 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoes of the past: A unified perspective on fading memory and echo states
Aug 26, 2025Recurrent neural networks (RNNs) have become increasingly popular in information processing tasks involving time series and temporal data. A fundamental property of RNNs is their ability to create reliable input/output responses, often linked to how the network handles its memory of the information it processed. Various notions have been proposed to conceptualize the behavior of memory in RNNs, including steady states, echo states, state forgetting, input forgetting, and fading memory. Although these notions are often used interchangeably, their precise relationships remain unclear. This work aims to unify these notions in a common language, derive new implications and equivalences between them, and provide alternative proofs to some existing results. By clarifying the relationships between these concepts, this research contributes to a deeper understanding of RNNs and their temporal information processing capabilities.
Stochastic dynamics learning with state-space systems
Aug 11, 2025This work advances the theoretical foundations of reservoir computing (RC) by providing a unified treatment of fading memory and the echo state property (ESP) in both deterministic and stochastic settings. We investigate state-space systems, a central model class in time series learning, and establish that fading memory and solution stability hold generically -- even in the absence of the ESP -- offering a robust explanation for the empirical success of RC models without strict contractivity conditions. In the stochastic case, we critically assess stochastic echo states, proposing a novel distributional perspective rooted in attractor dynamics on the space of probability distributions, which leads to a rich and coherent theory. Our results extend and generalize previous work on non-autonomous dynamical systems, offering new insights into causality, stability, and memory in RC models. This lays the groundwork for reliable generative modeling of temporal data in both deterministic and stochastic regimes.
Memory Capacity of Nonlinear Recurrent Networks: Is it Informative?
Feb 07, 2025The total memory capacity (MC) of linear recurrent neural networks (RNNs) has been proven to be equal to the rank of the corresponding Kalman controllability matrix, and it is almost surely maximal for connectivity and input weight matrices drawn from regular distributions. This fact questions the usefulness of this metric in distinguishing the performance of linear RNNs in the processing of stochastic signals. This note shows that the MC of random nonlinear RNNs yields arbitrary values within established upper and lower bounds depending just on the input process scale. This confirms that the existing definition of MC in linear and nonlinear cases has no practical value.
Infinite-dimensional next-generation reservoir computing
Dec 13, 2024Next-generation reservoir computing (NG-RC) has attracted much attention due to its excellent performance in spatio-temporal forecasting of complex systems and its ease of implementation. This paper shows that NG-RC can be encoded as a kernel ridge regression that makes training efficient and feasible even when the space of chosen polynomial features is very large. Additionally, an extension to an infinite number of covariates is possible, which makes the methodology agnostic with respect to the lags into the past that are considered as explanatory factors, as well as with respect to the number of polynomial covariates, an important hyperparameter in traditional NG-RC. We show that this approach has solid theoretical backing and good behavior based on kernel universality properties previously established in the literature. Various numerical illustrations show that these generalizations of NG-RC outperform the traditional approach in several forecasting applications.
Fading memory and the convolution theorem
Aug 14, 2024Several topological and analytical notions of continuity and fading memory for causal and time-invariant filters are introduced, and the relations between them are analysed. A significant generalization of the convolution theorem that establishes the equivalence between the fading memory property and the availability of convolution representations of linear filters is proved. This result extends a previous such characterization to a complete array of weighted norms in the definition of the fading memory property. Additionally, the main theorem shows that the availability of convolution representations can be characterized, at least when the codomain is finite-dimensional, not only by the fading memory property but also by the reunion of two purely topological notions that are called minimal continuity and minimal fading memory property. Finally, when the input space and the codomain of a linear functional are Hilbert spaces, it is shown that minimal continuity and the minimal fading memory property guarantee the existence of interesting embeddings of the associated reproducing kernel Hilbert spaces and approximation results of solutions of kernel regressions in the presence of finite data sets.
State-Space Systems as Dynamic Generative Models
Apr 12, 2024A probabilistic framework to study the dependence structure induced by deterministic discrete-time state-space systems between input and output processes is introduced. General sufficient conditions are formulated under which output processes exist and are unique once an input process has been fixed, a property that in the deterministic state-space literature is known as the echo state property. When those conditions are satisfied, the given state-space system becomes a generative model for probabilistic dependences between two sequence spaces. Moreover, those conditions guarantee that the output depends continuously on the input when using the Wasserstein metric. The output processes whose existence is proved are shown to be causal in a specific sense and to generalize those studied in purely deterministic situations. The results in this paper constitute a significant stochastic generalization of sufficient conditions for the deterministic echo state property to hold, in the sense that the stochastic echo state property can be satisfied under contractivity conditions that are strictly weaker than those in deterministic situations. This means that state-space systems can induce a purely probabilistic dependence structure between input and output sequence spaces even when there is no functional relation between those two spaces.
A Structure-Preserving Kernel Method for Learning Hamiltonian Systems
Mar 15, 2024



