 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMineExplorer: Evaluating Open-World Exploration of MLLM Agents in Minecraft
May 29, 2026Multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and action generation. However, their ability to sustain exploration in dynamic open worlds remains unclear. Existing embodied and game-based benchmarks often compress interaction into short-horizon tasks or entangle success with domain-specific game mechanics. In this paper, we introduce MineExplorer benchmark for evaluating open-world exploration capabilities of MLLM agents in Minecraft. We first filter atomic tasks whose solutions rely heavily on Minecraft-specific knowledge to better reflect general open-world reasoning. Then we organize the benchmark around a ReAct-style capability formulation and compose atomic tasks into implicit multi-hop tasks. To further construct reliable instances, MineExplorer uses a multi-agent synthesis workflow that jointly designs task graphs, sandbox scenes, and rule-based milestone evaluators. Human evaluation shows that the multi-agent synthesis workflow produces significantly more reliable instances than a single-agent baseline. Experiments with advanced MLLM agents show that open-world exploration remains challenging, as strong models can handle many single-hop tasks but degrade sharply when hidden prerequisites must be coordinated over longer trajectories. Further analysis finds that task difficulty tracks agent completion, and larger models or thinking modes do not consistently translate into better performance. Code and dataset are available at https://github.com/Jometeorie/MineExplorer.
MAP: A Map-then-Act Paradigm for Long-Horizon Interactive Agent Reasoning
May 13, 2026Current interactive LLM agents rely on goal-conditioned stepwise planning, where environmental understanding is acquired reactively during execution rather than established beforehand. This temporal inversion leads to Delayed Environmental Perception: agents must infer environmental constraints through trial-and-error, resulting in an Epistemic Bottleneck that traps them in inefficient failure cycles. Inspired by human affordance perception and cognitive map theory, we propose the Map-then-Act Paradigm (MAP), a plug-and-play framework that shifts environment understanding before execution. MAP consists of three stages: (1) Global Exploration, acquiring environment-general priors; (2) Task-Specific Mapping, constructing a structured cognitive map; and (3) Knowledge-Augmented Execution, solving tasks grounded on the map. Experiments show consistent gains across benchmarks and LLMs. On ARC-AGI-3, MAP enables frontier models to surpass near-zero baseline performance in 22 of 25 game environments. We further introduce MAP-2K, a dataset of map-then-act trajectories, and show that training on it outperforms expert execution traces, suggesting that understanding environments is more fundamental than imitation.
$V_{0.5}$: Generalist Value Model as a Prior for Sparse RL Rollouts
Mar 11, 2026In Reinforcement Learning with Verifiable Rewards (RLVR), constructing a robust advantage baseline is critical for policy gradients, effectively guiding the policy model to reinforce desired behaviors. Recent research has introduced Generalist Value Models (such as $V_0$), which achieve pre-trained value estimation by explicitly encoding model capabilities in-context, eliminating the need to synchronously update the value model alongside the policy model. In this paper, we propose $V_{0.5}$, which adaptively fuses the baseline predicted by such value model (acting as a prior) with the empirical mean derived from sparse rollouts. This constructs a robust baseline that balances computational efficiency with extremely low variance. Specifically, we introduce a real-time statistical testing and dynamic budget allocation. This balances the high variance caused by sparse sampling against the systematic bias (or hallucinations) inherent in the value model's prior. By constructing a hypothesis test to evaluate the prior's reliability in real-time, the system dynamically allocates additional rollout budget on demand. This mechanism minimizes the baseline estimator's Mean Squared Error (MSE), guaranteeing stable policy gradients, even under extreme sparsity with a group size of 4. Extensive evaluations across six mathematical reasoning benchmarks demonstrate that $V_{0.5}$ significantly outperforms GRPO and DAPO, achieving faster convergence and over some 10% performance improvement.
