 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaiT: Leverage Attention Masks for More Efficient Image Transformers
Paper and Code
Jul 06, 2022


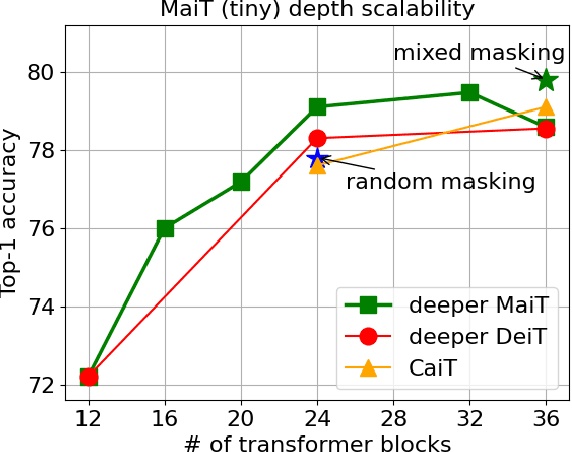
Though image transformers have shown competitive results with convolutional neural networks in computer vision tasks, lacking inductive biases such as locality still poses problems in terms of model efficiency especially for embedded applications. In this work, we address this issue by introducing attention masks to incorporate spatial locality into self-attention heads. Local dependencies are captured efficiently with masked attention heads along with global dependencies captured by unmasked attention heads. With Masked attention image Transformer - MaiT, top-1 accuracy increases by up to 1.7% compared to CaiT with fewer parameters and FLOPs, and the throughput improves by up to 1.5X compared to Swin. Encoding locality with attention masks is model agnostic, and thus it applies to monolithic, hierarchical, or other novel transformer architectures.