 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Learn Metric Space for Few-Shot Segmentation of 3D Shapes
Jul 07, 2021


Recent research has seen numerous supervised learning-based methods for 3D shape segmentation and remarkable performance has been achieved on various benchmark datasets. These supervised methods require a large amount of annotated data to train deep neural networks to ensure the generalization ability on the unseen test set. In this paper, we introduce a meta-learning-based method for few-shot 3D shape segmentation where only a few labeled samples are provided for the unseen classes. To achieve this, we treat the shape segmentation as a point labeling problem in the metric space. Specifically, we first design a meta-metric learner to transform input shapes into embedding space and our model learns to learn a proper metric space for each object class based on point embeddings. Then, for each class, we design a metric learner to extract part-specific prototype representations from a few support shapes and our model performs per-point segmentation over the query shapes by matching each point to its nearest prototype in the learned metric space. A metric-based loss function is used to dynamically modify distances between point embeddings thus maximizes in-part similarity while minimizing inter-part similarity. A dual segmentation branch is adopted to make full use of the support information and implicitly encourages consistency between the support and query prototypes. We demonstrate the superior performance of our proposed on the ShapeNet part dataset under the few-shot scenario, compared with well-established baseline and state-of-the-art semi-supervised methods.
3D Meta-Registration: Learning to Learn Registration of 3D Point Clouds
Oct 22, 2020


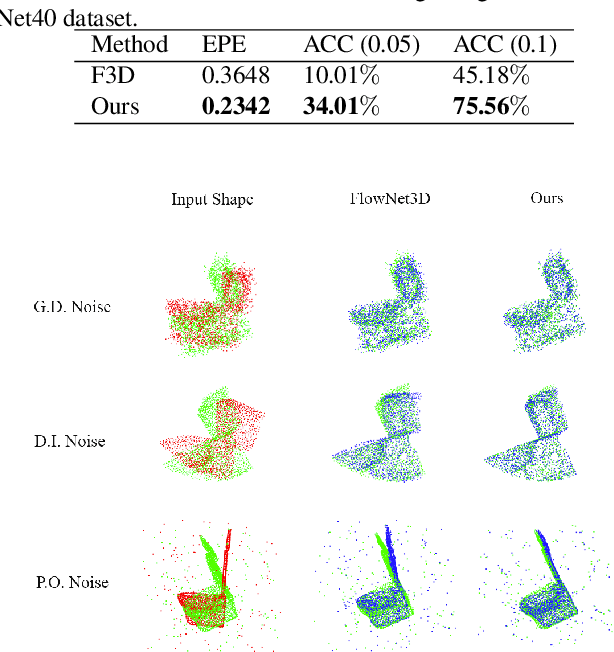
Deep learning-based point cloud registration models are often generalized from extensive training over a large volume of data to learn the ability to predict the desired geometric transformation to register 3D point clouds. In this paper, we propose a meta-learning based 3D registration model, named 3D Meta-Registration, that is capable of rapidly adapting and well generalizing to new 3D registration tasks for unseen 3D point clouds. Our 3D Meta-Registration gains a competitive advantage by training over a variety of 3D registration tasks, which leads to an optimized model for the best performance on the distribution of registration tasks including potentially unseen tasks. Specifically, the proposed 3D Meta-Registration model consists of two modules: 3D registration learner and 3D registration meta-learner. During the training, the 3D registration learner is trained to complete a specific registration task aiming to determine the desired geometric transformation that aligns the source point cloud with the target one. In the meantime, the 3D registration meta-learner is trained to provide the optimal parameters to update the 3D registration learner based on the learned task distribution. After training, the 3D registration meta-learner, which is learned with the optimized coverage of distribution of 3D registration tasks, is able to dynamically update 3D registration learners with desired parameters to rapidly adapt to new registration tasks. We tested our model on synthesized dataset ModelNet and FlyingThings3D, as well as real-world dataset KITTI. Experimental results demonstrate that 3D Meta-Registration achieves superior performance over other previous techniques (e.g. FlowNet3D).
