 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComponent-Aware Structure-Preserving Style Transfer for Satellite Visual Sim2Real Data Construction
May 20, 2026For camera-based satellite visual sensing, Sim2Real data construction requires images that approach real-domain sensor appearance while retaining the annotations inherited from simulation. Real sensor images of satellite targets with reliable pose labels and component-level masks are difficult to acquire at scale, whereas synthetic rendering provides exact geometric annotations but suffers from a visible appearance gap. This paper presents a component-aware structure-preserving style transfer framework for satellite visual synthetic-to-real data construction. The method builds weakly paired real--synthetic samples from calibrated real acquisition, ArUco-based camera-pose measurement, CAD rendering, and component masks. It then extracts part-wise real-domain style codes from unlabeled real images and injects them into corresponding synthetic satellite regions through mask-aligned modulation. To keep the generated images usable for downstream sensor-data supervision, adversarial training is combined with local contrastive consistency, self-regularization, and edge-preserving constraints. Experiments are conducted on 5,000 rendered satellite images and 100 real images captured in a calibrated setup. The real images provide target-domain appearance references and final evaluation images, while the downstream GDRNet pose estimator is trained only on synthetic or translated synthetic images. Compared with representative image-translation baselines, the proposed method achieves the lowest image distribution discrepancy, with an FID of 54.32 and a KID of 0.048. When the translated data are used to train GDRNet in this target-domain adaptation setting, the ADD pass rate improves to 0.260 and the AUC improves to 0.611. These results indicate that component-level appearance transfer can improve annotation-preserving satellite visual Sim2Real data generation in the considered calibrated setup.
HDCNet: A Hybrid Depth Completion Network for Grasping Transparent and Reflective Objects
Nov 10, 2025Depth perception of transparent and reflective objects has long been a critical challenge in robotic manipulation.Conventional depth sensors often fail to provide reliable measurements on such surfaces, limiting the performance of robots in perception and grasping tasks. To address this issue, we propose a novel depth completion network,HDCNet,which integrates the complementary strengths of Transformer,CNN and Mamba architectures.Specifically,the encoder is designed as a dual-branch Transformer-CNN framework to extract modality-specific features. At the shallow layers of the encoder, we introduce a lightweight multimodal fusion module to effectively integrate low-level features. At the network bottleneck,a Transformer-Mamba hybrid fusion module is developed to achieve deep integration of high-level semantic and global contextual information, significantly enhancing depth completion accuracy and robustness. Extensive evaluations on multiple public datasets demonstrate that HDCNet achieves state-of-the-art(SOTA) performance in depth completion tasks.Furthermore,robotic grasping experiments show that HDCNet substantially improves grasp success rates for transparent and reflective objects,achieving up to a 60% increase.
ULC: A Unified and Fine-Grained Controller for Humanoid Loco-Manipulation
Jul 09, 2025



Loco-Manipulation for humanoid robots aims to enable robots to integrate mobility with upper-body tracking capabilities. Most existing approaches adopt hierarchical architectures that decompose control into isolated upper-body (manipulation) and lower-body (locomotion) policies. While this decomposition reduces training complexity, it inherently limits coordination between subsystems and contradicts the unified whole-body control exhibited by humans. We demonstrate that a single unified policy can achieve a combination of tracking accuracy, large workspace, and robustness for humanoid loco-manipulation. We propose the Unified Loco-Manipulation Controller (ULC), a single-policy framework that simultaneously tracks root velocity, root height, torso rotation, and dual-arm joint positions in an end-to-end manner, proving the feasibility of unified control without sacrificing performance. We achieve this unified control through key technologies: sequence skill acquisition for progressive learning complexity, residual action modeling for fine-grained control adjustments, command polynomial interpolation for smooth motion transitions, random delay release for robustness to deploy variations, load randomization for generalization to external disturbances, and center-of-gravity tracking for providing explicit policy gradients to maintain stability. We validate our method on the Unitree G1 humanoid robot with 3-DOF (degrees-of-freedom) waist. Compared with strong baselines, ULC shows better tracking performance to disentangled methods and demonstrating larger workspace coverage. The unified dual-arm tracking enables precise manipulation under external loads while maintaining coordinated whole-body control for complex loco-manipulation tasks.
