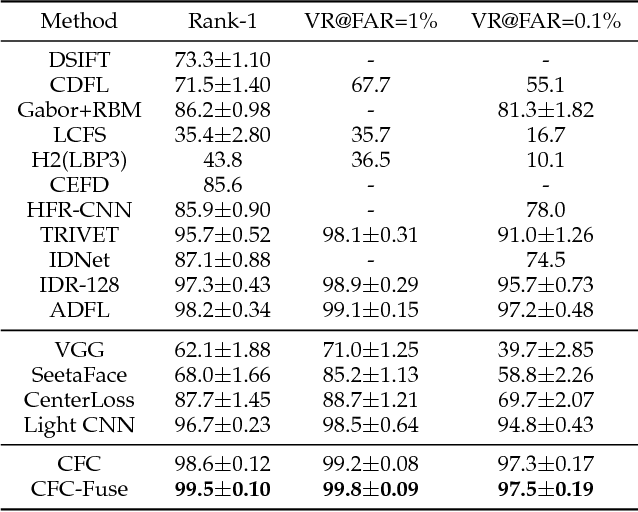
Near infrared-visible (NIR-VIS) heterogeneous face recognition refers to the process of matching NIR to VIS face images. Current heterogeneous methods try to extend VIS face recognition methods to the NIR spectrum by synthesizing VIS images from NIR images. However, due to self-occlusion and sensing gap, NIR face images lose some visible lighting contents so that they are always incomplete compared to VIS face images. This paper models high resolution heterogeneous face synthesis as a complementary combination of two components, a texture inpainting component and pose correction component. The inpainting component synthesizes and inpaints VIS image textures from NIR image textures. The correction component maps any pose in NIR images to a frontal pose in VIS images, resulting in paired NIR and VIS textures. A warping procedure is developed to integrate the two components into an end-to-end deep network. A fine-grained discriminator and a wavelet-based discriminator are designed to supervise intra-class variance and visual quality respectively. One UV loss, two adversarial losses and one pixel loss are imposed to ensure synthesis results. We demonstrate that by attaching the correction component, we can simplify heterogeneous face synthesis from one-to-many unpaired image translation to one-to-one paired image translation, and minimize spectral and pose discrepancy during heterogeneous recognition. Extensive experimental results show that our network not only generates high-resolution VIS face images and but also facilitates the accuracy improvement of heterogeneous face recognition.
Adversarial Occlusion-aware Face Detection
Sep 29, 2018
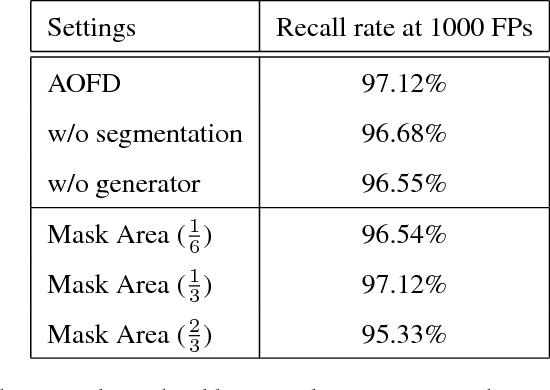
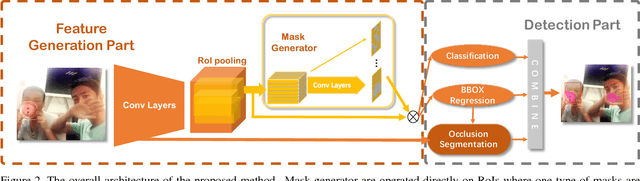
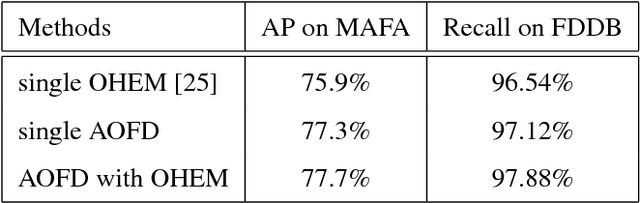
Occluded face detection is a challenging detection task due to the large appearance variations incurred by various real-world occlusions. This paper introduces an Adversarial Occlusion-aware Face Detector (AOFD) by simultaneously detecting occluded faces and segmenting occluded areas. Specifically, we employ an adversarial training strategy to generate occlusion-like face features that are difficult for a face detector to recognize. Occlusion mask is predicted simultaneously while detecting occluded faces and the occluded area is utilized as an auxiliary instead of being regarded as a hindrance. Moreover, the supervisory signals from the segmentation branch will reversely affect the features, aiding in detecting heavily-occluded faces accordingly. Consequently, AOFD is able to find the faces with few exposed facial landmarks with very high confidences and keeps high detection accuracy even for masked faces. Extensive experiments demonstrate that AOFD not only significantly outperforms state-of-the-art methods on the MAFA occluded face detection dataset, but also achieves competitive detection accuracy on benchmark dataset for general face detection such as FDDB.