3D Meta Point Signature: Learning to Learn 3D Point Signature for 3D Dense Shape Correspondence
Oct 21, 2020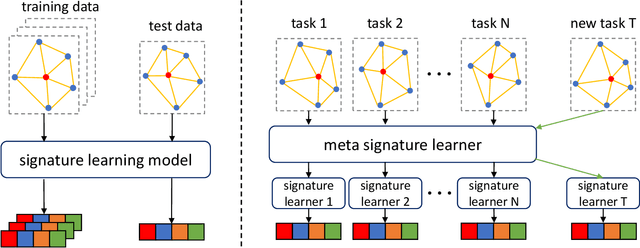
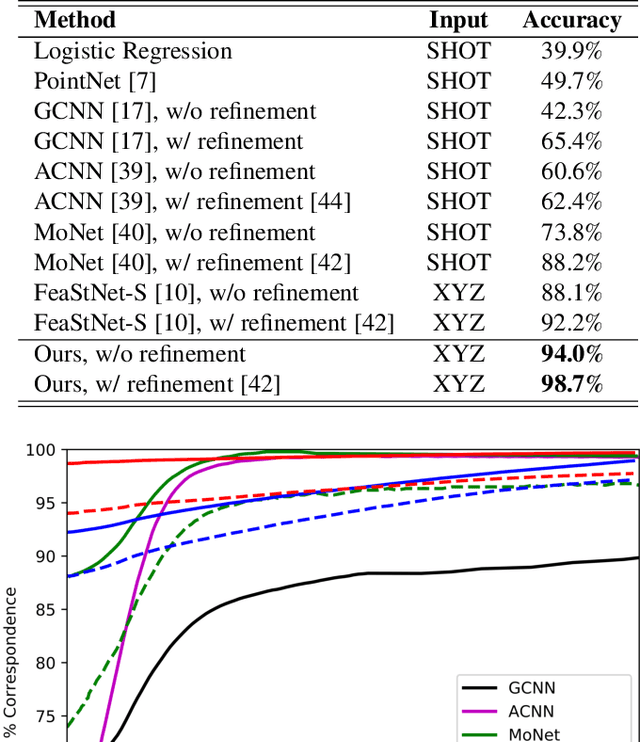

Point signature, a representation describing the structural neighborhood of a point in 3D shapes, can be applied to establish correspondences between points in 3D shapes. Conventional methods apply a weight-sharing network, e.g., any kind of graph neural networks, across all neighborhoods to directly generate point signatures and gain the generalization ability by extensive training over a large amount of training samples from scratch. However, these methods lack the flexibility in rapidly adapting to unseen neighborhood structures and thus generalizes poorly on new point sets. In this paper, we propose a novel meta-learning based 3D point signature model, named 3Dmetapointsignature (MEPS) network, that is capable of learning robust point signatures in 3D shapes. By regarding each point signature learning process as a task, our method obtains an optimized model over the best performance on the distribution of all tasks, generating reliable signatures for new tasks, i.e., signatures of unseen point neighborhoods. Specifically, the MEPS consists of two modules: a base signature learner and a meta signature learner. During training, the base-learner is trained to perform specific signature learning tasks. In the meantime, the meta-learner is trained to update the base-learner with optimal parameters. During testing, the meta-learner that is learned with the distribution of all tasks can adaptively change parameters of the base-learner, accommodating to unseen local neighborhoods. We evaluate the MEPS model on two datasets, e.g., FAUST and TOSCA, for dense 3Dshape correspondence. Experimental results demonstrate that our method not only gains significant improvements over the baseline model and achieves state-of-the-art results, but also is capable of handling unseen 3D shapes.
