 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robot Safety from Sparse Human Feedback using Conformal Prediction
Jan 08, 2025



Ensuring robot safety can be challenging; user-defined constraints can miss edge cases, policies can become unsafe even when trained from safe data, and safety can be subjective. Thus, we learn about robot safety by showing policy trajectories to a human who flags unsafe behavior. From this binary feedback, we use the statistical method of conformal prediction to identify a region of states, potentially in learned latent space, guaranteed to contain a user-specified fraction of future policy errors. Our method is sample-efficient, as it builds on nearest neighbor classification and avoids withholding data as is common with conformal prediction. By alerting if the robot reaches the suspected unsafe region, we obtain a warning system that mimics the human's safety preferences with guaranteed miss rate. From video labeling, our system can detect when a quadcopter visuomotor policy will fail to steer through a designated gate. We present an approach for policy improvement by avoiding the suspected unsafe region. With it we improve a model predictive controller's safety, as shown in experimental testing with 30 quadcopter flights across 6 navigation tasks. Code and videos are provided.
How Generalizable Is My Behavior Cloning Policy? A Statistical Approach to Trustworthy Performance Evaluation
May 08, 2024



With the rise of stochastic generative models in robot policy learning, end-to-end visuomotor policies are increasingly successful at solving complex tasks by learning from human demonstrations. Nevertheless, since real-world evaluation costs afford users only a small number of policy rollouts, it remains a challenge to accurately gauge the performance of such policies. This is exacerbated by distribution shifts causing unpredictable changes in performance during deployment. To rigorously evaluate behavior cloning policies, we present a framework that provides a tight lower-bound on robot performance in an arbitrary environment, using a minimal number of experimental policy rollouts. Notably, by applying the standard stochastic ordering to robot performance distributions, we provide a worst-case bound on the entire distribution of performance (via bounds on the cumulative distribution function) for a given task. We build upon established statistical results to ensure that the bounds hold with a user-specified confidence level and tightness, and are constructed from as few policy rollouts as possible. In experiments we evaluate policies for visuomotor manipulation in both simulation and hardware. Specifically, we (i) empirically validate the guarantees of the bounds in simulated manipulation settings, (ii) find the degree to which a learned policy deployed on hardware generalizes to new real-world environments, and (iii) rigorously compare two policies tested in out-of-distribution settings. Our experimental data, code, and implementation of confidence bounds are open-source.
Guarantees on Robot System Performance Using Stochastic Simulation Rollouts
Sep 19, 2023
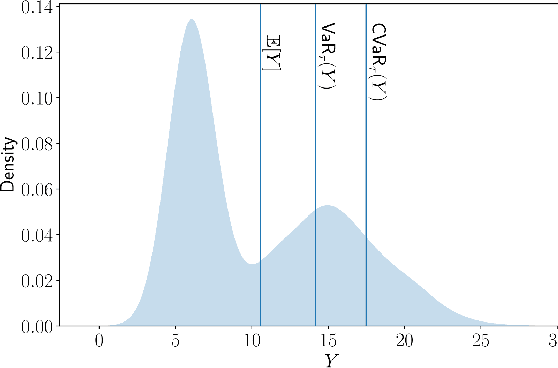

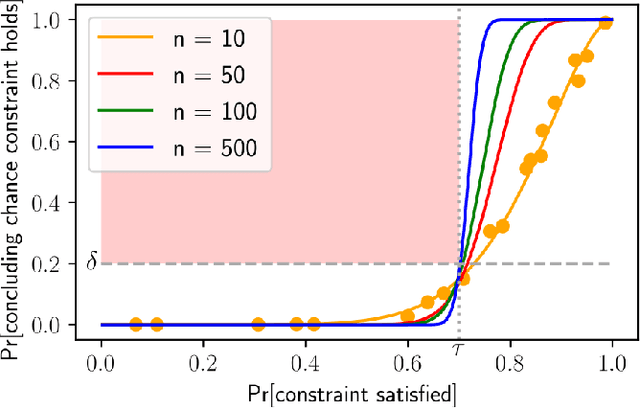
We provide finite-sample performance guarantees for control policies executed on stochastic robotic systems. Given an open- or closed-loop policy and a finite set of trajectory rollouts under the policy, we bound the expected value, value-at-risk, and conditional-value-at-risk of the trajectory cost, and the probability of failure in a sparse rewards setting. The bounds hold, with user-specified probability, for any policy synthesis technique and can be seen as a post-design safety certification. Generating the bounds only requires sampling simulation rollouts, without assumptions on the distribution or complexity of the underlying stochastic system. We adapt these bounds to also give a constraint satisfaction test to verify safety of the robot system. Furthermore, we extend our method to apply when selecting the best policy from a set of candidates, requiring a multi-hypothesis correction. We show the statistical validity of our bounds in the Ant, Half-cheetah, and Swimmer MuJoCo environments and demonstrate our constraint satisfaction test with the Ant. Finally, using the 20 degree-of-freedom MuJoCo Shadow Hand, we show the necessity of the multi-hypothesis correction.
