 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation Principal Component Analysis: base linear method for learning with out-of-distribution data
Aug 28, 2022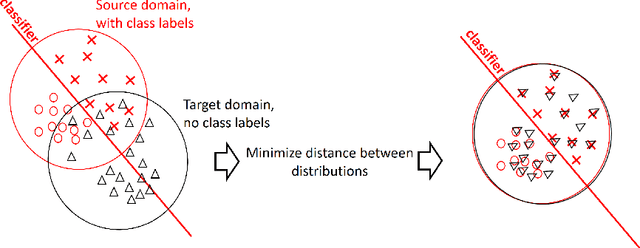
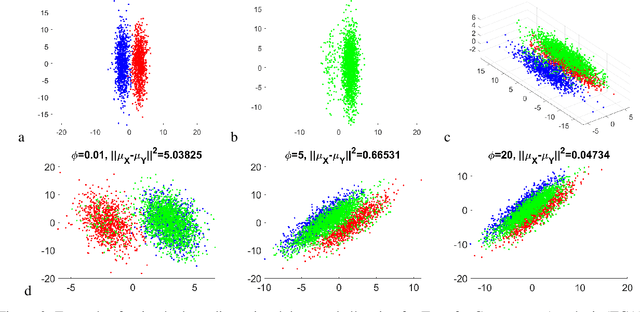
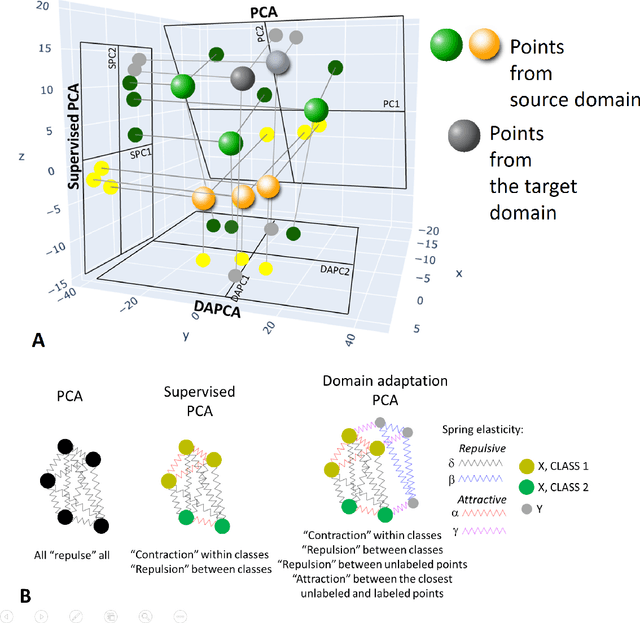
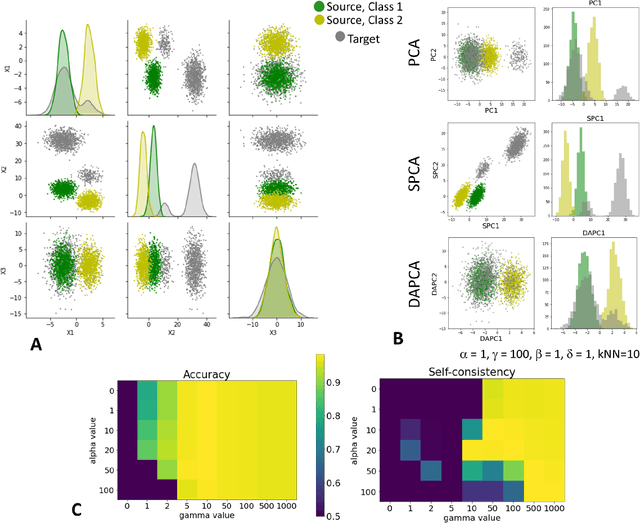
Domain adaptation is a popular paradigm in modern machine learning which aims at tackling the problem of divergence between training or validation dataset possessing labels for learning and testing a classifier (source domain) and a potentially large unlabeled dataset where the model is exploited (target domain). The task is to find such a common representation of both source and target datasets in which the source dataset is informative for training and such that the divergence between source and target would be minimized. Most popular solutions for domain adaptation are currently based on training neural networks that combine classification and adversarial learning modules, which are data hungry and usually difficult to train. We present a method called Domain Adaptation Principal Component Analysis (DAPCA) which finds a linear reduced data representation useful for solving the domain adaptation task. DAPCA is based on introducing positive and negative weights between pairs of data points and generalizes the supervised extension of principal component analysis. DAPCA represents an iterative algorithm such that at each iteration a simple quadratic optimization problem is solved. The convergence of the algorithm is guaranteed and the number of iterations is small in practice. We validate the suggested algorithm on previously proposed benchmarks for solving the domain adaptation task, and also show the benefit of using DAPCA in the analysis of single cell omics datasets in biomedical applications. Overall, DAPCA can serve as a useful preprocessing step in many machine learning applications leading to reduced dataset representations, taking into account possible divergence between source and target domains.