DCIRNet: Depth Completion with Iterative Refinement for Dexterous Grasping of Transparent and Reflective Objects
Jun 11, 2025Transparent and reflective objects in everyday environments pose significant challenges for depth sensors due to their unique visual properties, such as specular reflections and light transmission. These characteristics often lead to incomplete or inaccurate depth estimation, which severely impacts downstream geometry-based vision tasks, including object recognition, scene reconstruction, and robotic manipulation. To address the issue of missing depth information in transparent and reflective objects, we propose DCIRNet, a novel multimodal depth completion network that effectively integrates RGB images and depth maps to enhance depth estimation quality. Our approach incorporates an innovative multimodal feature fusion module designed to extract complementary information between RGB images and incomplete depth maps. Furthermore, we introduce a multi-stage supervision and depth refinement strategy that progressively improves depth completion and effectively mitigates the issue of blurred object boundaries. We integrate our depth completion model into dexterous grasping frameworks and achieve a $44\%$ improvement in the grasp success rate for transparent and reflective objects. We conduct extensive experiments on public datasets, where DCIRNet demonstrates superior performance. The experimental results validate the effectiveness of our approach and confirm its strong generalization capability across various transparent and reflective objects.
HTMNet: A Hybrid Network with Transformer-Mamba Bottleneck Multimodal Fusion for Transparent and Reflective Objects Depth Completion
May 28, 2025Transparent and reflective objects pose significant challenges for depth sensors, resulting in incomplete depth information that adversely affects downstream robotic perception and manipulation tasks. To address this issue, we propose HTMNet, a novel hybrid model integrating Transformer, CNN, and Mamba architectures. The encoder is based on a dual-branch CNN-Transformer framework, the bottleneck fusion module adopts a Transformer-Mamba architecture, and the decoder is built upon a multi-scale fusion module. We introduce a novel multimodal fusion module grounded in self-attention mechanisms and state space models, marking the first application of the Mamba architecture in the field of transparent object depth completion and revealing its promising potential. Additionally, we design an innovative multi-scale fusion module for the decoder that combines channel attention, spatial attention, and multi-scale feature extraction techniques to effectively integrate multi-scale features through a down-fusion strategy. Extensive evaluations on multiple public datasets demonstrate that our model achieves state-of-the-art(SOTA) performance, validating the effectiveness of our approach.
Learning Humanoid Locomotion with World Model Reconstruction
Feb 22, 2025Humanoid robots are designed to navigate environments accessible to humans using their legs. However, classical research has primarily focused on controlled laboratory settings, resulting in a gap in developing controllers for navigating complex real-world terrains. This challenge mainly arises from the limitations and noise in sensor data, which hinder the robot's understanding of itself and the environment. In this study, we introduce World Model Reconstruction (WMR), an end-to-end learning-based approach for blind humanoid locomotion across challenging terrains. We propose training an estimator to explicitly reconstruct the world state and utilize it to enhance the locomotion policy. The locomotion policy takes inputs entirely from the reconstructed information. The policy and the estimator are trained jointly; however, the gradient between them is intentionally cut off. This ensures that the estimator focuses solely on world reconstruction, independent of the locomotion policy's updates. We evaluated our model on rough, deformable, and slippery surfaces in real-world scenarios, demonstrating robust adaptability and resistance to interference. The robot successfully completed a 3.2 km hike without any human assistance, mastering terrains covered with ice and snow.