Deep-3DAligner: Unsupervised 3D Point Set Registration Network With Optimizable Latent Vector
Sep 29, 2020
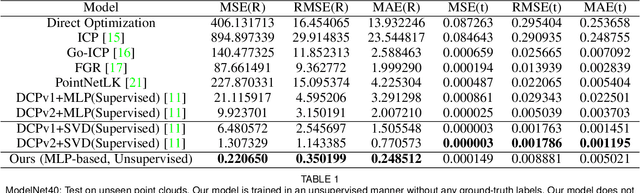
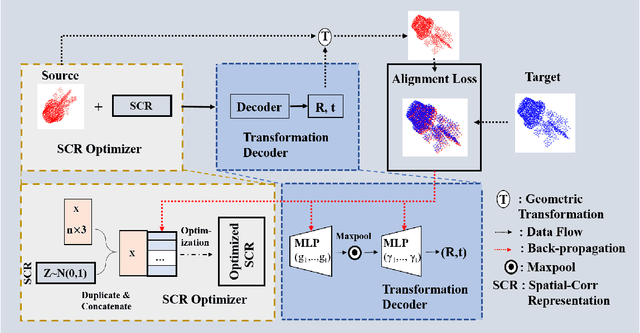
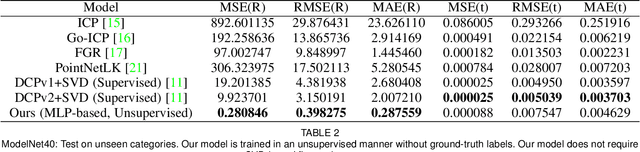
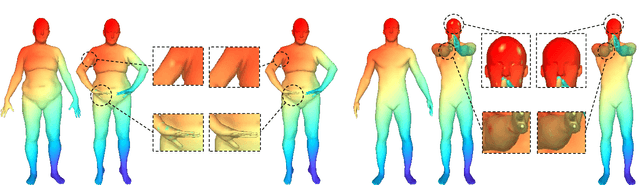
Point cloud registration is the process of aligning a pair of point sets via searching for a geometric transformation. Unlike classical optimization-based methods, recent learning-based methods leverage the power of deep learning for registering a pair of point sets. In this paper, we propose to develop a novel model that organically integrates the optimization to learning, aiming to address the technical challenges in 3D registration. More specifically, in addition to the deep transformation decoding network, our framework introduce an optimizable deep \underline{S}patial \underline{C}orrelation \underline{R}epresentation (SCR) feature. The SCR feature and weights of the transformation decoder network are jointly updated towards the minimization of an unsupervised alignment loss. We further propose an adaptive Chamfer loss for aligning partial shapes. To verify the performance of our proposed method, we conducted extensive experiments on the ModelNet40 dataset. The results demonstrate that our method achieves significantly better performance than the previous state-of-the-art approaches in the full/partial point set registration task.
Unsupervised Partial Point Set Registration via Joint Shape Completion and Registration
Sep 11, 2020



We propose a self-supervised method for partial point set registration. While recent proposed learning-based methods have achieved impressive registration performance on the full shape observations, these methods mostly suffer from performance degradation when dealing with partial shapes. To bridge the performance gaps between partial point set registration with full point set registration, we proposed to incorporate a shape completion network to benefit the registration process. To achieve this, we design a latent code for each pair of shapes, which can be regarded as a geometric encoding of the target shape. By doing so, our model does need an explicit feature embedding network to learn the feature encodings. More importantly, both our shape completion network and the point set registration network take the shared latent codes as input, which are optimized along with the parameters of two decoder networks in the training process. Therefore, the point set registration process can thus benefit from the joint optimization process of latent codes, which are enforced to represent the information of full shape instead of partial ones. In the inference stage, we fix the network parameter and optimize the latent codes to get the optimal shape completion and registration results. Our proposed method is pure unsupervised and does not need any ground truth supervision. Experiments on the ModelNet40 dataset demonstrate the effectiveness of our model for partial point set registration.
