 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying latent disease factors differently expressed in patient subgroups using group factor analysis
Oct 10, 2024



In this study, we propose a novel approach to uncover subgroup-specific and subgroup-common latent factors addressing the challenges posed by the heterogeneity of neurological and mental disorders, which hinder disease understanding, treatment development, and outcome prediction. The proposed approach, sparse Group Factor Analysis (GFA) with regularised horseshoe priors, was implemented with probabilistic programming and can uncover associations (or latent factors) among multiple data modalities differentially expressed in sample subgroups. Synthetic data experiments showed the robustness of our sparse GFA by correctly inferring latent factors and model parameters. When applied to the Genetic Frontotemporal Dementia Initiative (GENFI) dataset, which comprises patients with frontotemporal dementia (FTD) with genetically defined subgroups, the sparse GFA identified latent disease factors differentially expressed across the subgroups, distinguishing between "subgroup-specific" latent factors within homogeneous groups and "subgroup common" latent factors shared across subgroups. The latent disease factors captured associations between brain structure and non-imaging variables (i.e., questionnaires assessing behaviour and disease severity) across the different genetic subgroups, offering insights into disease profiles. Importantly, two latent factors were more pronounced in the two more homogeneous FTD patient subgroups (progranulin (GRN) and microtubule-associated protein tau (MAPT) mutation), showcasing the method's ability to reveal subgroup-specific characteristics. These findings underscore the potential of sparse GFA for integrating multiple data modalities and identifying interpretable latent disease factors that can improve the characterization and stratification of patients with neurological and mental health disorders.
Deep Learning in current Neuroimaging: a multivariate approach with power and type I error control but arguable generalization ability
Mar 30, 2021
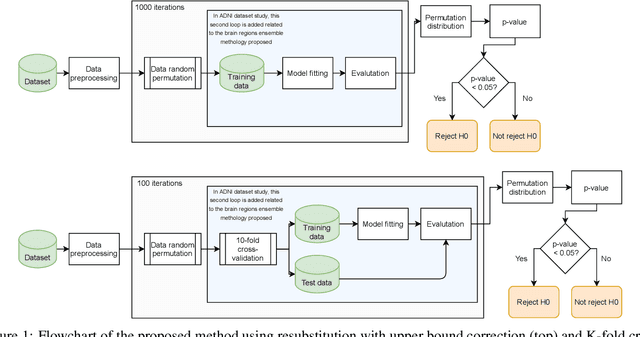
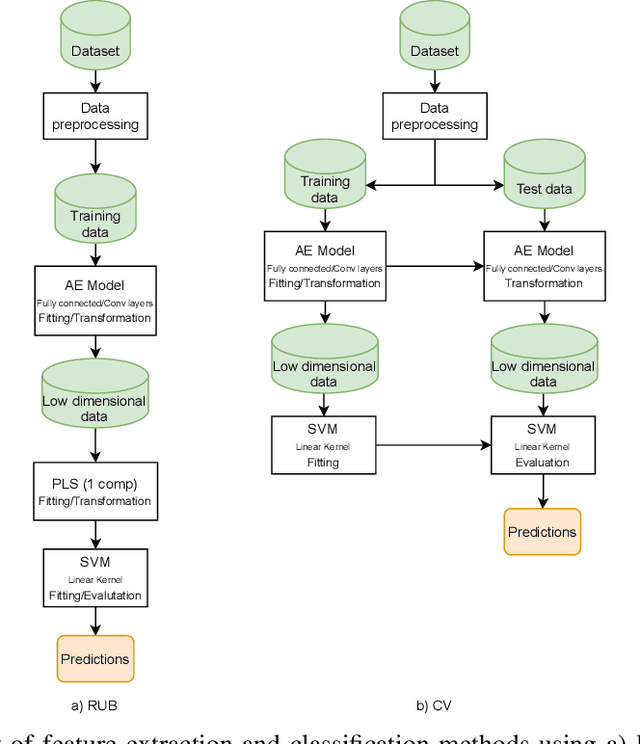
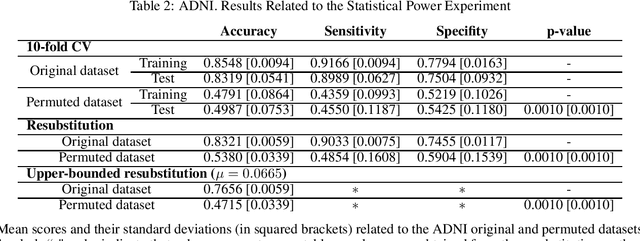
Discriminative analysis in neuroimaging by means of deep/machine learning techniques is usually tested with validation techniques, whereas the associated statistical significance remains largely under-developed due to their computational complexity. In this work, a non-parametric framework is proposed that estimates the statistical significance of classifications using deep learning architectures. In particular, a combination of autoencoders (AE) and