 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity of States Graph Kernels
Oct 21, 2020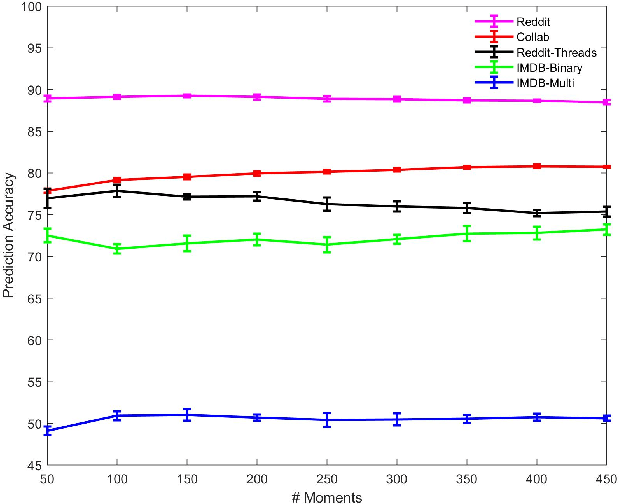
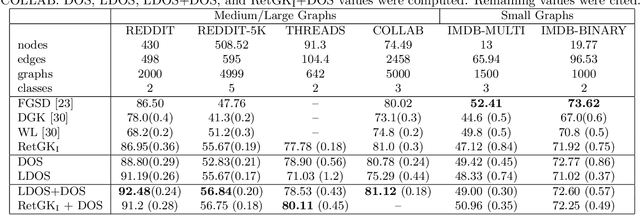
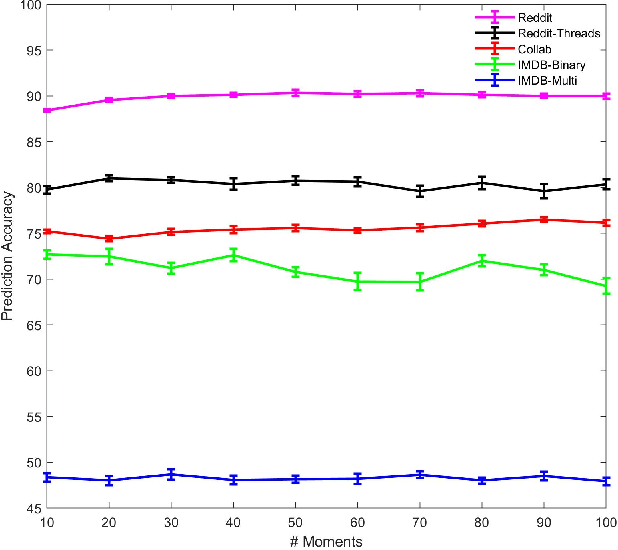

An important problem on graph-structured data is that of quantifying similarity between graphs. Graph kernels are an established technique for such tasks; in particular, those based on random walks and return probabilities have proven to be effective in wide-ranging applications, from bioinformatics to social networks to computer vision. However, random walk kernels generally suffer from slowness and tottering, an effect which causes walks to overemphasize local graph topology, undercutting the importance of global structure. To correct for these issues, we recast return probability graph kernels under the more general framework of density of states -- a framework which uses the lens of spectral analysis to uncover graph motifs and properties hidden within the interior of the spectrum -- and use our interpretation to construct scalable, composite density of states based graph kernels which balance local and global information, leading to higher classification accuracies on a host of benchmark datasets.