 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Dexterous Grasp Learning from Single-View Point Clouds via a Multi-Object Scene Dataset
Mar 16, 2026Dexterous grasping in multi-object scene constitutes a fundamental challenge in robotic manipulation. Current mainstream grasping datasets predominantly focus on single-object scenarios and predefined grasp configurations, often neglecting environmental interference and the modeling of dexterous pre-grasp gesture, thereby limiting their generalizability in real-world applications. To address this, we propose DGS-Net, an end-to-end grasp prediction network capable of learning dense grasp configurations from single-view point clouds in multi-object scene. Furthermore, we propose a two-stage grasp data generation strategy that progresses from dense single-object grasp synthesis to dense scene-level grasp generation. Our dataset comprises 307 objects, 240 multi-object scenes, and over 350k validated grasps. By explicitly modeling grasp offsets and pre-grasp configurations, the dataset provides more robust and accurate supervision for dexterous grasp learning. Experimental results show that DGS-Net achieves grasp success rates of 88.63\% in simulation and 78.98\% on a real robotic platform, while exhibiting lower penetration with a mean penetration depth of 0.375 mm and penetration volume of 559.45 mm^3, outperforming existing methods and demonstrating strong effectiveness and generalization capability. Our dataset is available at https://github.com/4taotao8/DGS-Net.
TSGP: Two-Stage Generative Prompting for Unsupervised Commonsense Question Answering
Nov 24, 2022
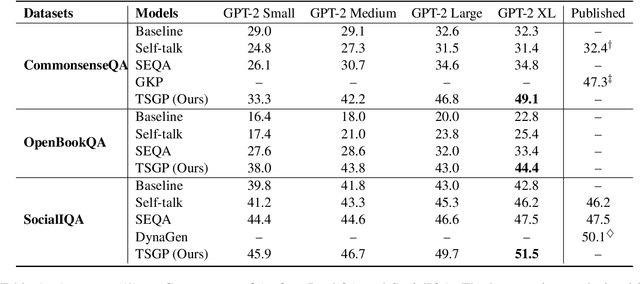
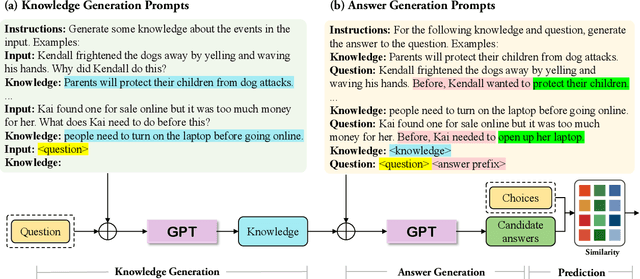

Unsupervised commonsense question answering requires mining effective commonsense knowledge without the rely on the labeled task data. Previous methods typically retrieved from traditional knowledge bases or used pre-trained language models (PrLMs) to generate fixed types of knowledge, which have poor generalization ability. In this paper, we aim to address the above limitation by leveraging the implicit knowledge stored in PrLMs and propose a two-stage prompt-based unsupervised commonsense question answering framework (TSGP). Specifically, we first use knowledge generation prompts to generate the knowledge required for questions with unlimited types and possible candidate answers independent of specified choices. Then, we further utilize answer generation prompts to generate possible candidate answers independent of specified choices. Experimental results and analysis on three different commonsense reasoning tasks, CommonsenseQA, OpenBookQA, and SocialIQA, demonstrate that TSGP significantly improves the reasoning ability of language models in unsupervised settings. Our code is available at: https://github.com/Yueqing-Sun/TSGP.