Robust Image Matching By Dynamic Feature Selection
Aug 13, 2020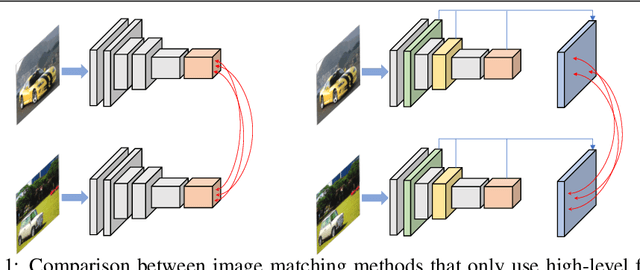
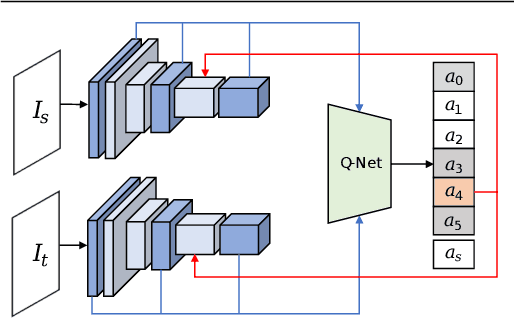
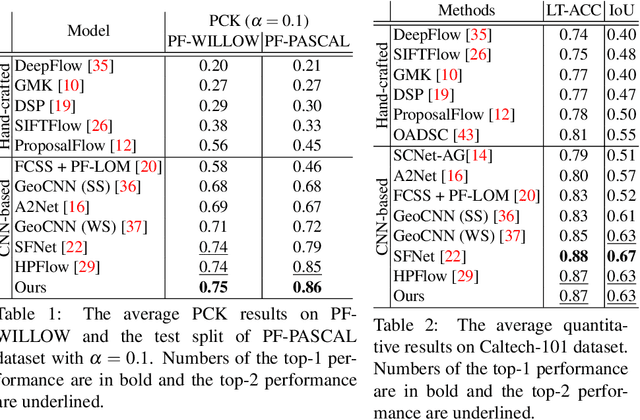
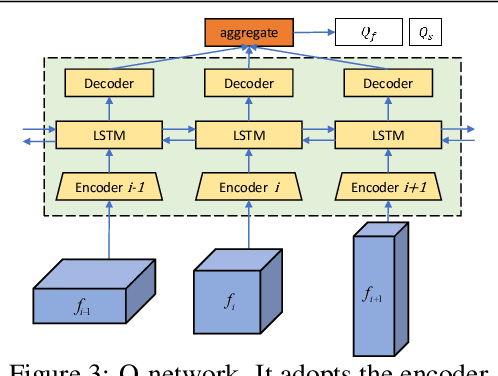
Estimating dense correspondences between images is a long-standing image under-standing task. Recent works introduce convolutional neural networks (CNNs) to extract high-level feature maps and find correspondences through feature matching. However,high-level feature maps are in low spatial resolution and therefore insufficient to provide accurate and fine-grained features to distinguish intra-class variations for correspondence matching. To address this problem, we generate robust features by dynamically selecting features at different scales. To resolve two critical issues in feature selection,i.e.,how many and which scales of features to be selected, we frame the feature selection process as a sequential Markov decision-making process (MDP) and introduce an optimal selection strategy using reinforcement learning (RL). We define an RL environment for image matching in which each individual action either requires new features or terminates the selection episode by referring a matching score. Deep neural networks are incorporated into our method and trained for decision making. Experimental results show that our method achieves comparable/superior performance with state-of-the-art methods on three benchmarks, demonstrating the effectiveness of our feature selection strategy.