Quasi-orthogonality and intrinsic dimensions as measures of learning and generalisation
Mar 30, 2022

Finding best architectures of learning machines, such as deep neural networks, is a well-known technical and theoretical challenge. Recent work by Mellor et al (2021) showed that there may exist correlations between the accuracies of trained networks and the values of some easily computable measures defined on randomly initialised networks which may enable to search tens of thousands of neural architectures without training. Mellor et al used the Hamming distance evaluated over all ReLU neurons as such a measure. Motivated by these findings, in our work, we ask the question of the existence of other and perhaps more principled measures which could be used as determinants of success of a given neural architecture. In particular, we examine, if the dimensionality and quasi-orthogonality of neural networks' feature space could be correlated with the network's performance after training. We showed, using the setup as in Mellor et al, that dimensionality and quasi-orthogonality may jointly serve as network's performance discriminants. In addition to offering new opportunities to accelerate neural architecture search, our findings suggest important relationships between the networks' final performance and properties of their randomly initialised feature spaces: data dimension and quasi-orthogonality.
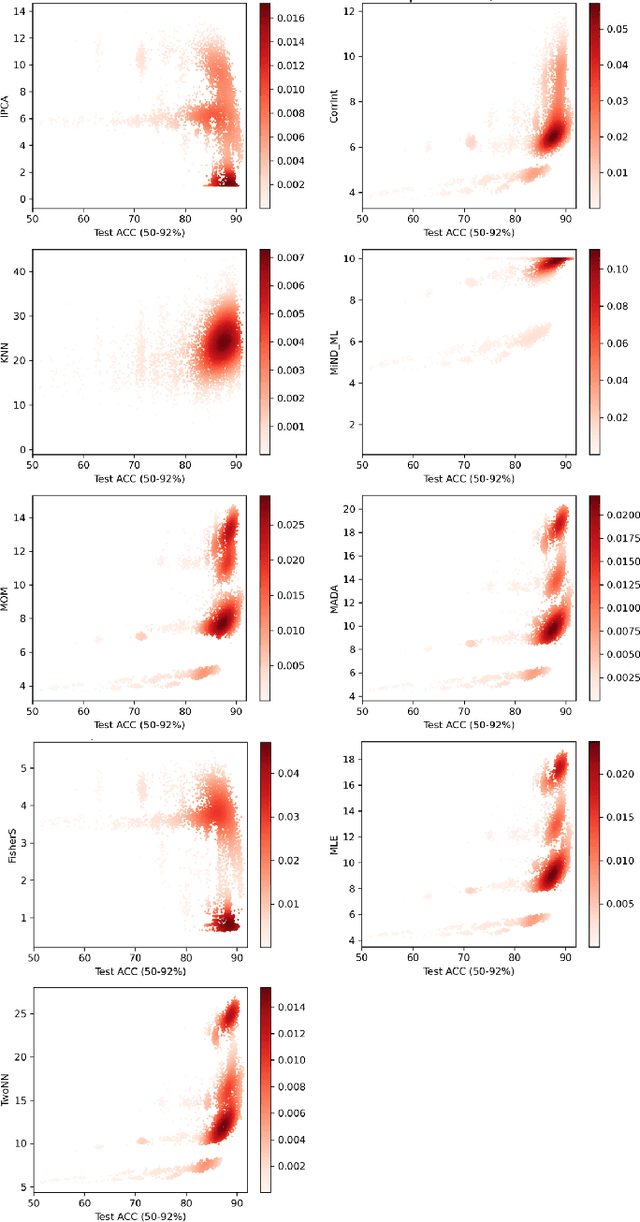
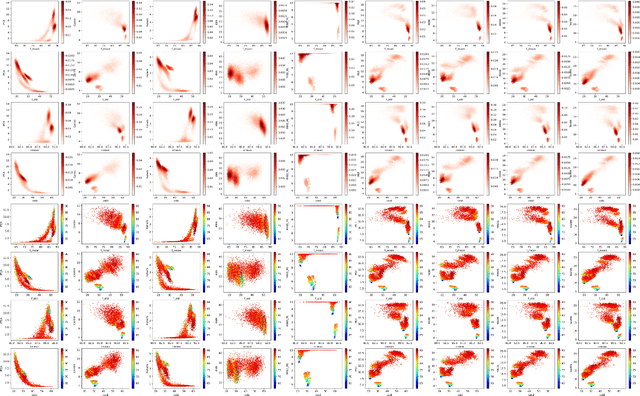
Scikit-dimension: a Python package for intrinsic dimension estimation
Sep 06, 2021



