 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robot Safety from Sparse Human Feedback using Conformal Prediction
Jan 08, 2025



Ensuring robot safety can be challenging; user-defined constraints can miss edge cases, policies can become unsafe even when trained from safe data, and safety can be subjective. Thus, we learn about robot safety by showing policy trajectories to a human who flags unsafe behavior. From this binary feedback, we use the statistical method of conformal prediction to identify a region of states, potentially in learned latent space, guaranteed to contain a user-specified fraction of future policy errors. Our method is sample-efficient, as it builds on nearest neighbor classification and avoids withholding data as is common with conformal prediction. By alerting if the robot reaches the suspected unsafe region, we obtain a warning system that mimics the human's safety preferences with guaranteed miss rate. From video labeling, our system can detect when a quadcopter visuomotor policy will fail to steer through a designated gate. We present an approach for policy improvement by avoiding the suspected unsafe region. With it we improve a model predictive controller's safety, as shown in experimental testing with 30 quadcopter flights across 6 navigation tasks. Code and videos are provided.
Guarantees on Robot System Performance Using Stochastic Simulation Rollouts
Sep 19, 2023
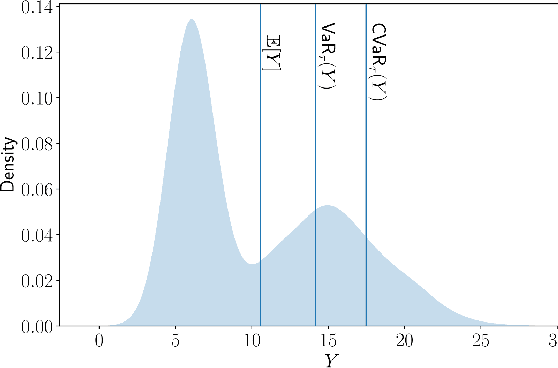

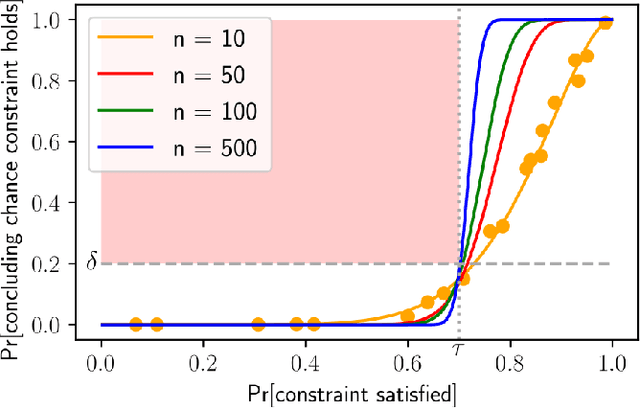
We provide finite-sample performance guarantees for control policies executed on stochastic robotic systems. Given an open- or closed-loop policy and a finite set of trajectory rollouts under the policy, we bound the expected value, value-at-risk, and conditional-value-at-risk of the trajectory cost, and the probability of failure in a sparse rewards setting. The bounds hold, with user-specified probability, for any policy synthesis technique and can be seen as a post-design safety certification. Generating the bounds only requires sampling simulation rollouts, without assumptions on the distribution or complexity of the underlying stochastic system. We adapt these bounds to also give a constraint satisfaction test to verify safety of the robot system. Furthermore, we extend our method to apply when selecting the best policy from a set of candidates, requiring a multi-hypothesis correction. We show the statistical validity of our bounds in the Ant, Half-cheetah, and Swimmer MuJoCo environments and demonstrate our constraint satisfaction test with the Ant. Finally, using the 20 degree-of-freedom MuJoCo Shadow Hand, we show the necessity of the multi-hypothesis correction.