GP-Aligner: Unsupervised Non-rigid Groupwise Point Set Registration Based On Optimized Group Latent Descriptor
Jul 25, 2020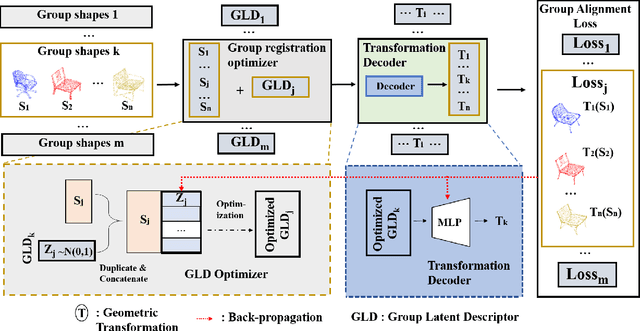


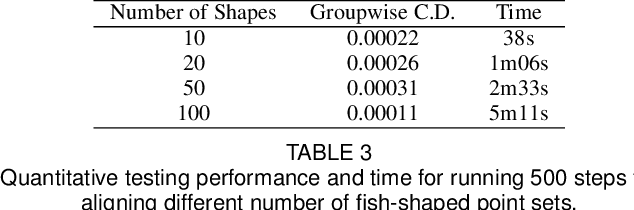
In this paper, we propose a novel method named GP-Aligner to deal with the problem of non-rigid groupwise point set registration. Compared to previous non-learning approaches, our proposed method gains competitive advantages by leveraging the power of deep neural networks to effectively and efficiently learn to align a large number of highly deformed 3D shapes with superior performance. Unlike most learning-based methods that use an explicit feature encoding network to extract the per-shape features and their correlations, our model leverages a model-free learnable latent descriptor to characterize the group relationship. More specifically, for a given group we first define an optimizable Group Latent Descriptor (GLD) to characterize the gruopwise relationship among a group of point sets. Each GLD is randomly initialized from a Gaussian distribution and then concatenated with the coordinates of each point of the associated point sets in the group. A neural network-based decoder is further constructed to predict the coherent drifts as the desired transformation from input groups of shapes to aligned groups of shapes. During the optimization process, GP-Aligner jointly updates all GLDs and weight parameters of the decoder network towards the minimization of an unsupervised groupwise alignment loss. After optimization, for each group our model coherently drives each point set towards a middle, common position (shape) without specifying one as the target. GP-Aligner does not require large-scale training data for network training and it can directly align groups of point sets in a one-stage optimization process. GP-Aligner shows both accuracy and computational efficiency improvement in comparison with state-of-the-art methods for groupwise point set registration. Moreover, GP-Aligner is shown great efficiency in aligning a large number of groups of real-world 3D shapes.
Unsupervised Learning of Global Registration of Temporal Sequence of Point Clouds
Jun 17, 2020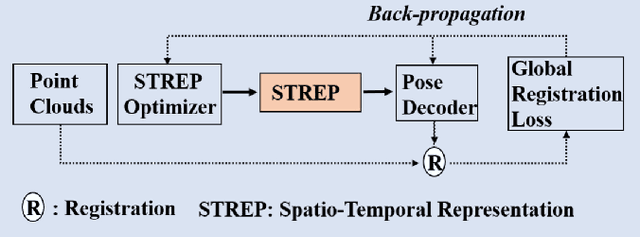
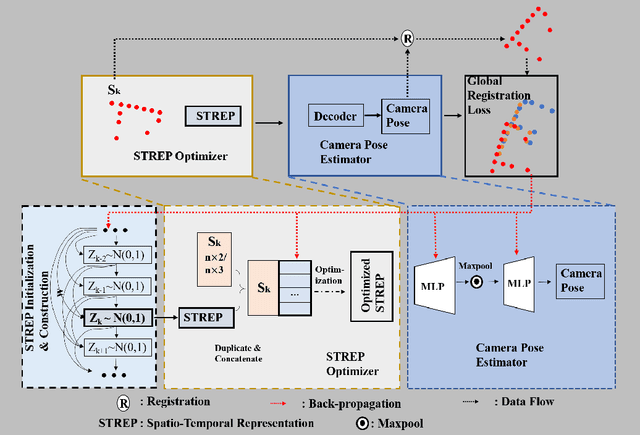
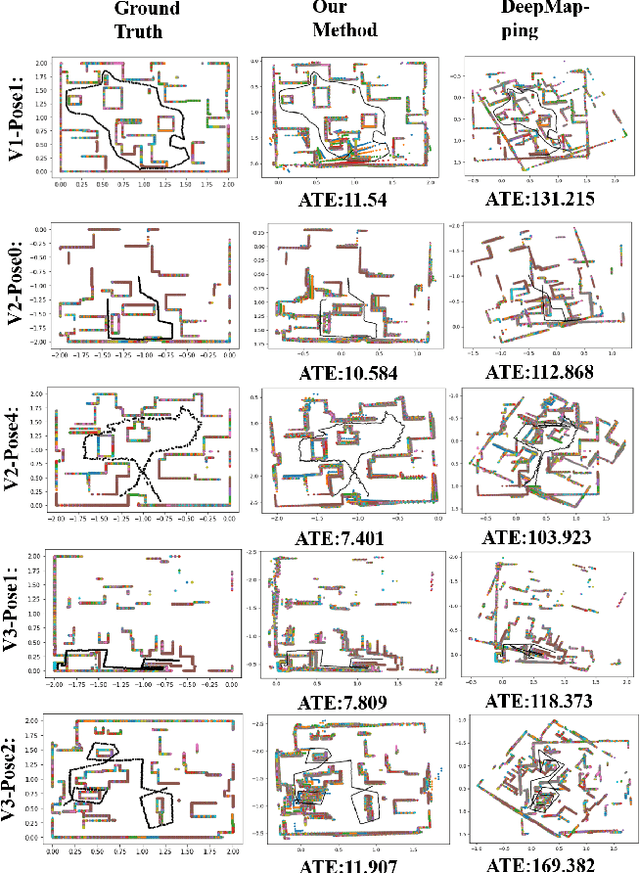