Reachable Polyhedral Marching (RPM): An Exact Analysis Tool for Deep-Learned Control Systems
Oct 15, 2022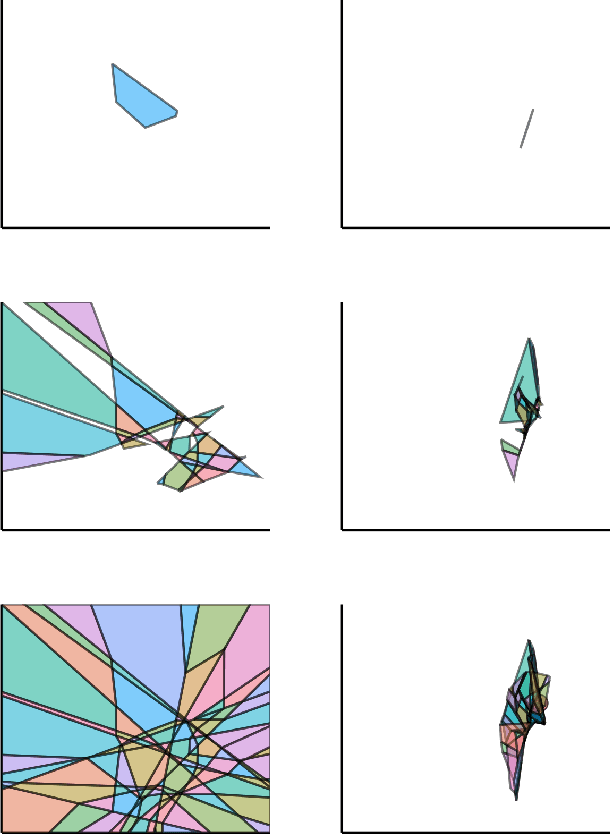
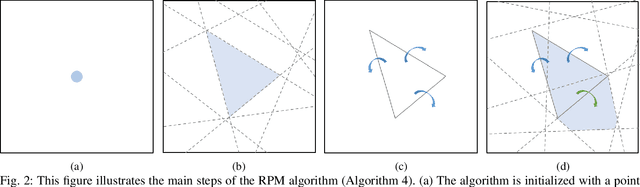
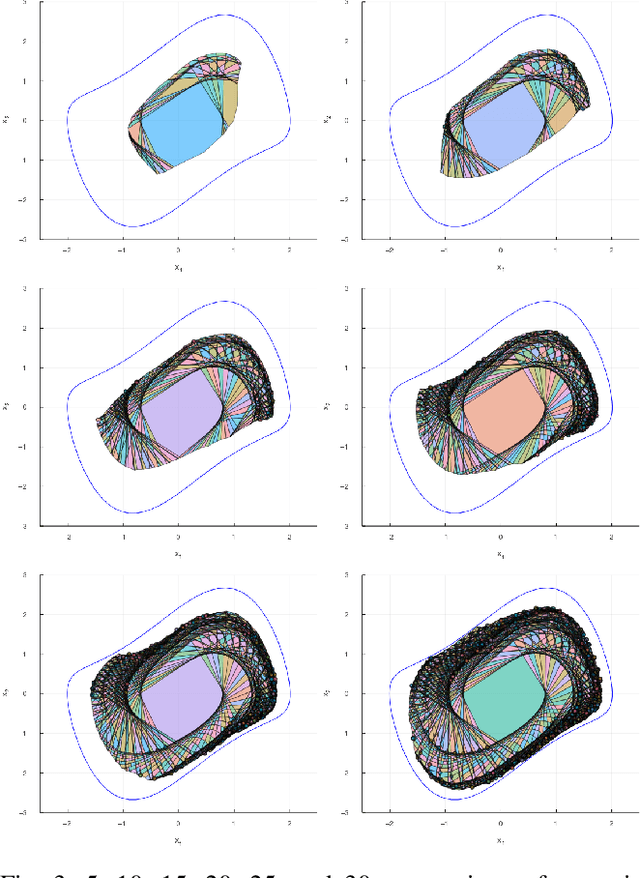
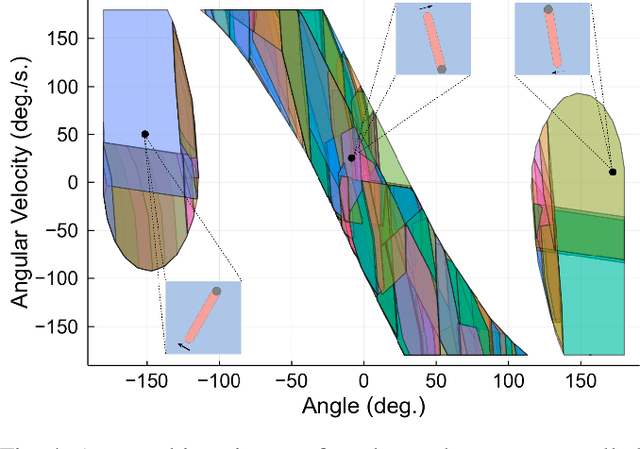
We present a tool for computing exact forward and backward reachable sets of deep neural networks with rectified linear unit (ReLU) activation. We then develop algorithms using this tool to compute invariant sets and regions of attraction (ROAs) for control systems with neural networks in the feedback loop. Our algorithm is unique in that it builds the reachable sets by incrementally enumerating polyhedral regions in the input space, rather than iterating layer-by-layer through the network as in other methods. When performing safety verification, if an unsafe region is found, our algorithm can return this result without completing the full reachability computation, thus giving an anytime property that accelerates safety verification. Furthermore, we introduce a method to accelerate the computation of ROAs in the case that deep learned components are homeomorphisms, which we find is surprisingly common in practice. We demonstrate our tool in several test cases. We compute a ROA for a learned van der Pol oscillator model. We find a control invariant set for a learned torque-controlled pendulum model. We also verify specific safety properties for multiple deep networks related to the ACAS Xu aircraft collision advisory system. Finally, we apply our algorithm to find ROAs for an image-based aircraft runway taxi problem. Algorithm source code: https://github.com/StanfordMSL/Neural-Network-Reach .