Dealing with uncertainty in applications of machine learning to real-life data critically depends on the knowledge of intrinsic dimensionality (ID). A number of methods have been suggested for the purpose of estimating ID, but no standard package to easily apply them one by one or all at once has been implemented in Python. This technical note introduces \texttt{scikit-dimension}, an open-source Python package for intrinsic dimension estimation. \texttt{scikit-dimension} package provides a uniform implementation of most of the known ID estimators based on scikit-learn application programming interface to evaluate global and local intrinsic dimension, as well as generators of synthetic toy and benchmark datasets widespread in the literature. The package is developed with tools assessing the code quality, coverage, unit testing and continuous integration. We briefly describe the package and demonstrate its use in a large-scale (more than 500 datasets) benchmarking of methods for ID estimation in real-life and synthetic data. The source code is available from https://github.com/j-bac/scikit-dimension , the documentation is available from https://scikit-dimension.readthedocs.io .
Trajectories, bifurcations and pseudotime in large clinical datasets: applications to myocardial infarction and diabetes data
Jul 07, 2020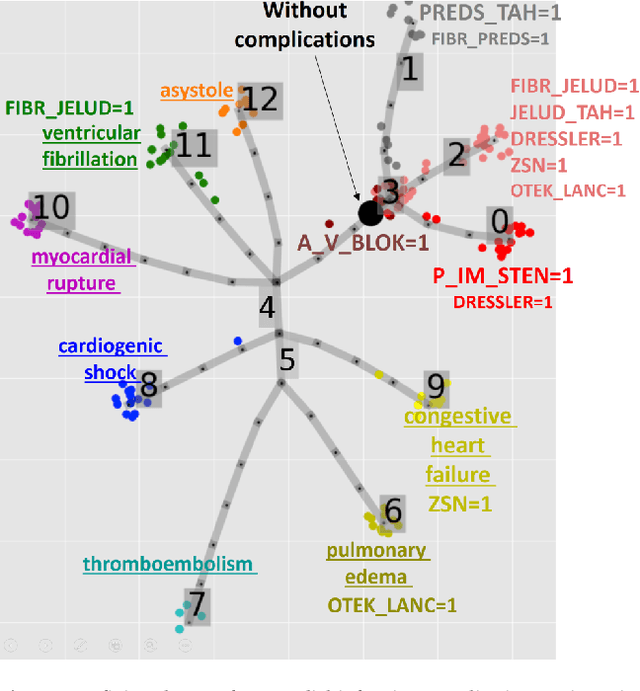
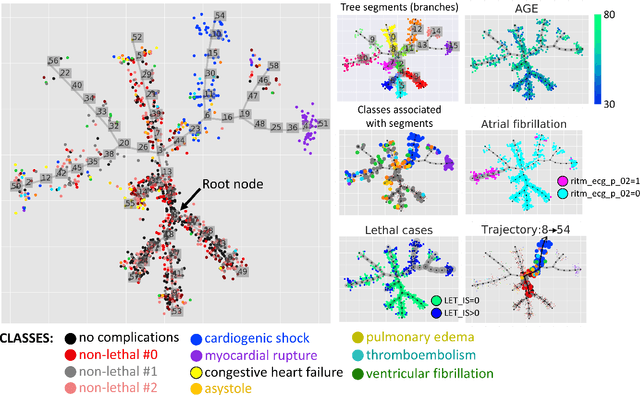
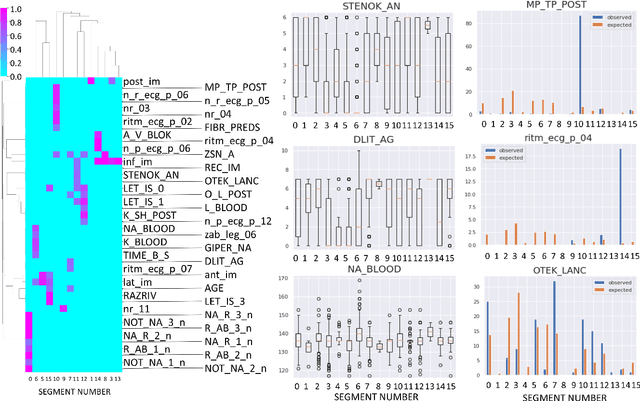
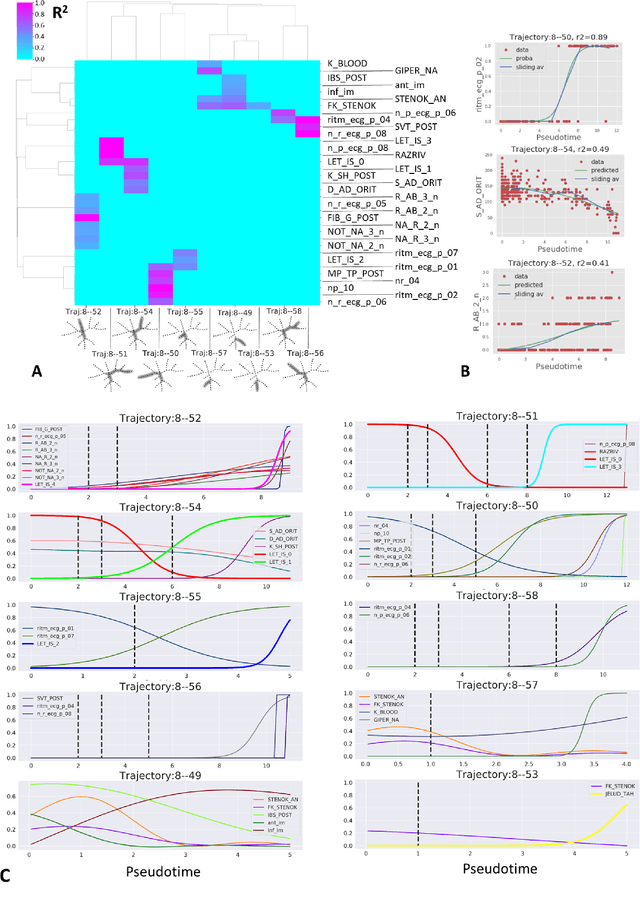
