 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSell More, Play Less: Benchmarking LLM Realistic Selling Skill
Apr 09, 2026Sales dialogues require multi-turn, goal-directed persuasion under asymmetric incentives, which makes them a challenging setting for large language models (LLMs). Yet existing dialogue benchmarks rarely measure deal progression and outcomes. We introduce SalesLLM benchmark, a bilingual (ZH/EN) benchmark derived from realistic applications covering Financial Services and Consumer Goods, built from 30,074 scripted configurations and 1,805 curated multi-turn scenarios with controllable difficulty and personas. We propose a fully automatic evaluation pipeline that combines (i) an LLM-based rater for sales-process progress,and (ii) fine-tuned BERT classifiers for end-of-dialogue buying intent. To improve simulation fidelity, we train a user model, CustomerLM, with SFT and DPO on 8,000+ crowdworker-involved sales conversations, reducing role inversion from 17.44% (GPT-4o) to 8.8%. SalesLLM benchmark scores correlate strongly with expert human ratings (Pearson r=0.98). Experiments across 15 mainstream LLMs reveal substantial variability: top-performance LLMs are competitive with human-level performance while the less capable ones are worse than human. SalesLLM benchmark serves as a scalable benchmark for developing and evaluating outcome-oriented sales agents.
Mistake Notebook Learning: Selective Batch-Wise Context Optimization for In-Context Learning
Dec 12, 2025


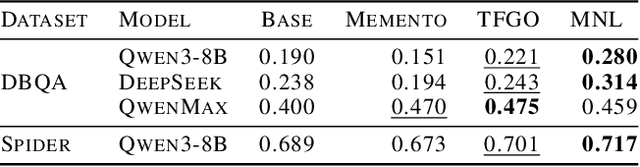
Large language models (LLMs) adapt to tasks via gradient fine-tuning (heavy computation, catastrophic forgetting) or In-Context Learning (ICL: low robustness, poor mistake learning). To fix this, we introduce Mistake Notebook Learning (MNL), a training-free framework with a persistent knowledge base of abstracted error patterns. Unlike prior instance/single-trajectory memory methods, MNL uses batch-wise error abstraction: it extracts generalizable guidance from multiple failures, stores insights in a dynamic notebook, and retains only baseline-outperforming guidance via hold-out validation (ensuring monotonic improvement). We show MNL nearly matches Supervised Fine-Tuning (93.9% vs 94.3% on GSM8K) and outperforms training-free alternatives on GSM8K, Spider, AIME, and KaggleDBQA. On KaggleDBQA (Qwen3-8B), MNL hits 28% accuracy (47% relative gain), outperforming Memento (15.1%) and Training-Free GRPO (22.1) - proving it's a strong training-free alternative for complex reasoning.
Scaling Gaussian Processes with Derivative Information Using Variational Inference
Jul 08, 2021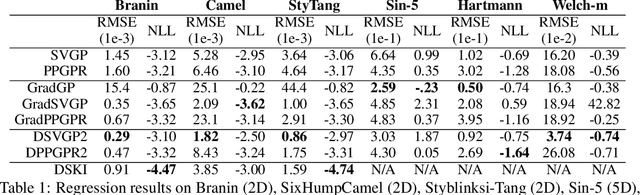
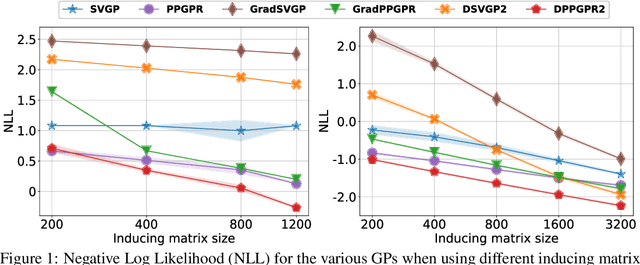

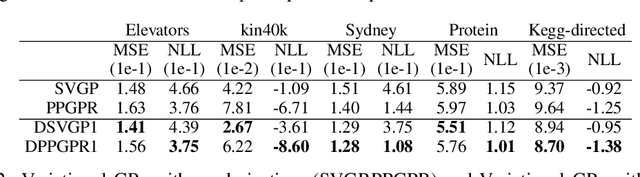
Gaussian processes with derivative information are useful in many settings where derivative information is available, including numerous Bayesian optimization and regression tasks that arise in the natural sciences. Incorporating derivative observations, however, comes with a dominating $O(N^3D^3)$ computational cost when training on $N$ points in $D$ input dimensions. This is intractable for even moderately sized problems. While recent work has addressed this intractability in the low-$D$ setting, the high-$N$, high-$D$ setting is still unexplored and of great value, particularly as machine learning problems increasingly become high dimensional. In this paper, we introduce methods to achieve fully scalable Gaussian process regression with derivatives using variational inference. Analogous to the use of inducing values to sparsify the labels of a training set, we introduce the concept of inducing directional derivatives to sparsify the partial derivative information of a training set. This enables us to construct a variational posterior that incorporates derivative information but whose size depends neither on the full dataset size $N$ nor the full dimensionality $D$. We demonstrate the full scalability of our approach on a variety of tasks, ranging from a high dimensional stellarator fusion regression task to training graph convolutional neural networks on Pubmed using Bayesian optimization. Surprisingly, we find that our approach can improve regression performance even in settings where only label data is available.
