 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrödinger-ANI: An Eight-Element Neural Network Interaction Potential with Greatly Expanded Coverage of Druglike Chemical Space
Nov 22, 2019
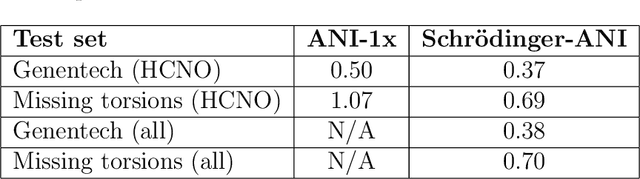
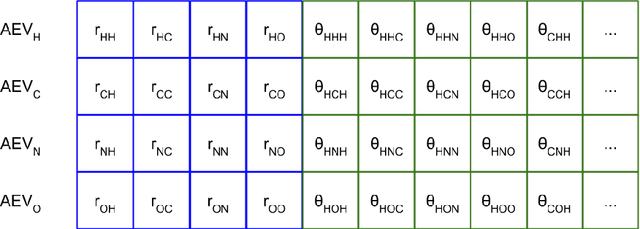
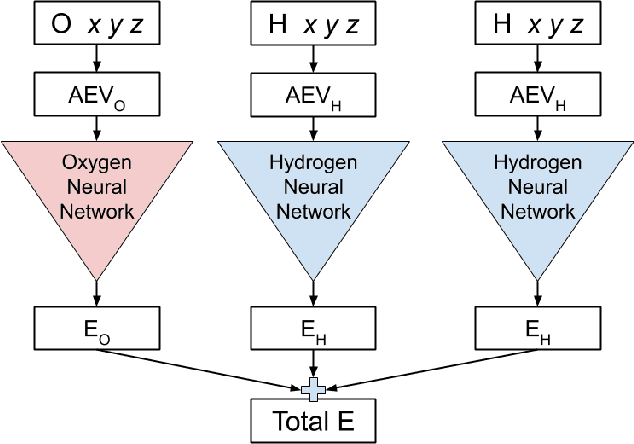
We have developed a neural network potential energy function for use in drug discovery, with chemical element support extended from 41% to 94% of druglike molecules based on ChEMBL. We expand on the work of Smith et al., with their highly accurate network for the elements H, C, N, O, creating a network for H, C, N, O, S, F, Cl, P. We focus particularly on the calculation of relative conformer energies, for which we show that our new potential energy function has an RMSE of 0.70 kcal/mol for prospective druglike molecule conformers, substantially better than the previous state of the art. The speed and accuracy of this model could greatly accelerate the parameterization of protein-ligand binding free energy calculations for novel druglike molecules.
MoleculeNet: A Benchmark for Molecular Machine Learning
Oct 26, 2018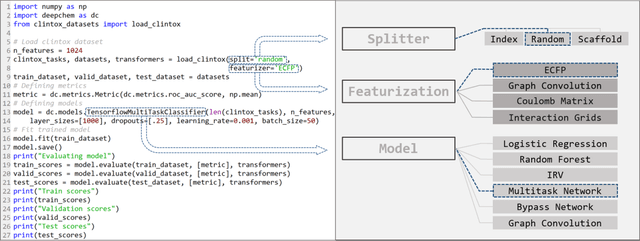
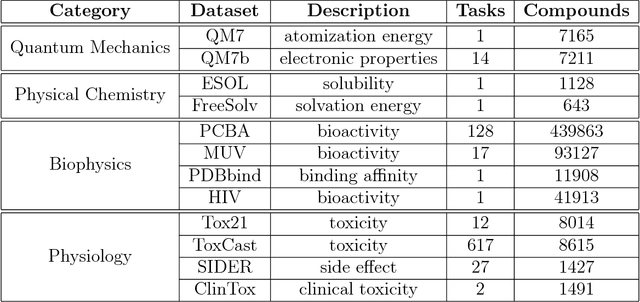
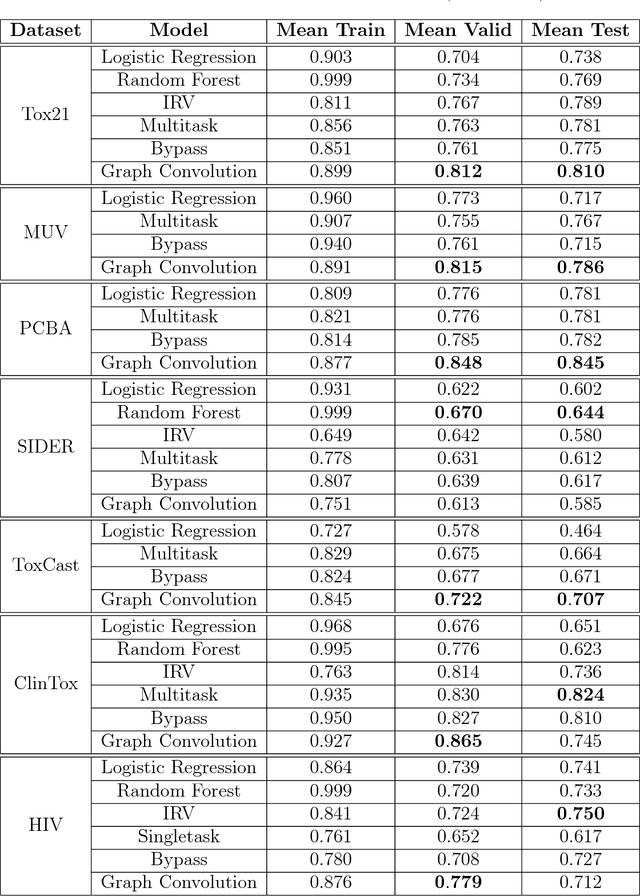
Molecular machine learning has been maturing rapidly over the last few years. Improved methods and the presence of larger datasets have enabled machine learning algorithms to make increasingly accurate predictions about molecular properties. However, algorithmic progress has been limited due to the lack of a standard benchmark to compare the efficacy of proposed methods; most new algorithms are benchmarked on different datasets making it challenging to gauge the quality of proposed methods. This work introduces MoleculeNet, a large scale benchmark for molecular machine learning. MoleculeNet curates multiple public datasets, establishes metrics for evaluation, and offers high quality open-source implementations of multiple previously proposed molecular featurization and learning algorithms (released as part of the DeepChem open source library). MoleculeNet benchmarks demonstrate that learnable representations are powerful tools for molecular machine learning and broadly offer the best performance. However, this result comes with caveats. Learnable representations still struggle to deal with complex tasks under data scarcity and highly imbalanced classification. For quantum mechanical and biophysical datasets, the use of physics-aware featurizations can be more important than choice of particular learning algorithm.