 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity of Extensions in Abstract Argumentation
May 13, 2026Argumentation is an important topic of AI for modelling and reasoning about arguments. In abstract argumentation, we consider directed graphs, so-called argumentation frameworks (AF), that express conflicts between arguments. The semantics is defined by the notion of extensions, which are sets of arguments that satisfy particular relationship conditions in the AF. Usually, standard reasoning in argumentation do not reveal how far apart extensions are. We introduce a quantitative notion of diversity of extensions based on the symmetric difference and provide a systematic complexity classification. Intuitively, diversity captures whether extensions of a framework (accepted viewpoints) differ only marginally or represent fundamentally incompatible sets of arguments. We study whether an AF admits k-diverse extensions, admits k-diverse extensions covering specific arguments, and to compute the largest k for which an AF admits k-diverse extensions. We outline a prototype and provide an evaluation for computing diversity levels.
Structure-Aware Encodings of Argumentation Properties for Clique-width
Nov 13, 2025
Structural measures of graphs, such as treewidth, are central tools in computational complexity resulting in efficient algorithms when exploiting the parameter. It is even known that modern SAT solvers work efficiently on instances of small treewidth. Since these solvers are widely applied, research interests in compact encodings into (Q)SAT for solving and to understand encoding limitations. Even more general is the graph parameter clique-width, which unlike treewidth can be small for dense graphs. Although algorithms are available for clique-width, little is known about encodings. We initiate the quest to understand encoding capabilities with clique-width by considering abstract argumentation, which is a robust framework for reasoning with conflicting arguments. It is based on directed graphs and asks for computationally challenging properties, making it a natural candidate to study computational properties. We design novel reductions from argumentation problems to (Q)SAT. Our reductions linearly preserve the clique-width, resulting in directed decomposition-guided (DDG) reductions. We establish novel results for all argumentation semantics, including counting. Notably, the overhead caused by our DDG reductions cannot be significantly improved under reasonable assumptions.
Rejection in Abstract Argumentation: Harder Than Acceptance?
Aug 20, 2024Abstract argumentation is a popular toolkit for modeling, evaluating, and comparing arguments. Relationships between arguments are specified in argumentation frameworks (AFs), and conditions are placed on sets (extensions) of arguments that allow AFs to be evaluated. For more expressiveness, AFs are augmented with \emph{acceptance conditions} on directly interacting arguments or a constraint on the admissible sets of arguments, resulting in dialectic frameworks or constrained argumentation frameworks. In this paper, we consider flexible conditions for \emph{rejecting} an argument from an extension, which we call rejection conditions (RCs). On the technical level, we associate each argument with a specific logic program. We analyze the resulting complexity, including the structural parameter treewidth. Rejection AFs are highly expressive, giving rise to natural problems on higher levels of the polynomial hierarchy.
IASCAR: Incremental Answer Set Counting by Anytime Refinement
Nov 13, 2023Answer set programming (ASP) is a popular declarative programming paradigm with various applications. Programs can easily have many answer sets that cannot be enumerated in practice, but counting still allows quantifying solution spaces. If one counts under assumptions on literals, one obtains a tool to comprehend parts of the solution space, so-called answer set navigation. However, navigating through parts of the solution space requires counting many times, which is expensive in theory. Knowledge compilation compiles instances into representations on which counting works in polynomial time. However, these techniques exist only for CNF formulas, and compiling ASP programs into CNF formulas can introduce an exponential overhead. This paper introduces a technique to iteratively count answer sets under assumptions on knowledge compilations of CNFs that encode supported models. Our anytime technique uses the inclusion-exclusion principle to improve bounds by over- and undercounting systematically. In a preliminary empirical analysis, we demonstrate promising results. After compiling the input (offline phase), our approach quickly (re)counts.