A structure-preserving kernel ridge regression method is presented that allows the recovery of potentially high-dimensional and nonlinear Hamiltonian functions out of datasets made of noisy observations of Hamiltonian vector fields. The method proposes a closed-form solution that yields excellent numerical performances that surpass other techniques proposed in the literature in this setup. From the methodological point of view, the paper extends kernel regression methods to problems in which loss functions involving linear functions of gradients are required and, in particular, a differential reproducing property and a Representer Theorem are proved in this context. The relation between the structure-preserving kernel estimator and the Gaussian posterior mean estimator is analyzed. A full error analysis is conducted that provides convergence rates using fixed and adaptive regularization parameters. The good performance of the proposed estimator is illustrated with various numerical experiments.
Invariant kernels on Riemannian symmetric spaces: a harmonic-analytic approach
Oct 30, 2023

This work aims to prove that the classical Gaussian kernel, when defined on a non-Euclidean symmetric space, is never positive-definite for any choice of parameter. To achieve this goal, the paper develops new geometric and analytical arguments. These provide a rigorous characterization of the positive-definiteness of the Gaussian kernel, which is complete but for a limited number of scenarios in low dimensions that are treated by numerical computations. Chief among these results are the L$^{\!\scriptscriptstyle p}$-$\hspace{0.02cm}$Godement theorems (where $p = 1,2$), which provide verifiable necessary and sufficient conditions for a kernel defined on a symmetric space of non-compact type to be positive-definite. A celebrated theorem, sometimes called the Bochner-Godement theorem, already gives such conditions and is far more general in its scope, but is especially hard to apply. Beyond the connection with the Gaussian kernel, the new results in this work lay out a blueprint for the study of invariant kernels on symmetric spaces, bringing forth specific harmonic analysis tools that suggest many future applications.
Geometric Learning with Positively Decomposable Kernels
Oct 20, 2023Kernel methods are powerful tools in machine learning. Classical kernel methods are based on positive-definite kernels, which map data spaces into reproducing kernel Hilbert spaces (RKHS). For non-Euclidean data spaces, positive-definite kernels are difficult to come by. In this case, we propose the use of reproducing kernel Krein space (RKKS) based methods, which require only kernels that admit a positive decomposition. We show that one does not need to access this decomposition in order to learn in RKKS. We then investigate the conditions under which a kernel is positively decomposable. We show that invariant kernels admit a positive decomposition on homogeneous spaces under tractable regularity assumptions. This makes them much easier to construct than positive-definite kernels, providing a route for learning with kernels for non-Euclidean data. By the same token, this provides theoretical foundations for RKKS-based methods in general.
Learning multi-modal generative models with permutation-invariant encoders and tighter variational bounds
Sep 01, 2023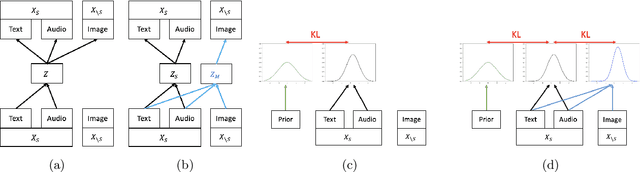

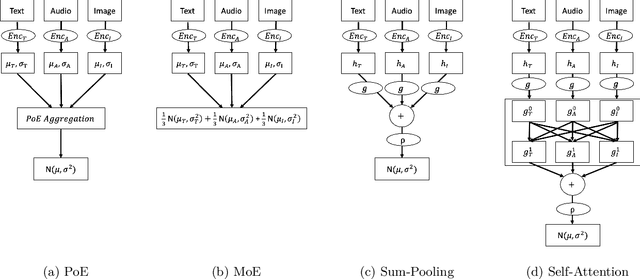
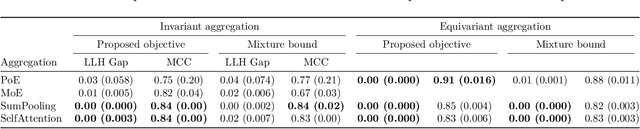
Devising deep latent variable models for multi-modal data has been a long-standing theme in machine learning research. Multi-modal Variational Autoencoders (VAEs) have been a popular generative model class that learns latent representations which jointly explain multiple modalities. Various objective functions for such models have been suggested, often motivated as lower bounds on the multi-modal data log-likelihood or from information-theoretic considerations. In order to encode latent variables from different modality subsets, Product-of-Experts (PoE) or Mixture-of-Experts (MoE) aggregation schemes have been routinely used and shown to yield different trade-offs, for instance, regarding their generative quality or consistency across multiple modalities. In this work, we consider a variational bound that can tightly lower bound the data log-likelihood. We develop more flexible aggregation schemes that generalise PoE or MoE approaches by combining encoded features from different modalities based on permutation-invariant neural networks. Our numerical experiments illustrate trade-offs for multi-modal variational bounds and various aggregation schemes. We show that tighter variational bounds and more flexible aggregation models can become beneficial when one wants to approximate the true joint distribution over observed modalities and latent variables in identifiable models.