TopoCurate:Modeling Interaction Topology for Tool-Use Agent Training
Mar 02, 2026Training tool-use agents typically relies on outcome-based filtering: Supervised Fine-Tuning (SFT) on successful trajectories and Reinforcement Learning (RL) on pass-rate-selected tasks. However, this paradigm ignores interaction dynamics: successful trajectories may lack error recovery or exhibit redundancy, while pass rates fail to distinguish structurally informative tasks from trivial ones. We propose \textbf{TopoCurate}, an interaction-aware framework that projects multi-trial rollouts from the same task into a unified semantic quotient topology. By merging equivalent action-observation states, this projection transforms scattered linear trajectories into a structured manifold that explicitly captures how tool invocations and environmental responses drive the divergence between effective strategies and failure modes. Leveraging this representation, we introduce a dual-selection mechanism: for SFT, we prioritize trajectories demonstrating reflective recovery, semantic efficiency, and strategic diversity to mitigate covariate shift and mode collapse; for RL, we select tasks with high error branch ratios and strategic heterogeneity, maximizing gradient Signal-to-Noise Ratio to address vanishing signals in sparse-reward settings. Evaluations on BFCLv3 and Tau2 Bench show that TopoCurate achieves consistent gains of 4.2\% (SFT) and 6.9\% (RL) over state-of-the-art baselines. We will release the code and data soon for further investigations.
ScaleEnv: Scaling Environment Synthesis from Scratch for Generalist Interactive Tool-Use Agent Training
Feb 06, 2026Training generalist agents capable of adapting to diverse scenarios requires interactive environments for self-exploration. However, interactive environments remain critically scarce, and existing synthesis methods suffer from significant limitations regarding environmental diversity and scalability. To address these challenges, we introduce ScaleEnv, a framework that constructs fully interactive environments and verifiable tasks entirely from scratch. Specifically, ScaleEnv ensures environment reliability through procedural testing, and guarantees task completeness and solvability via tool dependency graph expansion and executable action verification. By enabling agents to learn through exploration within ScaleEnv, we demonstrate significant performance improvements on unseen, multi-turn tool-use benchmarks such as $τ^2$-Bench and VitaBench, highlighting strong generalization capabilities. Furthermore, we investigate the relationship between increasing number of domains and model generalization performance, providing empirical evidence that scaling environmental diversity is critical for robust agent learning.
CoBA-RL: Capability-Oriented Budget Allocation for Reinforcement Learning in LLMs
Feb 03, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key approach for enhancing LLM reasoning.However, standard frameworks like Group Relative Policy Optimization (GRPO) typically employ a uniform rollout budget, leading to resource inefficiency. Moreover, existing adaptive methods often rely on instance-level metrics, such as task pass rates, failing to capture the model's dynamic learning state. To address these limitations, we propose CoBA-RL, a reinforcement learning algorithm designed to adaptively allocate rollout budgets based on the model's evolving capability. Specifically, CoBA-RL utilizes a Capability-Oriented Value function to map tasks to their potential training gains and employs a heap-based greedy strategy to efficiently self-calibrate the distribution of computational resources to samples with high training value. Extensive experiments demonstrate that our approach effectively orchestrates the trade-off between exploration and exploitation, delivering consistent generalization improvements across multiple challenging benchmarks. These findings underscore that quantifying sample training value and optimizing budget allocation are pivotal for advancing LLM post-training efficiency.
$V_0$: A Generalist Value Model for Any Policy at State Zero
