 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSD: Dense-Sparse-Dense Training for Deep Neural Networks
Feb 21, 2017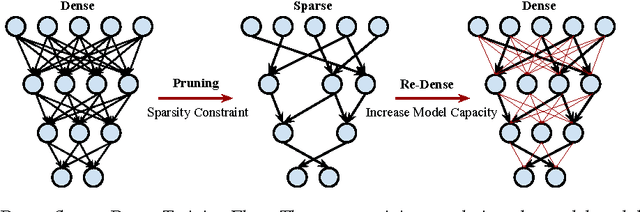
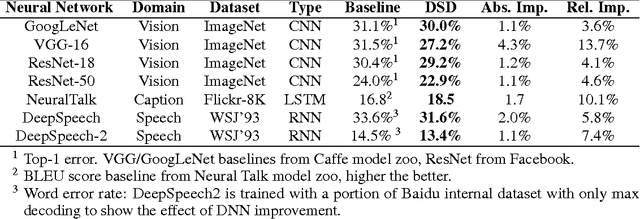
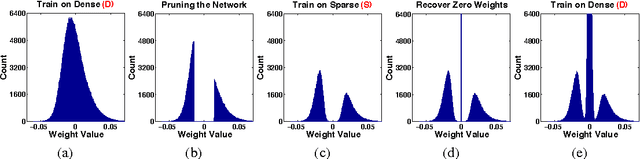
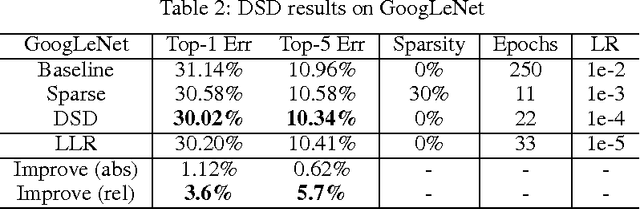
Modern deep neural networks have a large number of parameters, making them very hard to train. We propose DSD, a dense-sparse-dense training flow, for regularizing deep neural networks and achieving better optimization performance. In the first D (Dense) step, we train a dense network to learn connection weights and importance. In the S (Sparse) step, we regularize the network by pruning the unimportant connections with small weights and retraining the network given the sparsity constraint. In the final D (re-Dense) step, we increase the model capacity by removing the sparsity constraint, re-initialize the pruned parameters from zero and retrain the whole dense network. Experiments show that DSD training can improve the performance for a wide range of CNNs, RNNs and LSTMs on the tasks of image classification, caption generation and speech recognition. On ImageNet, DSD improved the Top1 accuracy of GoogLeNet by 1.1%, VGG-16 by 4.3%, ResNet-18 by 1.2% and ResNet-50 by 1.1%, respectively. On the WSJ'93 dataset, DSD improved DeepSpeech and DeepSpeech2 WER by 2.0% and 1.1%. On the Flickr-8K dataset, DSD improved the NeuralTalk BLEU score by over 1.7. DSD is easy to use in practice: at training time, DSD incurs only one extra hyper-parameter: the sparsity ratio in the S step. At testing time, DSD doesn't change the network architecture or incur any inference overhead. The consistent and significant performance gain of DSD experiments shows the inadequacy of the current training methods for finding the best local optimum, while DSD effectively achieves superior optimization performance for finding a better solution. DSD models are available to download at https://songhan.github.io/DSD.
Learning both Weights and Connections for Efficient Neural Networks
Oct 30, 2015
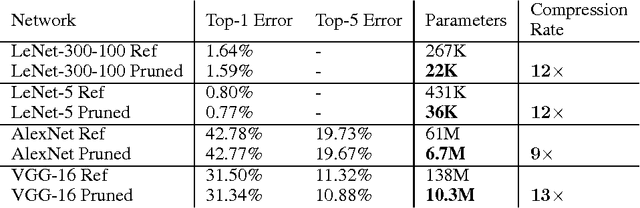
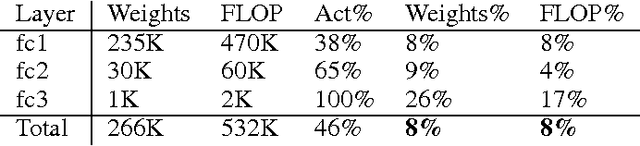
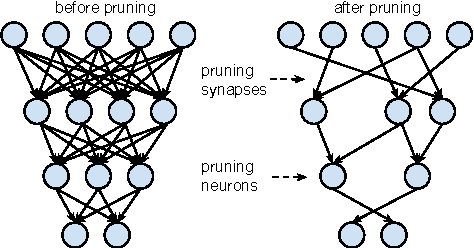
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems. Also, conventional networks fix the architecture before training starts; as a result, training cannot improve the architecture. To address these limitations, we describe a method to reduce the storage and computation required by neural networks by an order of magnitude without affecting their accuracy by learning only the important connections. Our method prunes redundant connections using a three-step method. First, we train the network to learn which connections are important. Next, we prune the unimportant connections. Finally, we retrain the network to fine tune the weights of the remaining connections. On the ImageNet dataset, our method reduced the number of parameters of AlexNet by a factor of 9x, from 61 million to 6.7 million, without incurring accuracy loss. Similar experiments with VGG-16 found that the number of parameters can be reduced by 13x, from 138 million to 10.3 million, again with no loss of accuracy.
cuDNN: Efficient Primitives for Deep Learning
Dec 18, 2014


We present a library of efficient implementations of deep learning primitives. Deep learning workloads are computationally intensive, and optimizing their kernels is difficult and time-consuming. As parallel architectures evolve, kernels must be reoptimized, which makes maintaining codebases difficult over time. Similar issues have long been addressed in the HPC community by libraries such as the Basic Linear Algebra Subroutines (BLAS). However, there is no analogous library for deep learning. Without such a library, researchers implementing deep learning workloads on parallel processors must create and optimize their own implementations of the main computational kernels, and this work must be repeated as new parallel processors emerge. To address this problem, we have created a library similar in intent to BLAS, with optimized routines for deep learning workloads. Our implementation contains routines for GPUs, although similarly to the BLAS library, these routines could be implemented for other platforms. The library is easy to integrate into existing frameworks, and provides optimized performance and memory usage. For example, integrating cuDNN into Caffe, a popular framework for convolutional networks, improves performance by 36% on a standard model while also reducing memory consumption.
Parallel Support Vector Machines in Practice
Apr 03, 2014
In this paper, we evaluate the performance of various parallel optimization methods for Kernel Support Vector Machines on multicore CPUs and GPUs. In particular, we provide the first comparison of algorithms with explicit and implicit parallelization. Most existing parallel implementations for multi-core or GPU architectures are based on explicit parallelization of Sequential Minimal Optimization (SMO)---the programmers identified parallelizable components and hand-parallelized them, specifically tuned for a particular architecture. We compare these approaches with each other and with implicitly parallelized algorithms---where the algorithm is expressed such that most of the work is done within few iterations with large dense linear algebra operations. These can be computed with highly-optimized libraries, that are carefully parallelized for a large variety of parallel platforms. We highlight the advantages and disadvantages of both approaches and compare them on various benchmark data sets. We find an approximate implicitly parallel algorithm which is surprisingly efficient, permits a much simpler implementation, and leads to unprecedented speedups in SVM training.