A Fast and Optimal Learning-based Path Planning Method for Planetary Rovers
Aug 09, 2023Intelligent autonomous path planning is crucial to improve the exploration efficiency of planetary rovers. In this paper, we propose a learning-based method to quickly search for optimal paths in an elevation map, which is called NNPP. The NNPP model learns semantic information about start and goal locations, as well as map representations, from numerous pre-annotated optimal path demonstrations, and produces a probabilistic distribution over each pixel representing the likelihood of it belonging to an optimal path on the map. More specifically, the paper computes the traversal cost for each grid cell from the slope, roughness and elevation difference obtained from the DEM. Subsequently, the start and goal locations are encoded using a Gaussian distribution and different location encoding parameters are analyzed for their effect on model performance. After training, the NNPP model is able to perform path planning on novel maps. Experiments show that the guidance field generated by the NNPP model can significantly reduce the search time for optimal paths under the same hardware conditions, and the advantage of NNPP increases with the scale of the map.
Prototype Design and Efficiency Analysis of a Novel Robot Drive Based on 3K-H-V Topology
Oct 05, 2022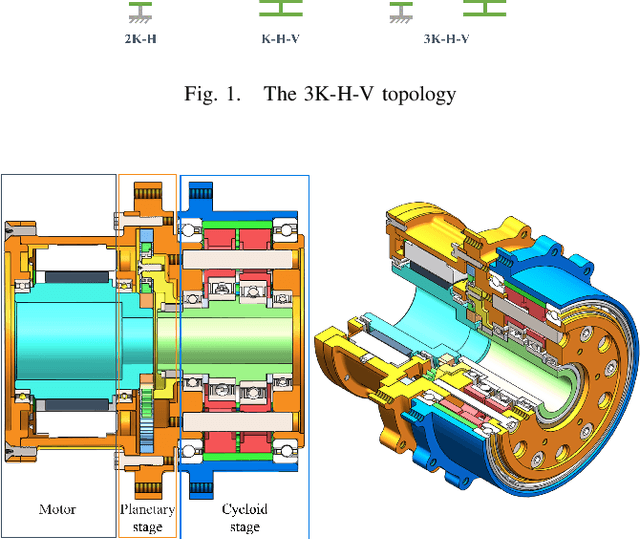
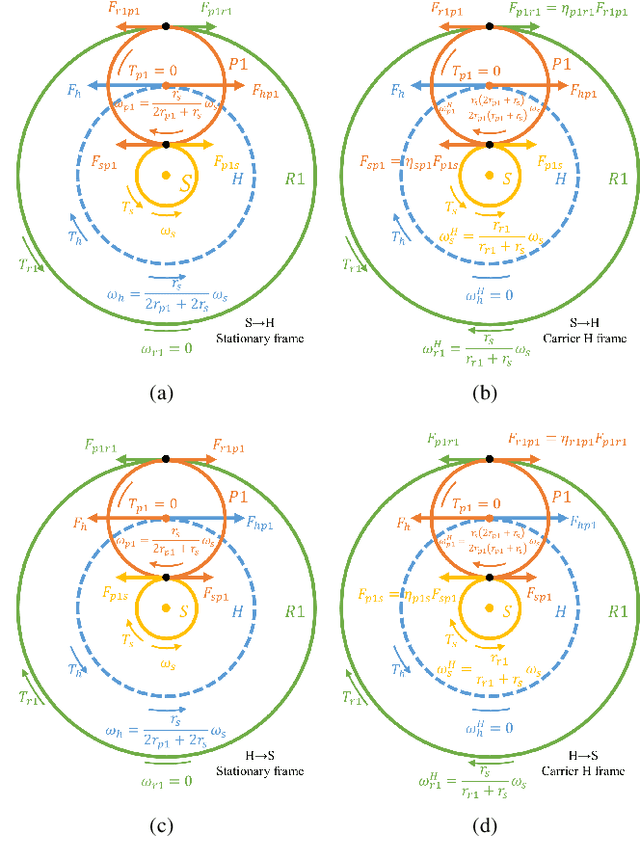
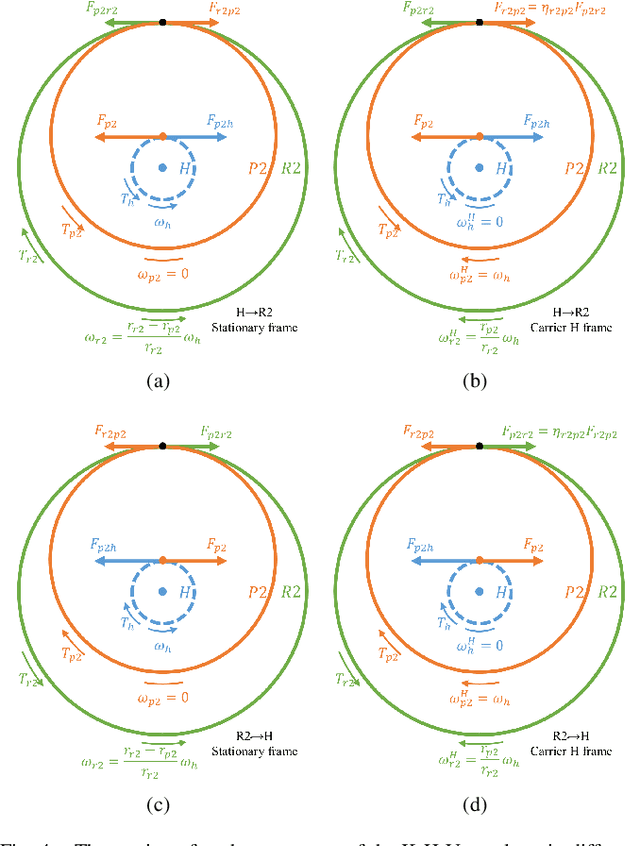
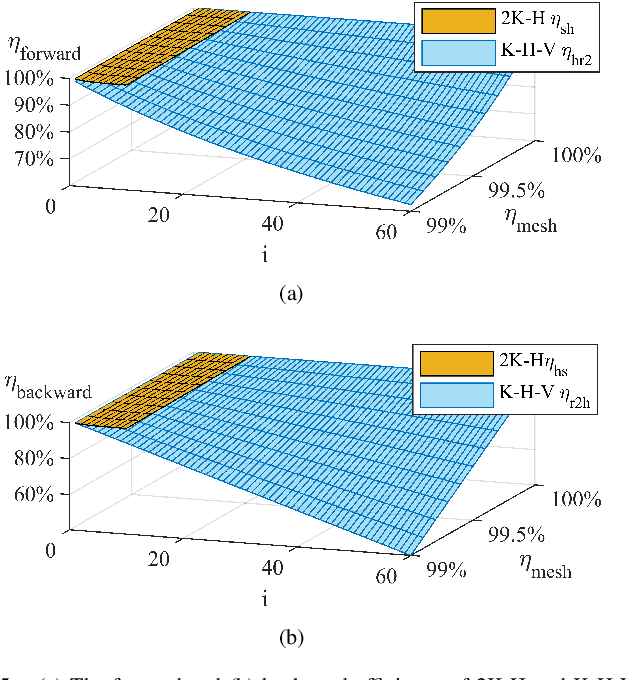
Robot actuators directly affect the performance of robots, and robot drives directly affect the performance of robot actuators. With the development of robotics, robots have put higher requirements on robot drives, such as high stiffness, high accuracy, high loading, high efficiency, low backlash, compact size, and hollow structure. In order to meet the demand development of robot actuators, this research base proposes a new robot drive based on 3K-H-V topology using involute and cycloidal gear shapes, planetary cycloidal drive, from the perspective of drive topology and through the design idea of decoupling. In this study, the reduction ratio and the efficiency model of the 3K-H-V topology were analyzed, and a prototype planetary cycloidal actuator was designed. The feasibility of the drive is initially verified by experimentally concluding that the PCA has a hollow structure, compact size, and high torque density (69 kg/Nm).