 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Lossless Post-Training Quantization of Deep Neural Networks via a Piecewise Linear Approximation
Paper and Code
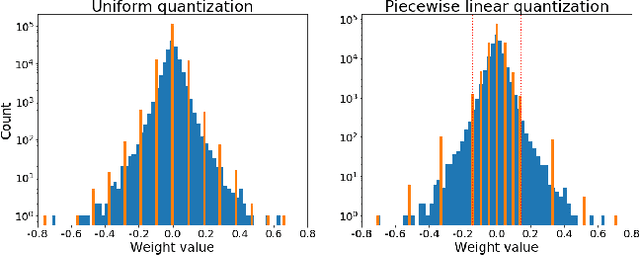
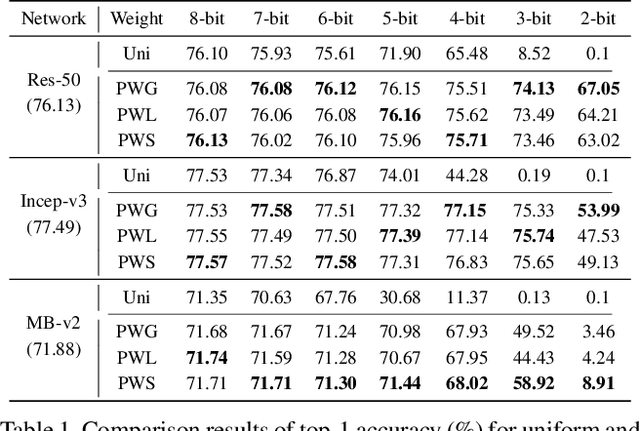
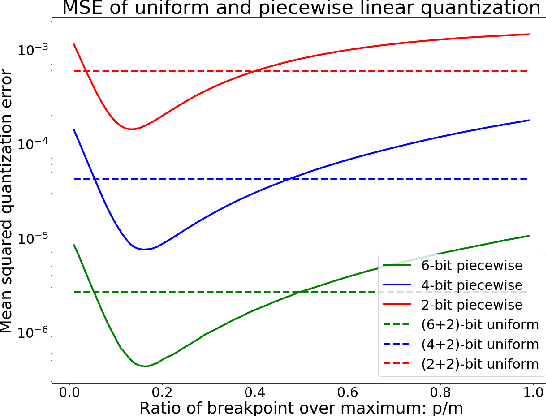
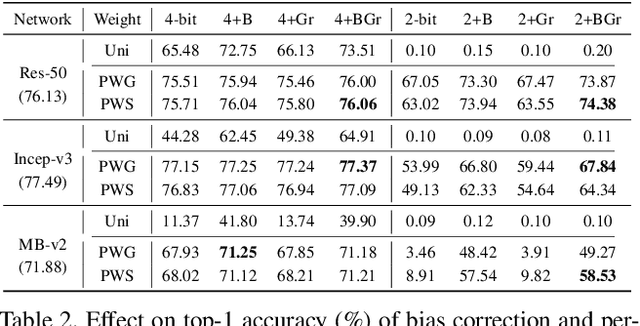
Quantization plays an important role for energy-efficient deployment of deep neural networks (DNNs) on resource-limited devices. Post-training quantization is crucial since it does not require retraining or accessibility to the full training dataset. The conventional post-training uniform quantization scheme achieves satisfactory results by converting DNNs from full-precision to 8-bit integers, however, it suffers from significant performance degradation when quantizing to lower precision such as 4 bits. In this paper, we propose a piecewise linear quantization method to enable accurate post-training quantization. Inspired from the fact that the weight tensors have bell-shaped distributions with long tails, our approach breaks the entire quantization range into two non-overlapping regions for each tensor, with each region being assigned an equal number of quantization levels. The optimal break-point that divides the entire range is found by minimizing the quantization error. Extensive results show that the proposed method achieves state-of-the-art performance on image classification, semantic segmentation and object detection. It is possible to quantize weights to 4 bits without retraining while nearly maintaining the performance of the original full-precision model.