Large observational clinical datasets become increasingly available for mining associations between various disease traits and administered therapy. These datasets can be considered as representations of the landscape of all possible disease conditions, in which a concrete pathology develops through a number of stereotypical routes, characterized by `points of no return' and `final states' (such as lethal or recovery states). Extracting this information directly from the data remains challenging, especially in the case of synchronic (with a short-term follow up) observations. Here we suggest a semi-supervised methodology for the analysis of large clinical datasets, characterized by mixed data types and missing values, through modeling the geometrical data structure as a bouquet of bifurcating clinical trajectories. The methodology is based on application of elastic principal graphs which can address simultaneously the tasks of dimensionality reduction, data visualization, clustering, feature selection and quantifying the geodesic distances (pseudotime) in partially ordered sequences of observations. The methodology allows positioning a patient on a particular clinical trajectory (pathological scenario) and characterizing the degree of progression along it with a qualitative estimate of the uncertainty of the prognosis. Overall, our pseudo-time quantification-based approach gives a possibility to apply the methods developed for dynamical disease phenotyping and illness trajectory analysis (diachronic data analysis) to synchronic observational data. We developed a tool $ClinTrajan$ for clinical trajectory analysis implemented in Python programming language. We test the methodology in two large publicly available datasets: myocardial infarction complications and readmission of diabetic patients data.
