 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Creative Optimization for E-Commerce Advertising
Feb 28, 2021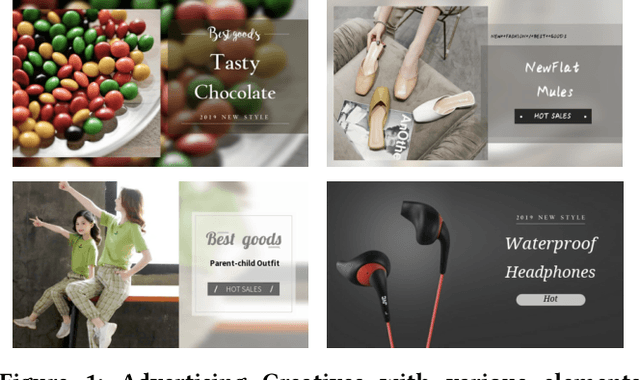

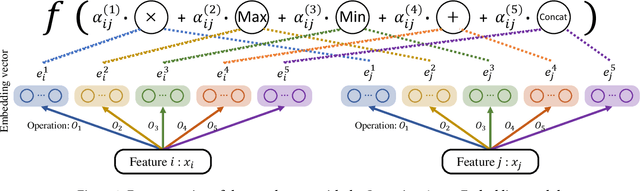
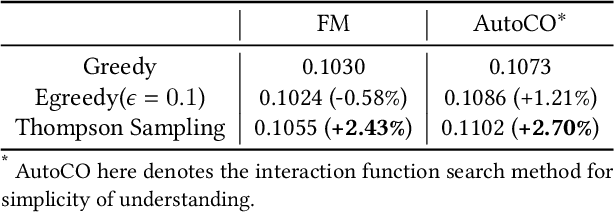
Advertising creatives are ubiquitous in E-commerce advertisements and aesthetic creatives may improve the click-through rate (CTR) of the products. Nowadays smart advertisement platforms provide the function of compositing creatives based on source materials provided by advertisers. Since a great number of creatives can be generated, it is difficult to accurately predict their CTR given a limited amount of feedback. Factorization machine (FM), which models inner product interaction between features, can be applied for the CTR prediction of creatives. However, interactions between creative elements may be more complex than the inner product, and the FM-estimated CTR may be of high variance due to limited feedback. To address these two issues, we propose an Automated Creative Optimization (AutoCO) framework to model complex interaction between creative elements and to balance between exploration and exploitation. Specifically, motivated by AutoML, we propose one-shot search algorithms for searching effective interaction functions between elements. We then develop stochastic variational inference to estimate the posterior distribution of parameters based on the reparameterization trick, and apply Thompson Sampling for efficiently exploring potentially better creatives. We evaluate the proposed method with both a synthetic dataset and two public datasets. The experimental results show our method can outperform competing baselines with respect to cumulative regret. The online A/B test shows our method leads to a 7 increase in CTR compared to the baseline.
Automatic Data Augmentation for 3D Medical Image Segmentation
Oct 07, 2020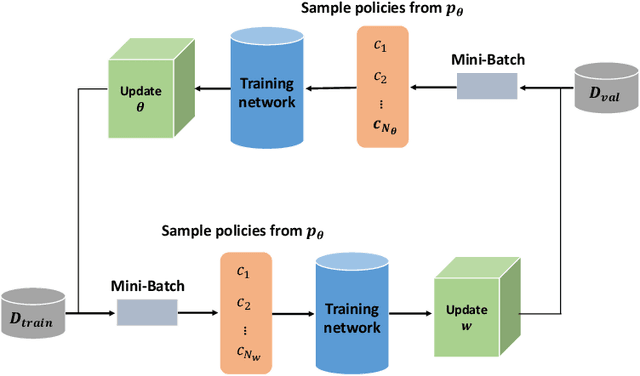
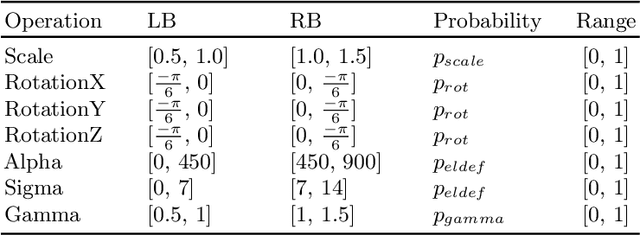
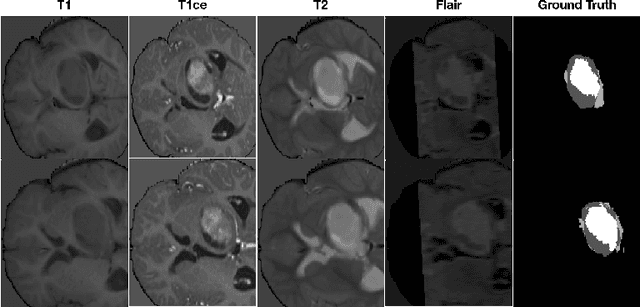
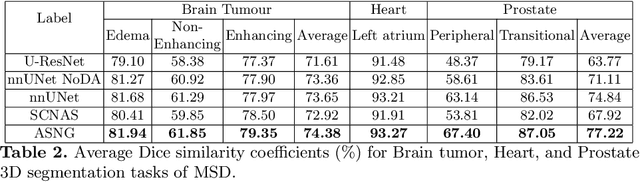
Data augmentation is an effective and universal technique for improving generalization performance of deep neural networks. It could enrich diversity of training samples that is essential in medical image segmentation tasks because 1) the scale of medical image dataset is typically smaller, which may increase the risk of overfitting; 2) the shape and modality of different objects such as organs or tumors are unique, thus requiring customized data augmentation policy. However, most data augmentation implementations are hand-crafted and suboptimal in medical image processing. To fully exploit the potential of data augmentation, we propose an efficient algorithm to automatically search for the optimal augmentation strategies. We formulate the coupled optimization w.r.t. network weights and augmentation parameters into a differentiable form by means of stochastic relaxation. This formulation allows us to apply alternative gradient-based methods to solve it, i.e. stochastic natural gradient method with adaptive step-size. To the best of our knowledge, it is the first time that differentiable automatic data augmentation is employed in medical image segmentation tasks. Our numerical experiments demonstrate that the proposed approach significantly outperforms existing build-in data augmentation of state-of-the-art models.