Density of States Graph Kernels
Oct 21, 2020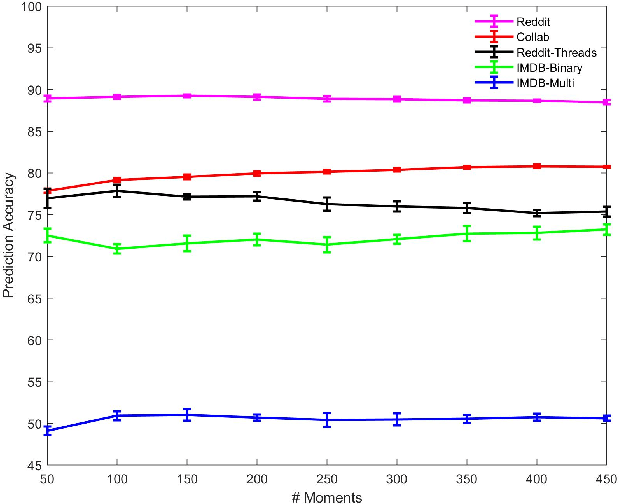
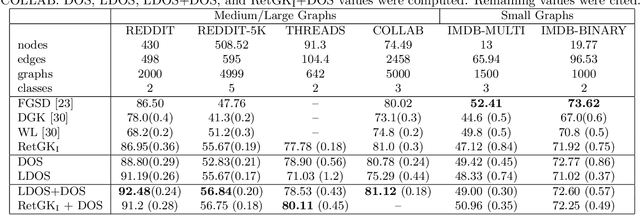
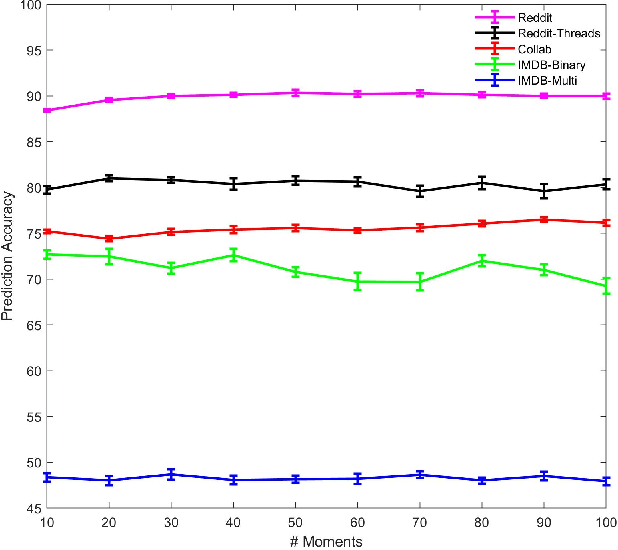

An important problem on graph-structured data is that of quantifying similarity between graphs. Graph kernels are an established technique for such tasks; in particular, those based on random walks and return probabilities have proven to be effective in wide-ranging applications, from bioinformatics to social networks to computer vision. However, random walk kernels generally suffer from slowness and tottering, an effect which causes walks to overemphasize local graph topology, undercutting the importance of global structure. To correct for these issues, we recast return probability graph kernels under the more general framework of density of states -- a framework which uses the lens of spectral analysis to uncover graph motifs and properties hidden within the interior of the spectrum -- and use our interpretation to construct scalable, composite density of states based graph kernels which balance local and global information, leading to higher classification accuracies on a host of benchmark datasets.