Prototype Design and Efficiency Analysis of a Novel Robot Drive Based on 3K-H-V Topology
Oct 05, 2022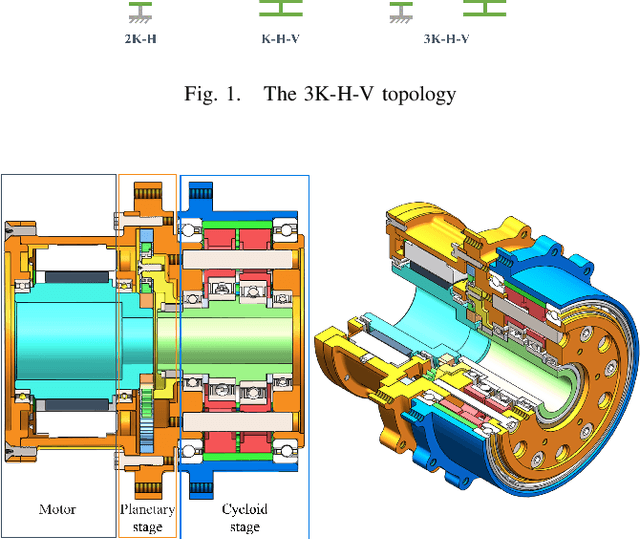
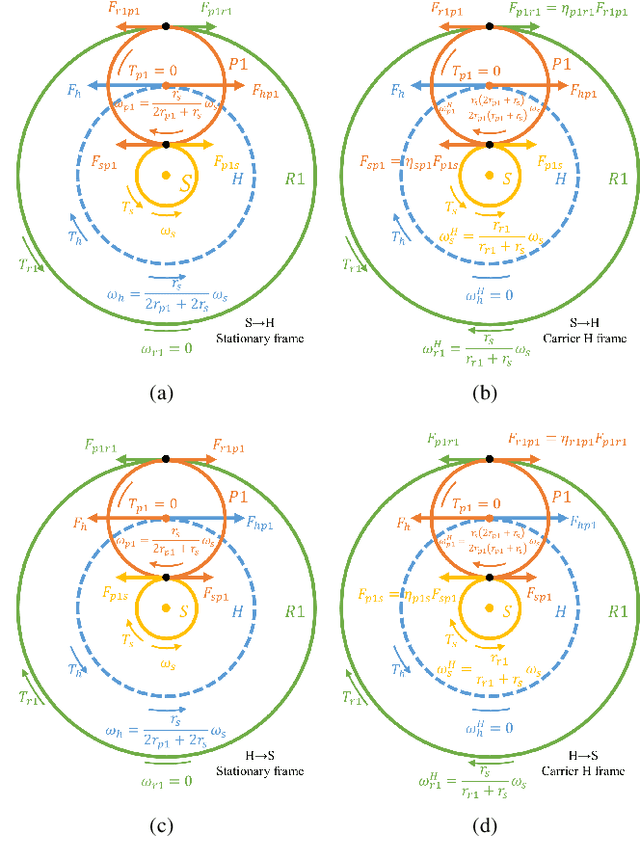
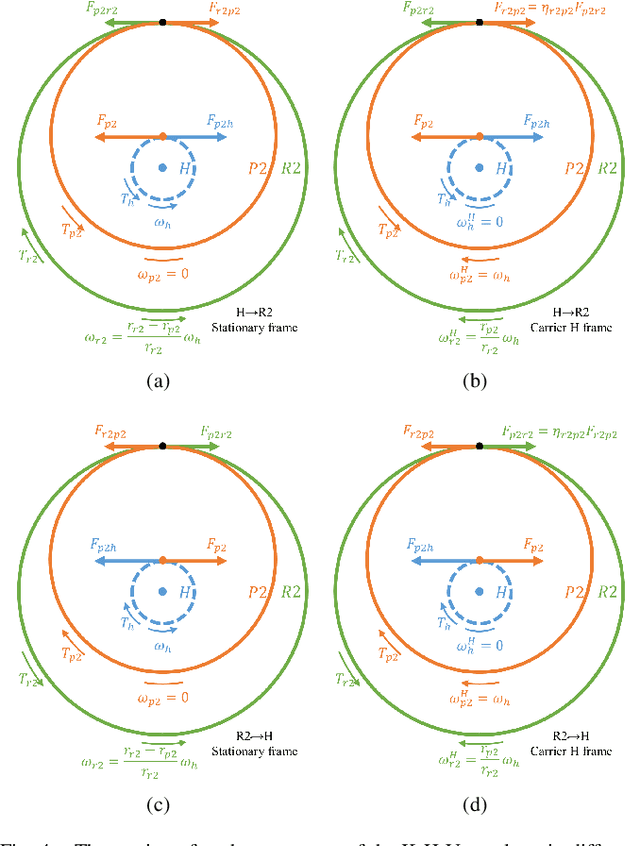
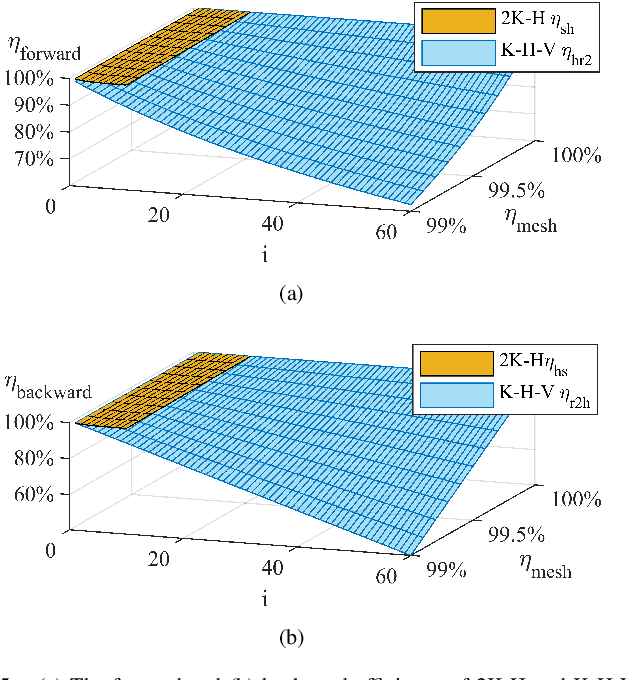
Robot actuators directly affect the performance of robots, and robot drives directly affect the performance of robot actuators. With the development of robotics, robots have put higher requirements on robot drives, such as high stiffness, high accuracy, high loading, high efficiency, low backlash, compact size, and hollow structure. In order to meet the demand development of robot actuators, this research base proposes a new robot drive based on 3K-H-V topology using involute and cycloidal gear shapes, planetary cycloidal drive, from the perspective of drive topology and through the design idea of decoupling. In this study, the reduction ratio and the efficiency model of the 3K-H-V topology were analyzed, and a prototype planetary cycloidal actuator was designed. The feasibility of the drive is initially verified by experimentally concluding that the PCA has a hollow structure, compact size, and high torque density (69 kg/Nm).