DiNNO: Distributed Neural Network Optimization for Multi-Robot Collaborative Learning
Sep 17, 2021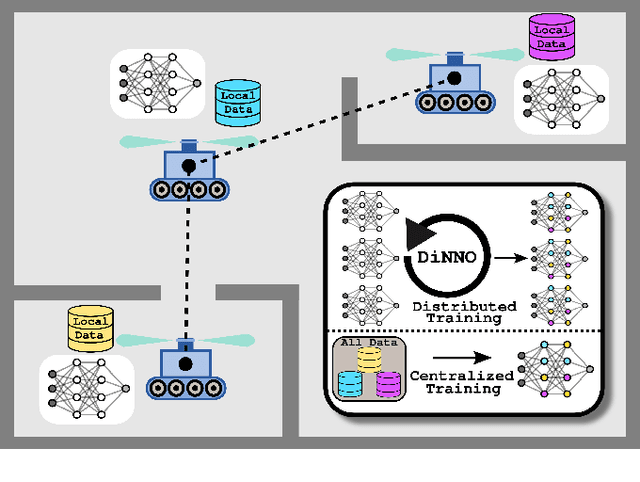
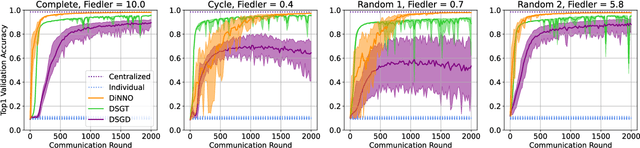
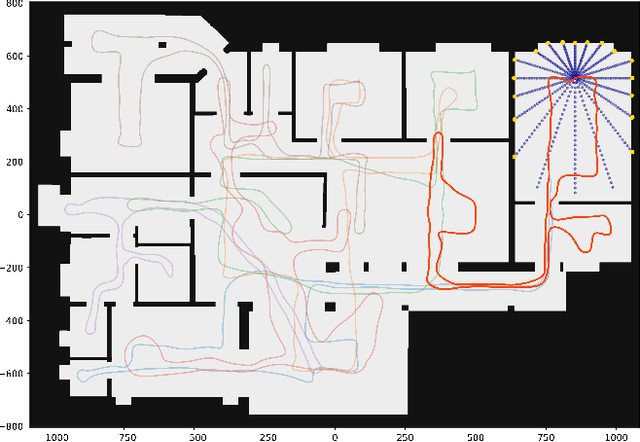
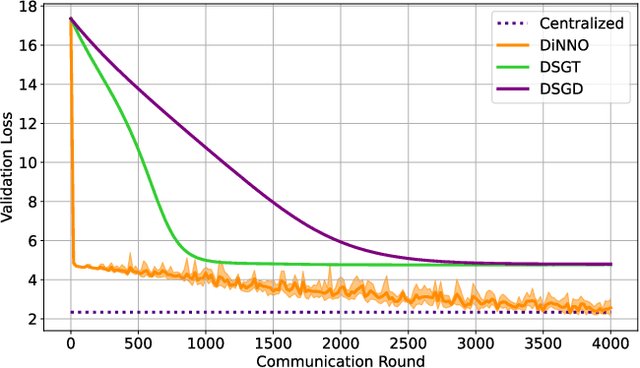
We present a distributed algorithm that enables a group of robots to collaboratively optimize the parameters of a deep neural network model while communicating over a mesh network. Each robot only has access to its own data and maintains its own version of the neural network, but eventually learns a model that is as good as if it had been trained on all the data centrally. No robot sends raw data over the wireless network, preserving data privacy and ensuring efficient use of wireless bandwidth. At each iteration, each robot approximately optimizes an augmented Lagrangian function, then communicates the resulting weights to its neighbors, updates dual variables, and repeats. Eventually, all robots' local network weights reach a consensus. For convex objective functions, we prove this consensus is a global optimum. We compare our algorithm to two existing distributed deep neural network training algorithms in (i) an MNIST image classification task, (ii) a multi-robot implicit mapping task, and (iii) a multi-robot reinforcement learning task. In all of our experiments our method out performed baselines, and was able to achieve validation loss equivalent to centrally trained models. See \href{https://msl.stanford.edu/projects/dist_nn_train}{https://msl.stanford.edu/projects/dist\_nn\_train} for videos and a link to our GitHub repository.