Feb 03, 2026Policy gradient methods rely on a baseline to measure the relative advantage of an action, ensuring the model reinforces behaviors that outperform its current average capability. In the training of Large Language Models (LLMs) using Actor-Critic methods (e.g., PPO), this baseline is typically estimated by a Value Model (Critic) often as large as the policy model itself. However, as the policy continuously evolves, the value model requires expensive, synchronous incremental training to accurately track the shifting capabilities of the policy. To avoid this overhead, Group Relative Policy Optimization (GRPO) eliminates the coupled value model by using the average reward of a group of rollouts as the baseline; yet, this approach necessitates extensive sampling to maintain estimation stability. In this paper, we propose $V_0$, a Generalist Value Model capable of estimating the expected performance of any model on unseen prompts without requiring parameter updates. We reframe value estimation by treating the policy's dynamic capability as an explicit context input; specifically, we leverage a history of instruction-performance pairs to dynamically profile the model, departing from the traditional paradigm that relies on parameter fitting to perceive capability shifts. Focusing on value estimation at State Zero (i.e., the initial prompt, hence $V_0$), our model serves as a critical resource scheduler. During GRPO training, $V_0$ predicts success rates prior to rollout, allowing for efficient sampling budget allocation; during deployment, it functions as a router, dispatching instructions to the most cost-effective and suitable model. Empirical results demonstrate that $V_0$ significantly outperforms heuristic budget allocation and achieves a Pareto-optimal trade-off between performance and cost in LLM routing tasks.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications
Sep 30, 2025As LLM-based agents are increasingly deployed in real-life scenarios, existing benchmarks fail to capture their inherent complexity of handling extensive information, leveraging diverse resources, and managing dynamic user interactions. To address this gap, we introduce VitaBench, a challenging benchmark that evaluates agents on versatile interactive tasks grounded in real-world settings. Drawing from daily applications in food delivery, in-store consumption, and online travel services, VitaBench presents agents with the most complex life-serving simulation environment to date, comprising 66 tools. Through a framework that eliminates domain-specific policies, we enable flexible composition of these scenarios and tools, yielding 100 cross-scenario tasks (main results) and 300 single-scenario tasks. Each task is derived from multiple real user requests and requires agents to reason across temporal and spatial dimensions, utilize complex tool sets, proactively clarify ambiguous instructions, and track shifting user intent throughout multi-turn conversations. Moreover, we propose a rubric-based sliding window evaluator, enabling robust assessment of diverse solution pathways in complex environments and stochastic interactions. Our comprehensive evaluation reveals that even the most advanced models achieve only 30% success rate on cross-scenario tasks, and less than 50% success rate on others. Overall, we believe VitaBench will serve as a valuable resource for advancing the development of AI agents in practical real-world applications. The code, dataset, and leaderboard are available at https://vitabench.github.io/
TSGP: Two-Stage Generative Prompting for Unsupervised Commonsense Question Answering
Nov 24, 2022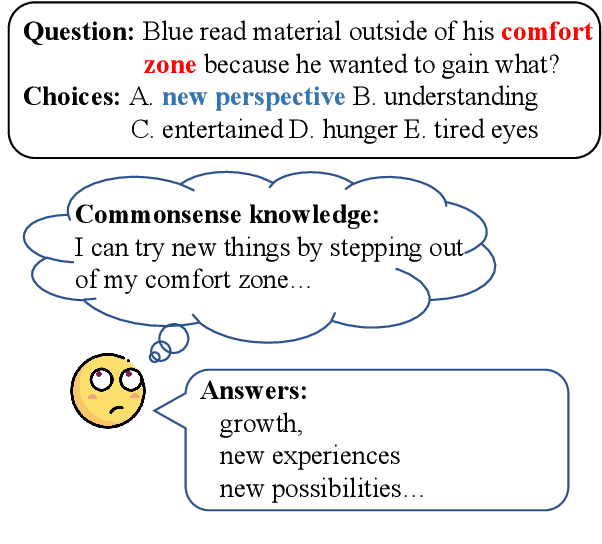
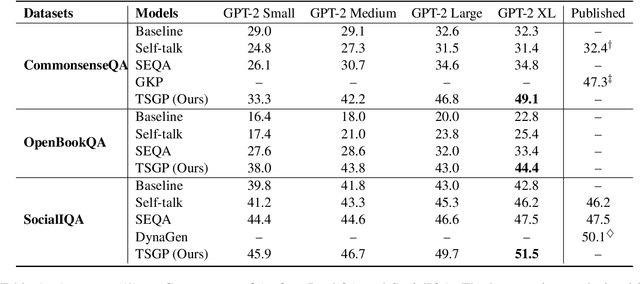
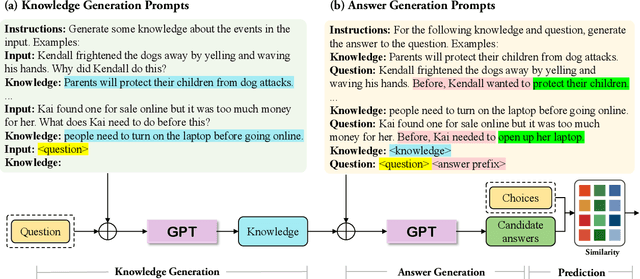

Unsupervised commonsense question answering requires mining effective commonsense knowledge without the rely on the labeled task data. Previous methods typically retrieved from traditional knowledge bases or used pre-trained language models (PrLMs) to generate fixed types of knowledge, which have poor generalization ability. In this paper, we aim to address the above limitation by leveraging the implicit knowledge stored in PrLMs and propose a two-stage prompt-based unsupervised commonsense question answering framework (TSGP). Specifically, we first use knowledge generation prompts to generate the knowledge required for questions with unlimited types and possible candidate answers independent of specified choices. Then, we further utilize answer generation prompts to generate possible candidate answers independent of specified choices. Experimental results and analysis on three different commonsense reasoning tasks, CommonsenseQA, OpenBookQA, and SocialIQA, demonstrate that TSGP significantly improves the reasoning ability of language models in unsupervised settings. Our code is available at: https://github.com/Yueqing-Sun/TSGP.