support vector machines (SVM) is applied to: (i) a one-condition, within-group designs often of normal controls (NC) and; (ii) a two-condition, between-group designs which contrast, for example, Alzheimer's disease (AD) patients with NC (the extension to multi-class analyses is also included). A random-effects inference based on a label permutation test is proposed in both studies using cross-validation (CV) and resubstitution with upper bound correction (RUB) as validation methods. This allows both false positives and classifier overfitting to be detected as well as estimating the statistical power of the test. Several experiments were carried out using the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, the Dominantly Inherited Alzheimer Network (DIAN) dataset, and a MCI prediction dataset. We found in the permutation test that CV and RUB methods offer a false positive rate close to the significance level and an acceptable statistical power (although lower using cross-validation). A large separation between training and test accuracies using CV was observed, especially in one-condition designs. This implies a low generalization ability as the model fitted in training is not informative with respect to the test set. We propose as solution by applying RUB, whereby similar results are obtained to those of the CV test set, but considering the whole set and with a lower computational cost per iteration.
Hough-CNN: Deep Learning for Segmentation of Deep Brain Regions in MRI and Ultrasound
Jan 31, 2016

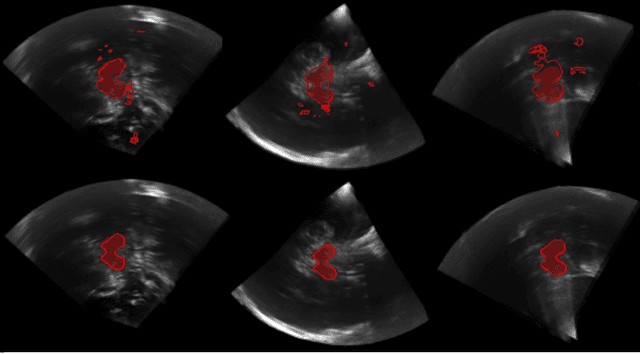
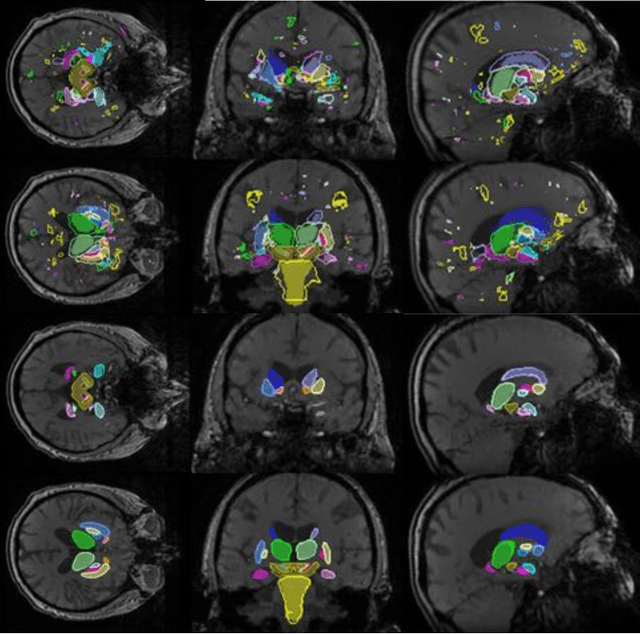
In this work we propose a novel approach to perform segmentation by leveraging the abstraction capabilities of convolutional neural networks (CNNs). Our method is based on Hough voting, a strategy that allows for fully automatic localisation and segmentation of the anatomies of interest. This approach does not only use the CNN classification outcomes, but it also implements voting by exploiting the features produced by the deepest portion of the network. We show that this learning-based segmentation method is robust, multi-region, flexible and can be easily adapted to different modalities. In the attempt to show the capabilities and the behaviour of CNNs when they are applied to medical image analysis, we perform a systematic study of the performances of six different network architectures, conceived according to state-of-the-art criteria, in various situations. We evaluate the impact of both different amount of training data and different data dimensionality (2D, 2.5D and 3D) on the final results. We show results on both MRI and transcranial US volumes depicting respectively 26 regions of the basal ganglia and the midbrain.