Global registration of point clouds aims to find an optimal alignment of a sequence of 2D or 3D point sets. In this paper, we present a novel method that takes advantage of current deep learning techniques for unsupervised learning of global registration from a temporal sequence of point clouds. Our key novelty is that we introduce a deep Spatio-Temporal REPresentation (STREP) feature, which describes the geometric essence of both temporal and spatial relationship of the sequence of point clouds acquired with sensors in an unknown environment. In contrast to the previous practice that treats each time step (pair-wise registration) individually, our unsupervised model starts with optimizing a sequence of latent STREP feature, which is then decoded to a temporally and spatially continuous sequence of geometric transformations to globally align multiple point clouds. We have evaluated our proposed approach over both simulated 2D and real 3D datasets and the experimental results demonstrate that our method can beat other techniques by taking into account the temporal information in deep feature learning.
Unsupervised Learning of 3D Point Set Registration
Jun 11, 2020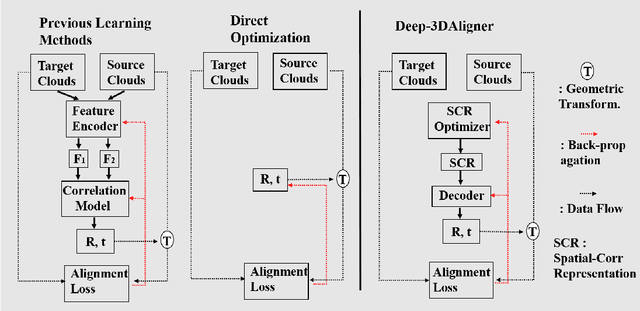



Point cloud registration is the process of aligning a pair of point sets via searching for a geometric transformation. Recent works leverage the power of deep learning for registering a pair of point sets. However, unfortunately, deep learning models often require a large number of ground truth labels for training. Moreover, for a pair of source and target point sets, existing deep learning mechanisms require explicitly designed encoders to extract both deep spatial features from unstructured point clouds and their spatial correlation representation, which is further fed to a decoder to regress the desired geometric transformation for point set alignment. To further enhance deep learning models for point set registration, this paper proposes Deep-3DAligner, a novel unsupervised registration framework based on a newly introduced deep Spatial Correlation Representation (SCR) feature. The SCR feature describes the geometric essence of the spatial correlation between source and target point sets in an encoding-free manner. More specifically, our method starts with optimizing a randomly initialized latent SCR feature, which is then decoded to a geometric transformation (i.e., rotation and translation) to align source and target point sets. Our Deep-3DAligner jointly updates the SCR feature and weights of the transformation decoder towards the minimization of an unsupervised alignment loss. We conducted experiments on the ModelNet40 datasets to validate the performance of our unsupervised Deep-3DAligner for point set registration. The results demonstrated that, even without ground truth and any assumption of a direct correspondence between source and target point sets for training, our proposed approach achieved comparative performance compared to most recent supervised state-of-the-art approaches.
