 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Many Models, One: Macroeconomic Forecasting with Reservoir Ensembles
Dec 15, 2025Model combination is a powerful approach to achieve superior performance with a set of models than by just selecting any single one. We study both theoretically and empirically the effectiveness of ensembles of Multi-Frequency Echo State Networks (MFESNs), which have been shown to achieve state-of-the-art macroeconomic time series forecasting results (Ballarin et al., 2024a). Hedge and Follow-the-Leader schemes are discussed, and their online learning guarantees are extended to the case of dependent data. In applications, our proposed Ensemble Echo State Networks show significantly improved predictive performance compared to individual MFESN models.
Prob-GParareal: A Probabilistic Numerical Parallel-in-Time Solver for Differential Equations
Sep 04, 2025We introduce Prob-GParareal, a probabilistic extension of the GParareal algorithm designed to provide uncertainty quantification for the Parallel-in-Time (PinT) solution of (ordinary and partial) differential equations (ODEs, PDEs). The method employs Gaussian processes (GPs) to model the Parareal correction function, as GParareal does, further enabling the propagation of numerical uncertainty across time and yielding probabilistic forecasts of system's evolution. Furthermore, Prob-GParareal accommodates probabilistic initial conditions and maintains compatibility with classical numerical solvers, ensuring its straightforward integration into existing Parareal frameworks. Here, we first conduct a theoretical analysis of the computational complexity and derive error bounds of Prob-GParareal. Then, we numerically demonstrate the accuracy and robustness of the proposed algorithm on five benchmark ODE systems, including chaotic, stiff, and bifurcation problems. To showcase the flexibility and potential scalability of the proposed algorithm, we also consider Prob-nnGParareal, a variant obtained by replacing the GPs in Parareal with the nearest-neighbors GPs, illustrating its increased performance on an additional PDE example. This work bridges a critical gap in the development of probabilistic counterparts to established PinT methods.
Memory Capacity of Nonlinear Recurrent Networks: Is it Informative?
Feb 07, 2025The total memory capacity (MC) of linear recurrent neural networks (RNNs) has been proven to be equal to the rank of the corresponding Kalman controllability matrix, and it is almost surely maximal for connectivity and input weight matrices drawn from regular distributions. This fact questions the usefulness of this metric in distinguishing the performance of linear RNNs in the processing of stochastic signals. This note shows that the MC of random nonlinear RNNs yields arbitrary values within established upper and lower bounds depending just on the input process scale. This confirms that the existing definition of MC in linear and nonlinear cases has no practical value.
Infinite-dimensional next-generation reservoir computing
Dec 13, 2024Next-generation reservoir computing (NG-RC) has attracted much attention due to its excellent performance in spatio-temporal forecasting of complex systems and its ease of implementation. This paper shows that NG-RC can be encoded as a kernel ridge regression that makes training efficient and feasible even when the space of chosen polynomial features is very large. Additionally, an extension to an infinite number of covariates is possible, which makes the methodology agnostic with respect to the lags into the past that are considered as explanatory factors, as well as with respect to the number of polynomial covariates, an important hyperparameter in traditional NG-RC. We show that this approach has solid theoretical backing and good behavior based on kernel universality properties previously established in the literature. Various numerical illustrations show that these generalizations of NG-RC outperform the traditional approach in several forecasting applications.
RandNet-Parareal: a time-parallel PDE solver using Random Neural Networks
Nov 09, 2024Parallel-in-time (PinT) techniques have been proposed to solve systems of time-dependent differential equations by parallelizing the temporal domain. Among them, Parareal computes the solution sequentially using an inaccurate (fast) solver, and then "corrects" it using an accurate (slow) integrator that runs in parallel across temporal subintervals. This work introduces RandNet-Parareal, a novel method to learn the discrepancy between the coarse and fine solutions using random neural networks (RandNets). RandNet-Parareal achieves speed gains up to x125 and x22 compared to the fine solver run serially and Parareal, respectively. Beyond theoretical guarantees of RandNets as universal approximators, these models are quick to train, allowing the PinT solution of partial differential equations on a spatial mesh of up to $10^5$ points with minimal overhead, dramatically increasing the scalability of existing PinT approaches. RandNet-Parareal's numerical performance is illustrated on systems of real-world significance, such as the viscous Burgers' equation, the Diffusion-Reaction equation, the two- and three-dimensional Brusselator, and the shallow water equation.
Memory of recurrent networks: Do we compute it right?