Solving Projected Model Counting by Utilizing Treewidth and its Limits
May 31, 2023In this paper, we introduce a novel algorithm to solve projected model counting (PMC). PMC asks to count solutions of a Boolean formula with respect to a given set of projection variables, where multiple solutions that are identical when restricted to the projection variables count as only one solution. Inspired by the observation that the so-called "treewidth" is one of the most prominent structural parameters, our algorithm utilizes small treewidth of the primal graph of the input instance. More precisely, it runs in time O(2^2k+4n2) where k is the treewidth and n is the input size of the instance. In other words, we obtain that the problem PMC is fixed-parameter tractable when parameterized by treewidth. Further, we take the exponential time hypothesis (ETH) into consideration and establish lower bounds of bounded treewidth algorithms for PMC, yielding asymptotically tight runtime bounds of our algorithm. While the algorithm above serves as a first theoretical upper bound and although it might be quite appealing for small values of k, unsurprisingly a naive implementation adhering to this runtime bound suffers already from instances of relatively small width. Therefore, we turn our attention to several measures in order to resolve this issue towards exploiting treewidth in practice: We present a technique called nested dynamic programming, where different levels of abstractions of the primal graph are used to (recursively) compute and refine tree decompositions of a given instance. Finally, we provide a nested dynamic programming algorithm and an implementation that relies on database technology for PMC and a prominent special case of PMC, namely model counting (#Sat). Experiments indicate that the advancements are promising, allowing us to solve instances of treewidth upper bounds beyond 200.
A Quantitative Symbolic Approach to Individual Human Reasoning
May 10, 2022

Cognitive theories for reasoning are about understanding how humans come to conclusions from a set of premises. Starting from hypothetical thoughts, we are interested which are the implications behind basic everyday language and how do we reason with them. A widely studied topic is whether cognitive theories can account for typical reasoning tasks and be confirmed by own empirical experiments. This paper takes a different view and we do not propose a theory, but instead take findings from the literature and show how these, formalized as cognitive principles within a logical framework, can establish a quantitative notion of reasoning, which we call plausibility. For this purpose, we employ techniques from non-monotonic reasoning and computer science, namely, a solving paradigm called answer set programming (ASP). Finally, we can fruitfully use plausibility reasoning in ASP to test the effects of an existing experiment and explain different majority responses.
Rushing and Strolling among Answer Sets -- Navigation Made Easy
Dec 14, 2021

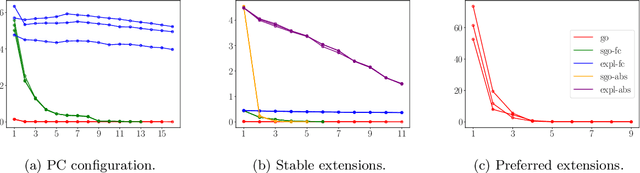