Reachable Polyhedral Marching (RPM): A Safety Verification Algorithm for Robotic Systems with Deep Neural Network Components
Nov 23, 2020
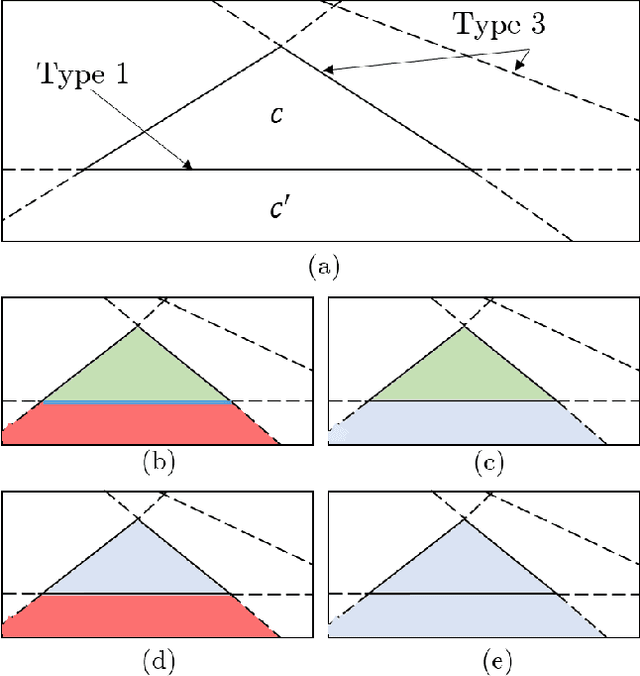
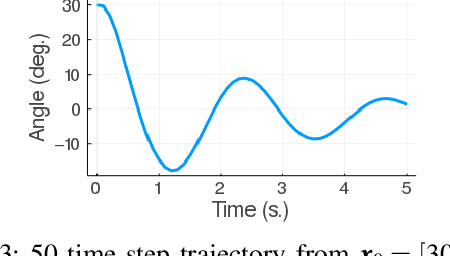
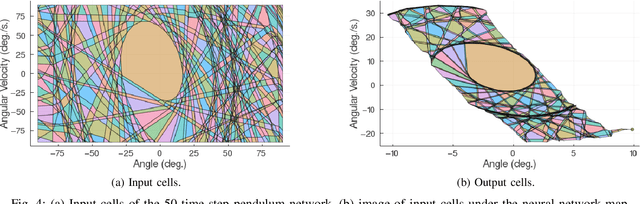
We present a method for computing exact reachable sets for deep neural networks with rectified linear unit (ReLU) activation. Our method is well-suited for use in rigorous safety analysis of robotic perception and control systems with deep neural network components. Our algorithm can compute both forward and backward reachable sets for a ReLU network iterated over multiple time steps, as would be found in a perception-action loop in a robotic system. Our algorithm is unique in that it builds the reachable sets by expanding a front of polyhedral cells in the input space, rather than iterating layer-by-layer through the network as in other methods. If an unsafe cell is found, our algorithm can return this result without completing the full reachability computation, thus giving an anytime property that accelerates safety verification. We demonstrate our algorithm on safety verification of the ACAS Xu aircraft advisory system. We find unsafe actions many times faster than the fastest existing method and certify no unsafe actions exist in about twice the time of the existing method. We also compute forward and backward reachable sets for a learned model of pendulum dynamics over a 50 time step horizon in 87s on a laptop computer. Source code for our algorithm can be found at https://github.com/StanfordMSL/Neural-Network-Reach.