Differentiable Neural Architecture Search via Proximal Iterations
May 30, 2019
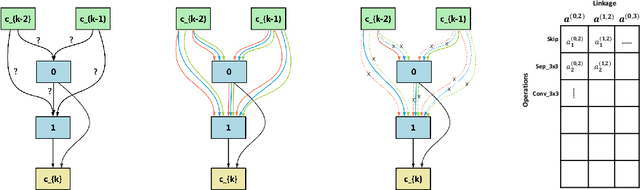
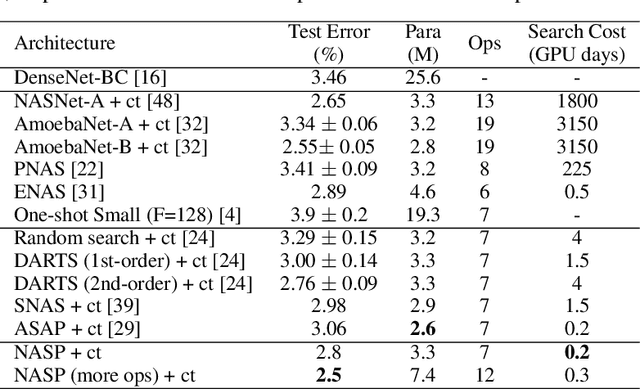
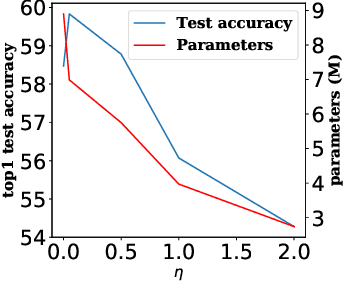
Neural architecture search (NAS) recently attracts much research attention because of its ability to identify better architectures than handcrafted ones. However, many NAS methods, which optimize the search process in a discrete search space, need many GPU days for convergence. Recently, DARTS, which constructs a differentiable search space and then optimizes it by gradient descent, can obtain high-performance architecture and reduces the search time to several days. However, DARTS is still slow as it updates an ensemble of all operations and keeps only one after convergence. Besides, DARTS can converge to inferior architectures due to the strong correlation among operations. In this paper, we propose a new differentiable Neural Architecture Search method based on Proximal gradient descent (denoted as NASP). Different from DARTS, NASP reformulates the search process as an optimization problem with a constraint that only one operation is allowed to be updated during forward and backward propagation. Since the constraint is hard to deal with, we propose a new algorithm inspired by proximal iterations to solve it. Experiments on various tasks demonstrate that NASP can obtain high-performance architectures with 10 times of speedup on the computational time than DARTS.