Local intrinsic dimensionality estimators based on concentration of measure
Feb 07, 2020
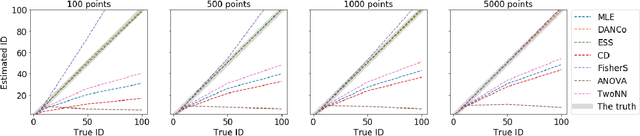

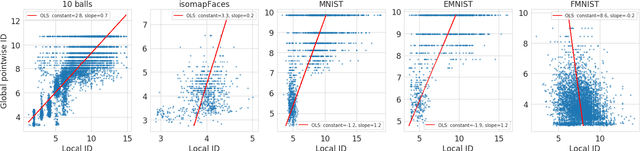
Intrinsic dimensionality (ID) is one of the most fundamental characteristics of multi-dimensional data point clouds. Knowing ID is crucial to choose the appropriate machine learning approach as well as to understand its behavior and validate it. ID can be computed globally for the whole data distribution, or computed locally in different regions of the dataset. In this paper, we introduce new local estimators of ID based on linear separability of multi-dimensional data point clouds, which is one of the manifestations of concentration of measure. We empirically study the properties of these estimators and compare them with other recently introduced ID estimators exploiting various effects of measure concentration. Observed differences between estimators can be used to anticipate their behaviour in practical applications.
Estimating the effective dimension of large biological datasets using Fisher separability analysis
Jan 18, 2019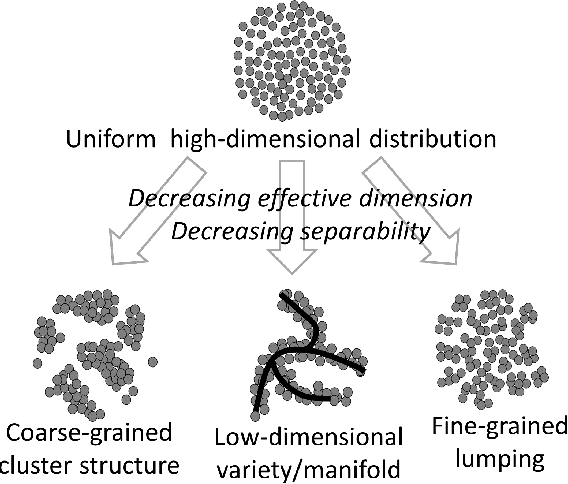
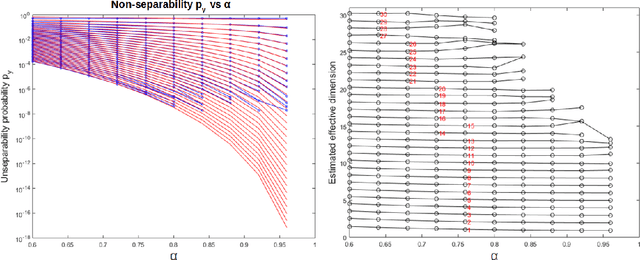

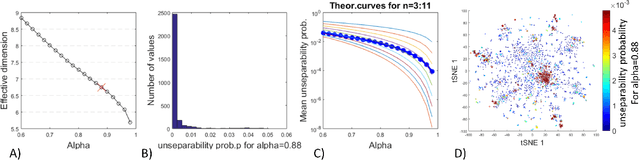
Modern large-scale datasets are frequently said to be high-dimensional. However, their data point clouds frequently possess structures, significantly decreasing their intrinsic dimensionality (ID) due to the presence of clusters, points being located close to low-dimensional varieties or fine-grained lumping. We test a recently introduced dimensionality estimator, based on analysing the separability properties of data points, on several benchmarks and real biological datasets. We show that the introduced measure of ID has performance competitive with state-of-the-art measures, being efficient across a wide range of dimensions and performing better in the case of noisy samples. Moreover, it allows estimating the intrinsic dimension in situations where the intrinsic manifold assumption is not valid.