Density-Aware Convolutional Networks with Context Encoding for Airborne LiDAR Point Cloud Classification
Oct 14, 2019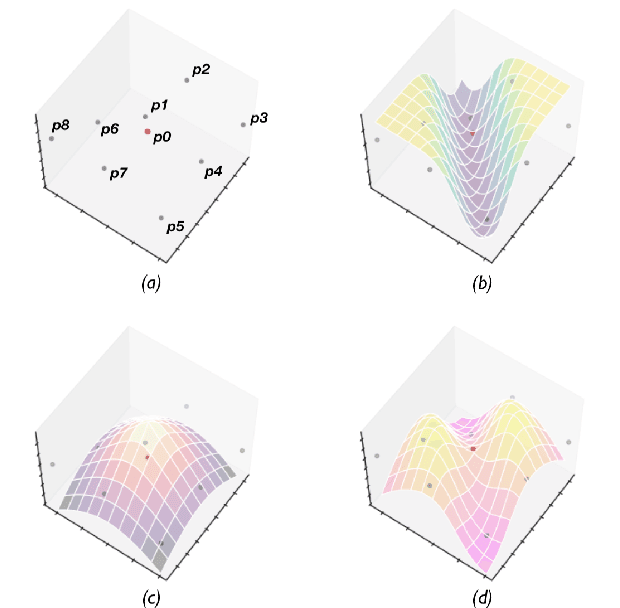

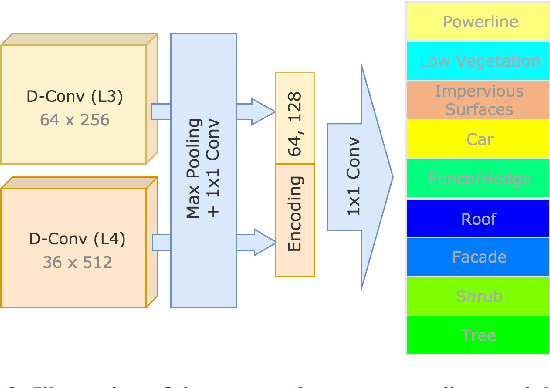
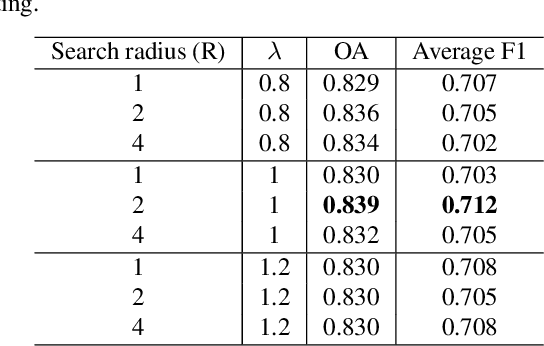
To better address challenging issues of the irregularity and inhomogeneity inherently present in 3D point clouds, researchers have been shifting their focus from the design of hand-craft point feature towards the learning of 3D point signatures using deep neural networks for 3D point cloud classification. Recent proposed deep learning based point cloud classification methods either apply 2D CNN on projected feature images or apply 1D convolutional layers directly on raw point sets. These methods cannot adequately recognize fine-grained local structures caused by the uneven density distribution of the point cloud data. In this paper, to address this challenging issue, we introduced a density-aware convolution module which uses the point-wise density to re-weight the learnable weights of convolution kernels. The proposed convolution module is able to fully approximate the 3D continuous convolution on unevenly distributed 3D point sets. Based on this convolution module, we further developed a multi-scale fully convolutional neural network with downsampling and upsampling blocks to enable hierarchical point feature learning. In addition, to regularize the global semantic context, we implemented a context encoding module to predict a global context encoding and formulated a context encoding regularizer to enforce the predicted context encoding to be aligned with the ground truth one. The overall network can be trained in an end-to-end fashion with the raw 3D coordinates as well as the height above ground as inputs. Experiments on the International Society for Photogrammetry and Remote Sensing (ISPRS) 3D labeling benchmark demonstrated the superiority of the proposed method for point cloud classification. Our model achieved a new state-of-the-art performance with an average F1 score of 71.2% and improved the performance by a large margin on several categories.