Bayesian Optimized Continual Learning with Attention Mechanism
May 10, 2019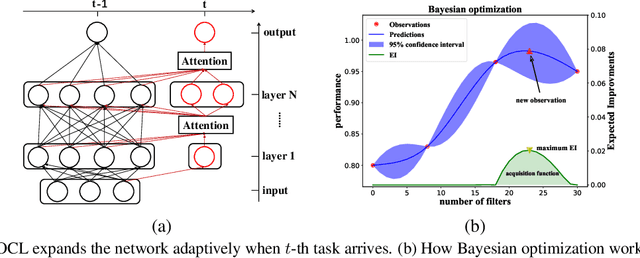
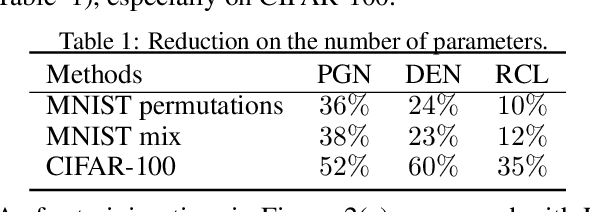
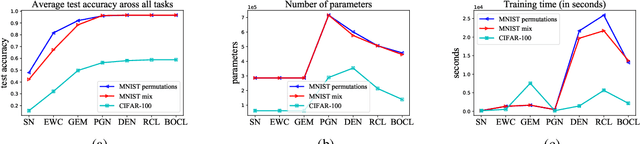
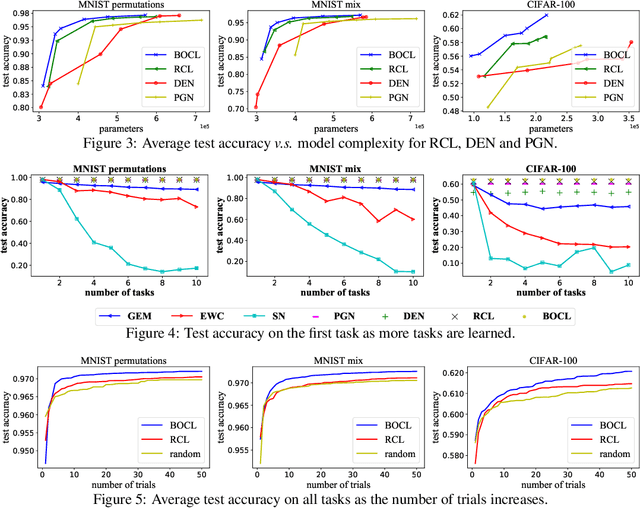
Though neural networks have achieved much progress in various applications, it is still highly challenging for them to learn from a continuous stream of tasks without forgetting. Continual learning, a new learning paradigm, aims to solve this issue. In this work, we propose a new model for continual learning, called Bayesian Optimized Continual Learning with Attention Mechanism (BOCL) that dynamically expands the network capacity upon the arrival of new tasks by Bayesian optimization and selectively utilizes previous knowledge (e.g. feature maps of previous tasks) via attention mechanism. Our experiments on variants of MNIST and CIFAR-100 demonstrate that our methods outperform the state-of-the-art in preventing catastrophic forgetting and fitting new tasks better.
Reinforced Continual Learning
May 31, 2018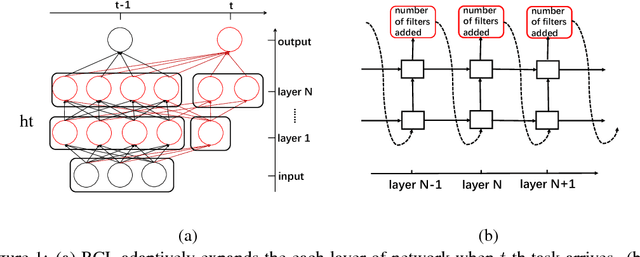
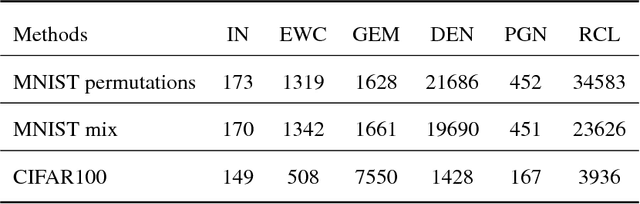
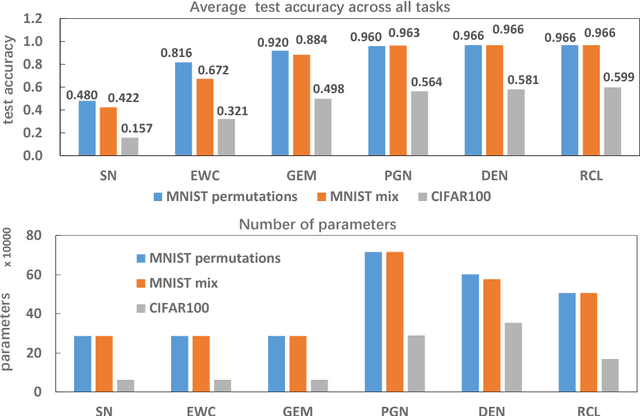
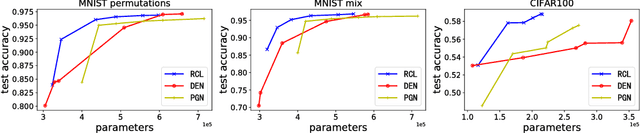
Most artificial intelligence models have limiting ability to solve new tasks faster, without forgetting previously acquired knowledge. The recently emerging paradigm of continual learning aims to solve this issue, in which the model learns various tasks in a sequential fashion. In this work, a novel approach for continual learning is proposed, which searches for the best neural architecture for each coming task via sophisticatedly designed reinforcement learning strategies. We name it as Reinforced Continual Learning. Our method not only has good performance on preventing catastrophic forgetting but also fits new tasks well. The experiments on sequential classification tasks for variants of MNIST and CIFAR-100 datasets demonstrate that the proposed approach outperforms existing continual learning alternatives for deep networks.