 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaiT: Sparse Vision Transformers through Adaptive Token Pruning
Oct 11, 2022
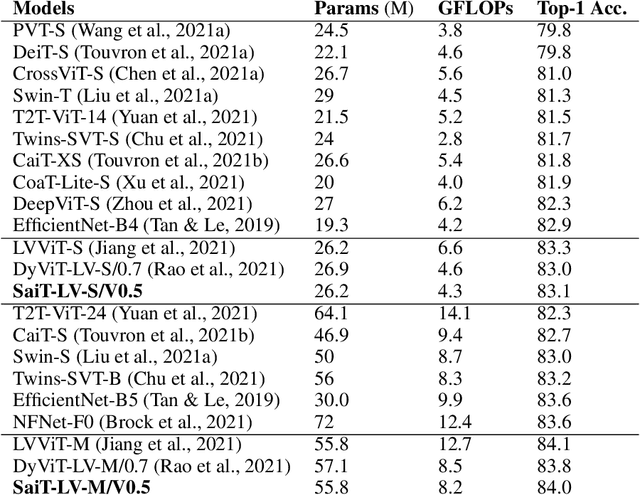
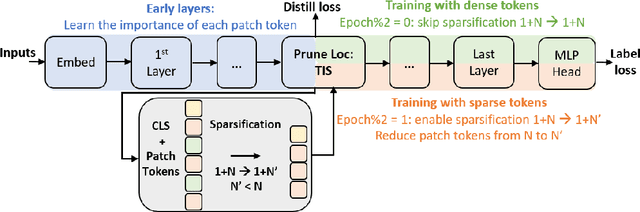
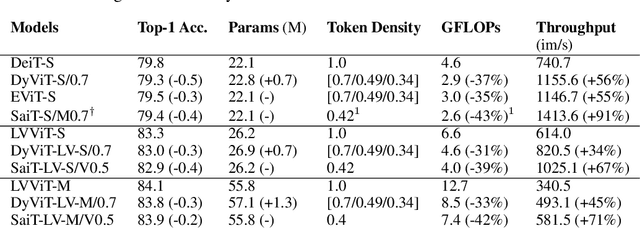
While vision transformers have achieved impressive results, effectively and efficiently accelerating these models can further boost performances. In this work, we propose a dense/sparse training framework to obtain a unified model, enabling weight sharing across various token densities. Thus one model offers a range of accuracy and throughput tradeoffs for different applications. Besides, we introduce adaptive token pruning to optimize the patch token sparsity based on the input image. In addition, we investigate knowledge distillation to enhance token selection capability in early transformer modules. Sparse adaptive image Transformer (SaiT) offers varying levels of model acceleration by merely changing the token sparsity on the fly. Specifically, SaiT reduces the computation complexity (FLOPs) by 39% - 43% and increases the throughput by 67% - 91% with less than 0.5% accuracy loss for various vision transformer models. Meanwhile, the same model also provides the zero accuracy drop option by skipping the sparsification step. SaiT achieves better accuracy and computation tradeoffs than state-of-the-art transformer and convolutional models.
MaiT: Leverage Attention Masks for More Efficient Image Transformers
Jul 06, 2022


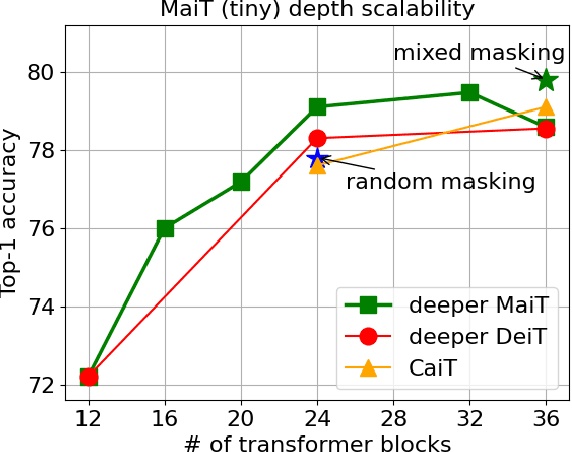
Though image transformers have shown competitive results with convolutional neural networks in computer vision tasks, lacking inductive biases such as locality still poses problems in terms of model efficiency especially for embedded applications. In this work, we address this issue by introducing attention masks to incorporate spatial locality into self-attention heads. Local dependencies are captured efficiently with masked attention heads along with global dependencies captured by unmasked attention heads. With Masked attention image Transformer - MaiT, top-1 accuracy increases by up to 1.7% compared to CaiT with fewer parameters and FLOPs, and the throughput improves by up to 1.5X compared to Swin. Encoding locality with attention masks is model agnostic, and thus it applies to monolithic, hierarchical, or other novel transformer architectures.