Neural Manifold Ordinary Differential Equations
Jun 18, 2020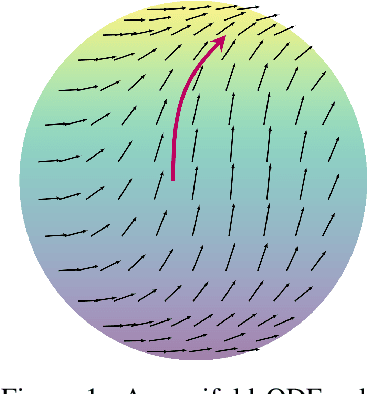
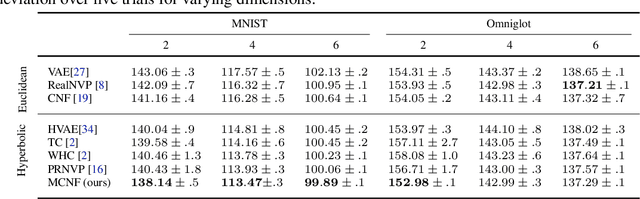
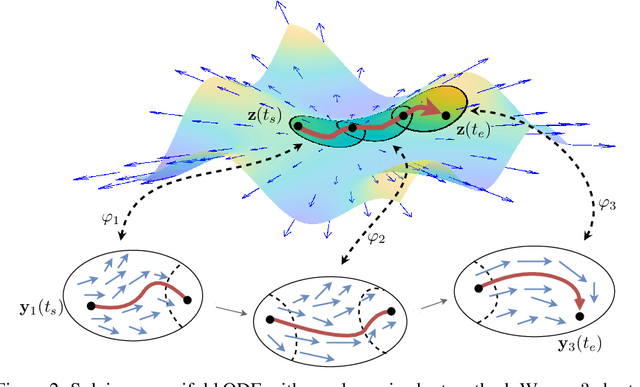
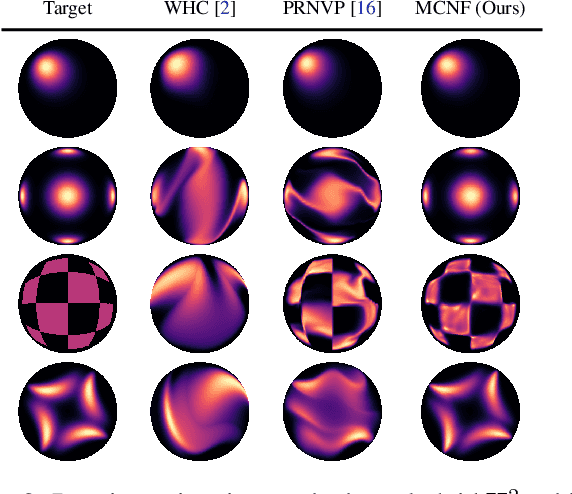
To better conform to data geometry, recent deep generative modelling techniques adapt Euclidean constructions to non-Euclidean spaces. In this paper, we study normalizing flows on manifolds. Previous work has developed flow models for specific cases; however, these advancements hand craft layers on a manifold-by-manifold basis, restricting generality and inducing cumbersome design constraints. We overcome these issues by introducing Neural Manifold Ordinary Differential Equations, a manifold generalization of Neural ODEs, which enables the construction of Manifold Continuous Normalizing Flows (MCNFs). MCNFs require only local geometry (therefore generalizing to arbitrary manifolds) and compute probabilities with continuous change of variables (allowing for a simple and expressive flow construction). We find that leveraging continuous manifold dynamics produces a marked improvement for both density estimation and downstream tasks.