Variational Capsules for Image Analysis and Synthesis
Jul 11, 2018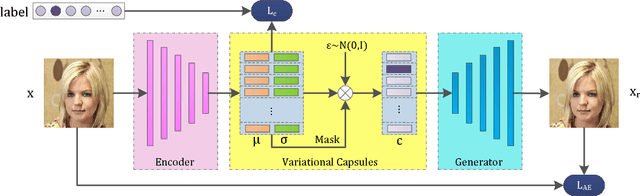


A capsule is a group of neurons whose activity vector models different properties of the same entity. This paper extends the capsule to a generative version, named variational capsules (VCs). Each VC produces a latent variable for a specific entity, making it possible to integrate image analysis and image synthesis into a unified framework. Variational capsules model an image as a composition of entities in a probabilistic model. Different capsules' divergence with a specific prior distribution represents the presence of different entities, which can be applied in image analysis tasks such as classification. In addition, variational capsules encode multiple entities in a semantically-disentangling way. Diverse instantiations of capsules are related to various properties of the same entity, making it easy to generate diverse samples with fine-grained semantic attributes. Extensive experiments demonstrate that deep networks designed with variational capsules can not only achieve promising performance on image analysis tasks (including image classification and attribute prediction) but can also improve the diversity and controllability of image synthesis.
Geometry Guided Adversarial Facial Expression Synthesis
Dec 10, 2017



Facial expression synthesis has drawn much attention in the field of computer graphics and pattern recognition. It has been widely used in face animation and recognition. However, it is still challenging due to the high-level semantic presence of large and non-linear face geometry variations. This paper proposes a Geometry-Guided Generative Adversarial Network (G2-GAN) for photo-realistic and identity-preserving facial expression synthesis. We employ facial geometry (fiducial points) as a controllable condition to guide facial texture synthesis with specific expression. A pair of generative adversarial subnetworks are jointly trained towards opposite tasks: expression removal and expression synthesis. The paired networks form a mapping cycle between neutral expression and arbitrary expressions, which also facilitate other applications such as face transfer and expression invariant face recognition. Experimental results show that our method can generate compelling perceptual results on various facial expression synthesis databases. An expression invariant face recognition experiment is also performed to further show the advantages of our proposed method.
Anti-Makeup: Learning A Bi-Level Adversarial Network for Makeup-Invariant Face Verification
Nov 22, 2017
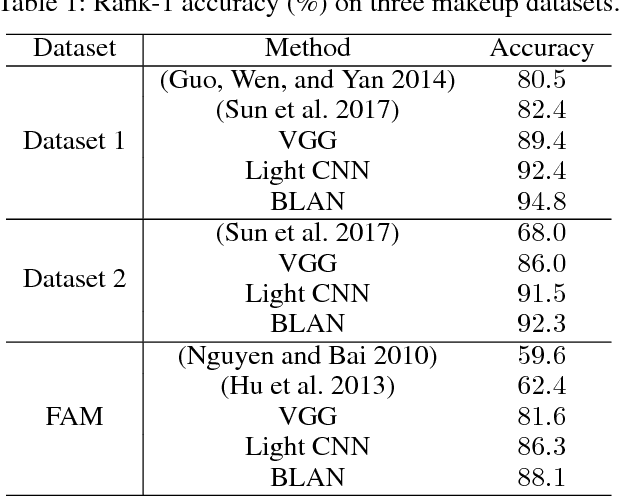
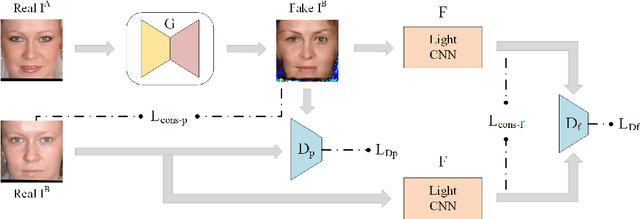
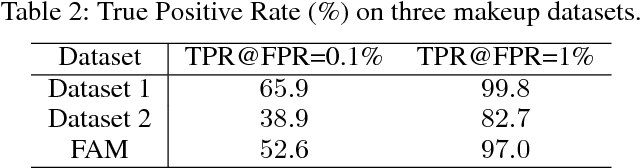
Makeup is widely used to improve facial attractiveness and is well accepted by the public. However, different makeup styles will result in significant facial appearance changes. It remains a challenging problem to match makeup and non-makeup face images. This paper proposes a learning from generation approach for makeup-invariant face verification by introducing a bi-level adversarial network (BLAN). To alleviate the negative effects from makeup, we first generate non-makeup images from makeup ones, and then use the synthesized non-makeup images for further verification. Two adversarial networks in BLAN are integrated in an end-to-end deep network, with the one on pixel level for reconstructing appealing facial images and the other on feature level for preserving identity information. These two networks jointly reduce the sensing gap between makeup and non-makeup images. Moreover, we make the generator well constrained by incorporating multiple perceptual losses. Experimental results on three benchmark makeup face datasets demonstrate that our method achieves state-of-the-art verification accuracy across makeup status and can produce photo-realistic non-makeup face images.