May 02, 2023Numerical evaluations of the memory capacity (MC) of recurrent neural networks reported in the literature often contradict well-established theoretical bounds. In this paper, we study the case of linear echo state networks, for which the total memory capacity has been proven to be equal to the rank of the corresponding Kalman controllability matrix. We shed light on various reasons for the inaccurate numerical estimations of the memory, and we show that these issues, often overlooked in the recent literature, are of an exclusively numerical nature. More explicitly, we prove that when the Krylov structure of the linear MC is ignored, a gap between the theoretical MC and its empirical counterpart is introduced. As a solution, we develop robust numerical approaches by exploiting a result of MC neutrality with respect to the input mask matrix. Simulations show that the memory curves that are recovered using the proposed methods fully agree with the theory.
Infinite-dimensional reservoir computing
Apr 02, 2023Reservoir computing approximation and generalization bounds are proved for a new concept class of input/output systems that extends the so-called generalized Barron functionals to a dynamic context. This new class is characterized by the readouts with a certain integral representation built on infinite-dimensional state-space systems. It is shown that this class is very rich and possesses useful features and universal approximation properties. The reservoir architectures used for the approximation and estimation of elements in the new class are randomly generated echo state networks with either linear or ReLU activation functions. Their readouts are built using randomly generated neural networks in which only the output layer is trained (extreme learning machines or random feature neural networks). The results in the paper yield a fully implementable recurrent neural network-based learning algorithm with provable convergence guarantees that do not suffer from the curse of dimensionality.
Reservoir kernels and Volterra series
Dec 30, 2022A universal kernel is constructed whose sections approximate any causal and time-invariant filter in the fading memory category with inputs and outputs in a finite-dimensional Euclidean space. This kernel is built using the reservoir functional associated with a state-space representation of the Volterra series expansion available for any analytic fading memory filter. It is hence called the Volterra reservoir kernel. Even though the state-space representation and the corresponding reservoir feature map are defined on an infinite-dimensional tensor algebra space, the kernel map is characterized by explicit recursions that are readily computable for specific data sets when employed in estimation problems using the representer theorem. We showcase the performance of the Volterra reservoir kernel in a popular data science application in relation to bitcoin price prediction.
Learning strange attractors with reservoir systems
Aug 11, 2021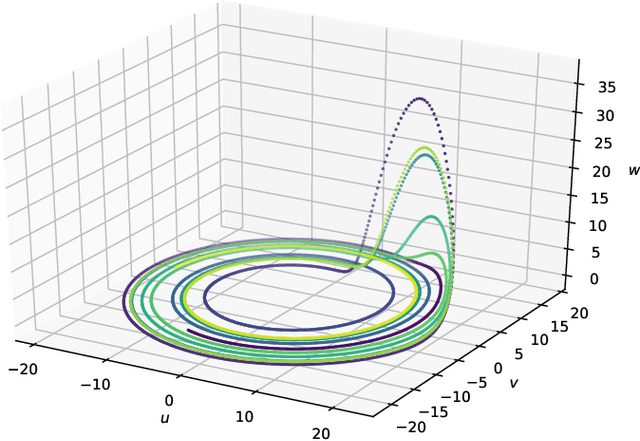



This paper shows that the celebrated Embedding Theorem of Takens is a particular case of a much more general statement according to which, randomly generated linear state-space representations of generic observations of an invertible dynamical system carry in their wake an embedding of the phase space dynamics into the chosen Euclidean state space. This embedding coincides with a natural generalized synchronization that arises in this setup and that yields a topological conjugacy between the state-space dynamics driven by the generic observations of the dynamical system and the dynamical system itself. This result provides additional tools for the representation, learning, and analysis of chaotic attractors and sheds additional light on the reservoir computing phenomenon that appears in the context of recurrent neural networks.
Dimension reduction in recurrent networks by canonicalization
Jul 23, 2020Many recurrent neural network machine learning paradigms can be formulated using state-space representations. The classical notion of canonical state-space realization is adapted in this paper to accommodate semi-infinite inputs so that it can be used as a dimension reduction tool in the recurrent networks setup. The so called input forgetting property is identified as the key hypothesis that guarantees the existence and uniqueness (up to system isomorphisms) of canonical realizations for causal and time-invariant input/output systems with semi-infinite inputs. A second result uses the notion of optimal reduction borrowed from the theory of symmetric Hamiltonian systems to construct canonical realizations out of input forgetting but not necessarily canonical ones. These two procedures are implemented and studied in detail in the framework of linear fading memory input/output systems.