Learned Token Pruning for Transformers
Jul 02, 2021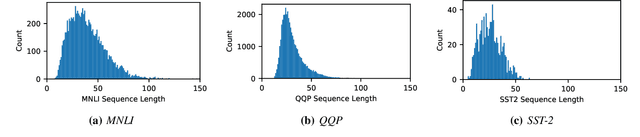
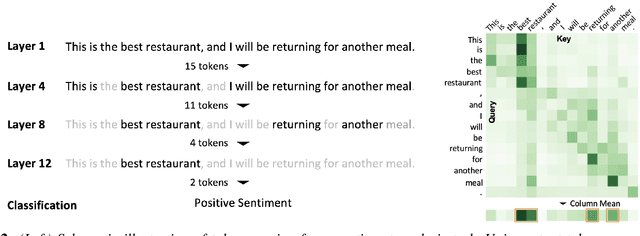
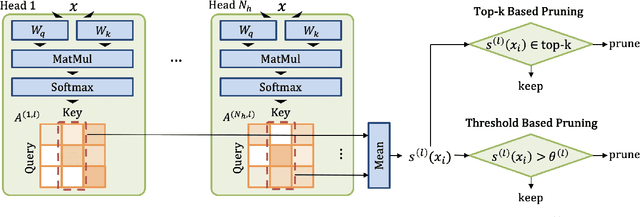
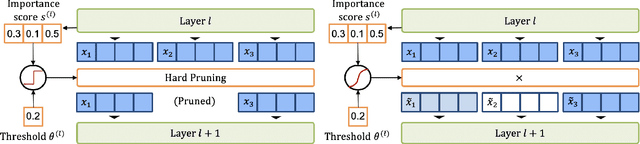
A major challenge in deploying transformer models is their prohibitive inference cost, which quadratically scales with the input sequence length. This makes it especially difficult to use transformers for processing long sequences. To address this, we present a novel Learned Token Pruning (LTP) method that reduces redundant tokens as the data passes through the different layers of the transformer. In particular, LTP prunes tokens with an attention score below a threshold value, which is learned during training. Importantly, our threshold based method avoids algorithmically expensive operations such as top-k token selection which are used in prior token pruning methods, and also leads to structured pruning. We extensively test the performance of our approach on multiple GLUE tasks and show that our learned threshold based method consistently outperforms the prior state-of-the-art top-k token based method by up to ~2% higher accuracy with the same amount of FLOPs. Furthermore, our preliminary results show up to 1.4x and 1.9x throughput improvement on Tesla T4 GPU and Intel Haswell CPU, respectively, with less than 1% of accuracy drop (and up to 2.1x FLOPs reduction). Our code has been developed in PyTorch and has been open-sourced.
Near-Lossless Post-Training Quantization of Deep Neural Networks via a Piecewise Linear Approximation
Jan 31, 2020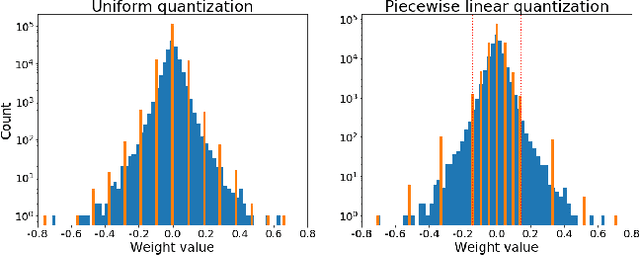
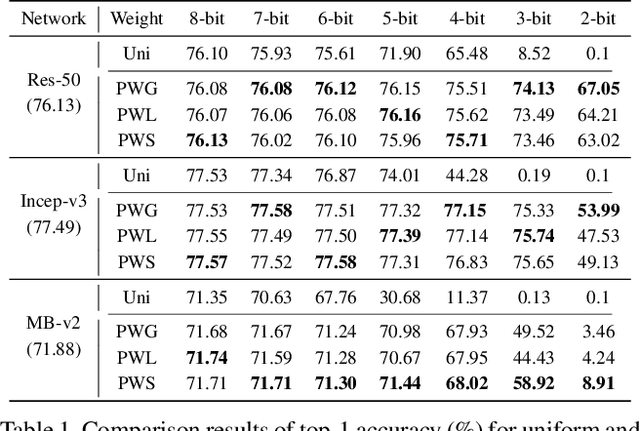
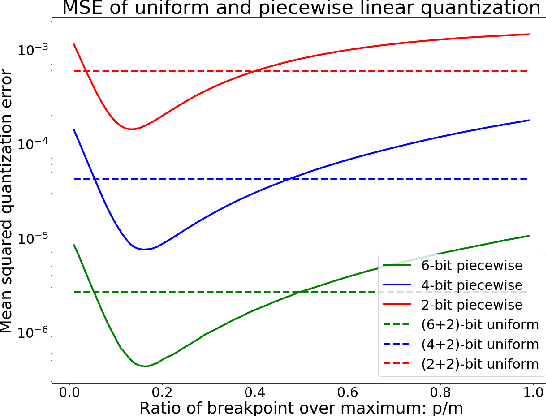
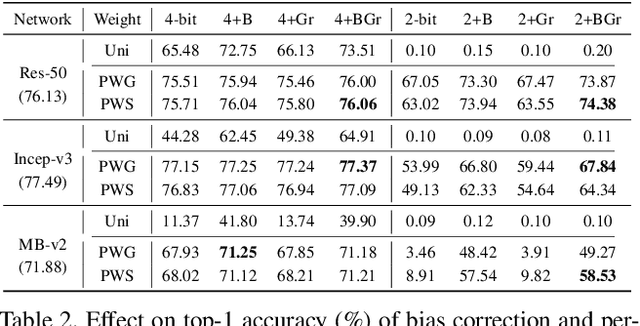
Quantization plays an important role for energy-efficient deployment of deep neural networks (DNNs) on resource-limited devices. Post-training quantization is crucial since it does not require retraining or accessibility to the full training dataset. The conventional post-training uniform quantization scheme achieves satisfactory results by converting DNNs from full-precision to 8-bit integers, however, it suffers from significant performance degradation when quantizing to lower precision such as 4 bits. In this paper, we propose a piecewise linear quantization method to enable accurate post-training quantization. Inspired from the fact that the weight tensors have bell-shaped distributions with long tails, our approach breaks the entire quantization range into two non-overlapping regions for each tensor, with each region being assigned an equal number of quantization levels. The optimal break-point that divides the entire range is found by minimizing the quantization error. Extensive results show that the proposed method achieves state-of-the-art performance on image classification, semantic segmentation and object detection. It is possible to quantize weights to 4 bits without retraining while nearly maintaining the performance of the original full-precision model.