Coupled Deep Learning for Heterogeneous Face Recognition
Nov 16, 2017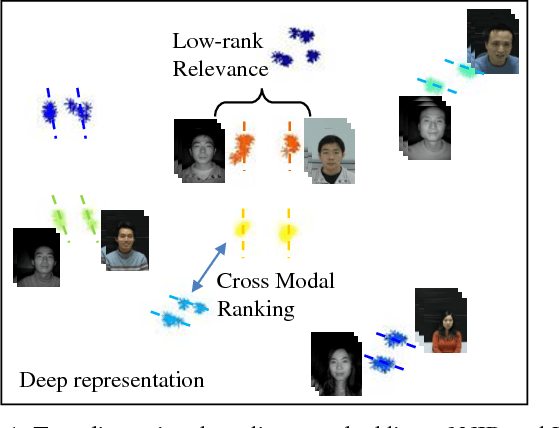

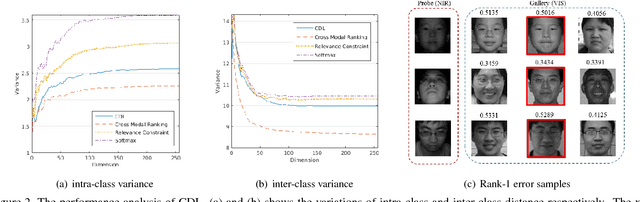
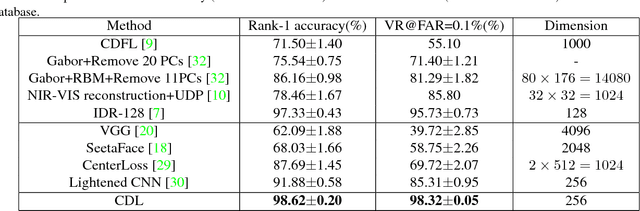
Heterogeneous face matching is a challenge issue in face recognition due to large domain difference as well as insufficient pairwise images in different modalities during training. This paper proposes a coupled deep learning (CDL) approach for the heterogeneous face matching. CDL seeks a shared feature space in which the heterogeneous face matching problem can be approximately treated as a homogeneous face matching problem. The objective function of CDL mainly includes two parts. The first part contains a trace norm and a block-diagonal prior as relevance constraints, which not only make unpaired images from multiple modalities be clustered and correlated, but also regularize the parameters to alleviate overfitting. An approximate variational formulation is introduced to deal with the difficulties of optimizing low-rank constraint directly. The second part contains a cross modal ranking among triplet domain specific images to maximize the margin for different identities and increase data for a small amount of training samples. Besides, an alternating minimization method is employed to iteratively update the parameters of CDL. Experimental results show that CDL achieves better performance on the challenging CASIA NIR-VIS 2.0 face recognition database, the IIIT-D Sketch database, the CUHK Face Sketch (CUFS), and the CUHK Face Sketch FERET (CUFSF), which significantly outperforms state-of-the-art heterogeneous face recognition methods.
Adversarial Discriminative Heterogeneous Face Recognition
Sep 12, 2017
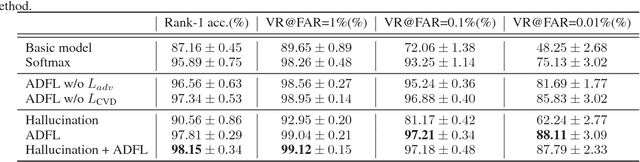

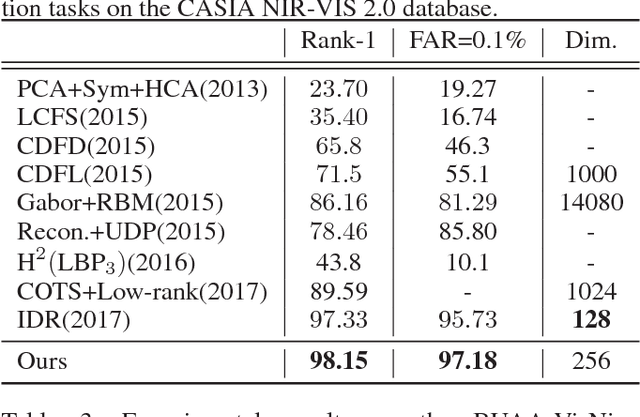
The gap between sensing patterns of different face modalities remains a challenging problem in heterogeneous face recognition (HFR). This paper proposes an adversarial discriminative feature learning framework to close the sensing gap via adversarial learning on both raw-pixel space and compact feature space. This framework integrates cross-spectral face hallucination and discriminative feature learning into an end-to-end adversarial network. In the pixel space, we make use of generative adversarial networks to perform cross-spectral face hallucination. An elaborate two-path model is introduced to alleviate the lack of paired images, which gives consideration to both global structures and local textures. In the feature space, an adversarial loss and a high-order variance discrepancy loss are employed to measure the global and local discrepancy between two heterogeneous distributions respectively. These two losses enhance domain-invariant feature learning and modality independent noise removing. Experimental results on three NIR-VIS databases show that our proposed approach outperforms state-of-the-art HFR methods, without requiring of complex network or large-scale training dataset.