JointLK: Joint Reasoning with Language Models and Knowledge Graphs for Commonsense Question Answering
Dec 06, 2021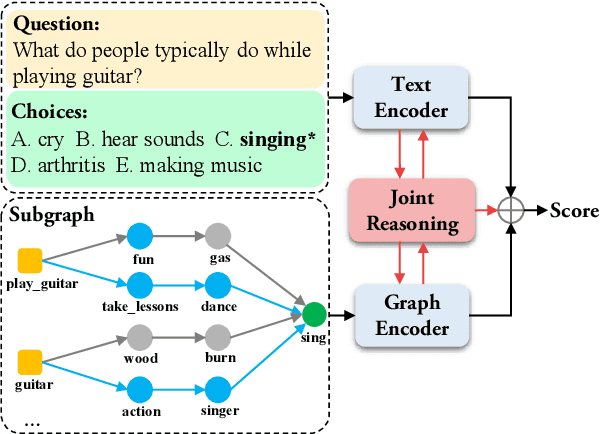
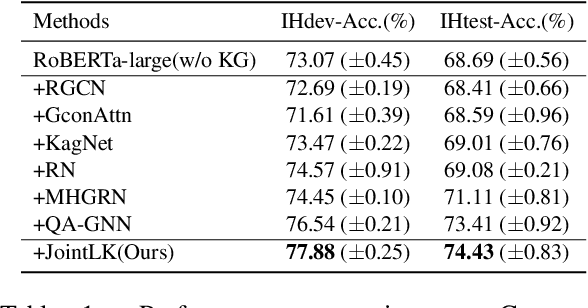
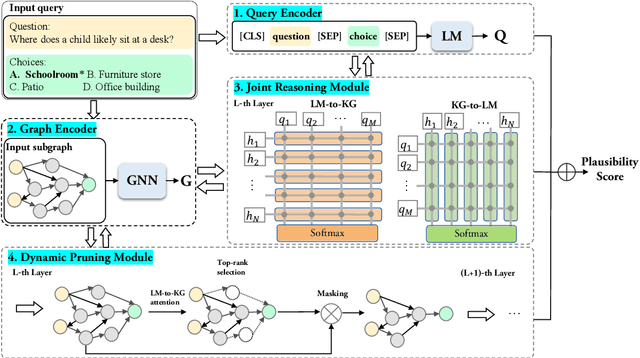

Existing KG-augmented models for question answering primarily focus on designing elaborate Graph Neural Networks (GNNs) to model knowledge graphs (KGs). However, they ignore (i) the effectively fusing and reasoning over question context representations and the KG representations, and (ii) automatically selecting relevant nodes from the noisy KGs during reasoning. In this paper, we propose a novel model, JointLK, which solves the above limitations through the joint reasoning of LMs and GNNs and the dynamic KGs pruning mechanism. Specifically, JointLK performs joint reasoning between the LMs and the GNNs through a novel dense bidirectional attention module, in which each question token attends on KG nodes and each KG node attends on question tokens, and the two modal representations fuse and update mutually by multi-step interactions. Then, the dynamic pruning module uses the attention weights generated by joint reasoning to recursively prune irrelevant KG nodes. Our results on the CommonsenseQA and OpenBookQA datasets demonstrate that our modal fusion and knowledge pruning methods can make better use of relevant knowledge for reasoning.
Multiple Structural Priors Guided Self Attention Network for Language Understanding
Dec 29, 2020Self attention networks (SANs) have been widely utilized in recent NLP studies. Unlike CNNs or RNNs, standard SANs are usually position-independent, and thus are incapable of capturing the structural priors between sequences of words. Existing studies commonly apply one single mask strategy on SANs for incorporating structural priors while failing at modeling more abundant structural information of texts. In this paper, we aim at introducing multiple types of structural priors into SAN models, proposing the Multiple Structural Priors Guided Self Attention Network (MS-SAN) that transforms different structural priors into different attention heads by using a novel multi-mask based multi-head attention mechanism. In particular, we integrate two categories of structural priors, including the sequential order and the relative position of words. For the purpose of capturing the latent hierarchical structure of the texts, we extract these information not only from the word contexts but also from the dependency syntax trees. Experimental results on two tasks show that MS-SAN achieves significant improvements against other strong baselines.