Answer set programming (ASP) is a popular declarative programming paradigm with a wide range of applications in artificial intelligence. Oftentimes, when modeling an AI problem with ASP, and in particular when we are interested beyond simple search for optimal solutions, an actual solution, differences between solutions, or number of solutions of the ASP program matter. For example, when a user aims to identify a specific answer set according to her needs, or requires the total number of diverging solutions to comprehend probabilistic applications such as reasoning in medical domains. Then, there are only certain problem specific and handcrafted encoding techniques available to navigate the solution space of ASP programs, which is oftentimes not enough. In this paper, we propose a formal and general framework for interactive navigation towards desired subsets of answer sets analogous to faceted browsing. Our approach enables the user to explore the solution space by consciously zooming in or out of sub-spaces of solutions at a certain configurable pace. We illustrate that weighted faceted navigation is computationally hard. Finally, we provide an implementation of our approach that demonstrates the feasibility of our framework for incomprehensible solution spaces.
The Model Counting Competition 2020
Dec 02, 2020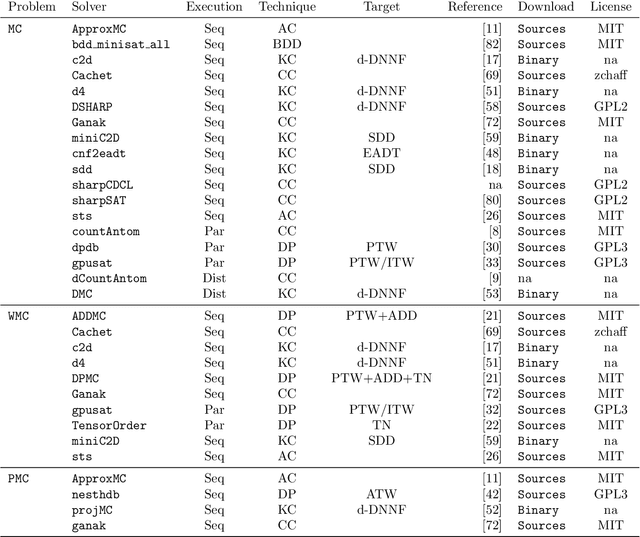
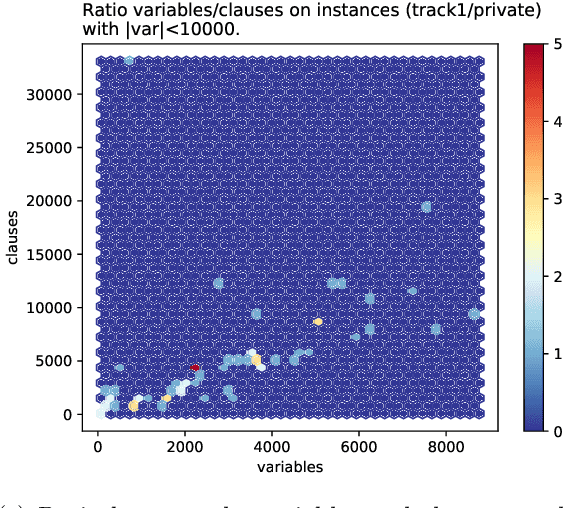
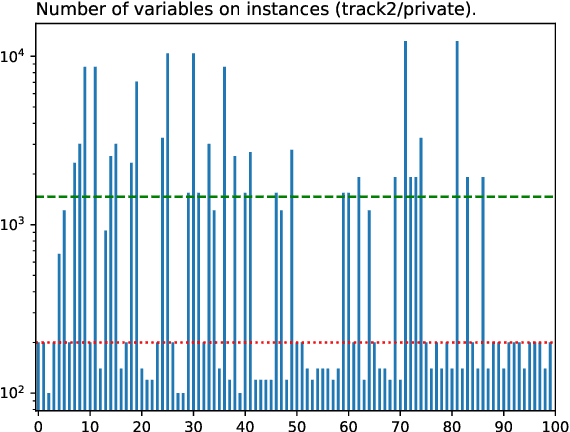
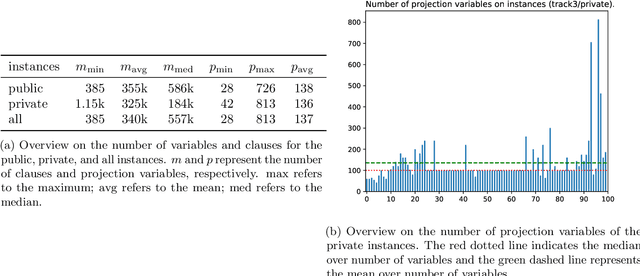
Many computational problems in modern society account to probabilistic reasoning, statistics, and combinatorics. A variety of these real-world questions can be solved by representing the question in (Boolean) formulas and associating the number of models of the formula directly with the answer to the question. Since there has been an increasing interest in practical problem solving for model counting over the last years, the Model Counting (MC) Competition was conceived in fall 2019. The competition aims to foster applications, identify new challenging benchmarks, and to promote new solvers and improve established solvers for the model counting problem and versions thereof. We hope that the results can be a good indicator of the current feasibility of model counting and spark many new applications. In this paper, we report on details of the Model Counting Competition 2020, about carrying out the competition, and the results. The competition encompassed three versions of the model counting problem, which we evaluated in separate tracks. The first track featured the model counting problem (MC), which asks for the number of models of a given Boolean formula. On the second track, we challenged developers to submit programs that solve the weighted model counting problem (WMC). The last track was dedicated to projected model counting (PMC). In total, we received a surprising number of 9 solvers in 34 versions from 8 groups.
Solving the Steiner Tree Problem with few Terminals
Nov 09, 2020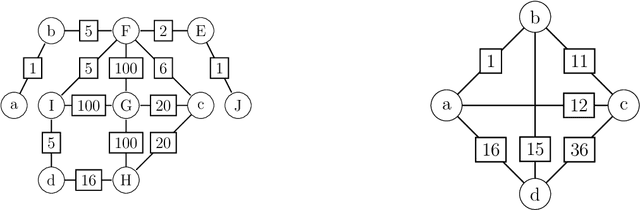
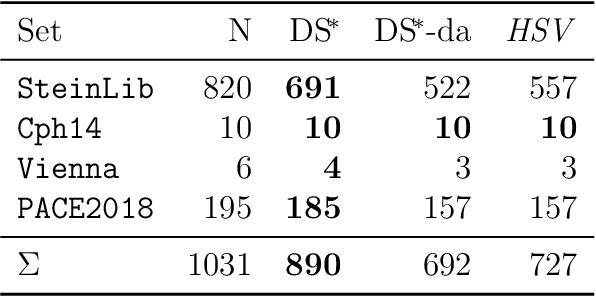
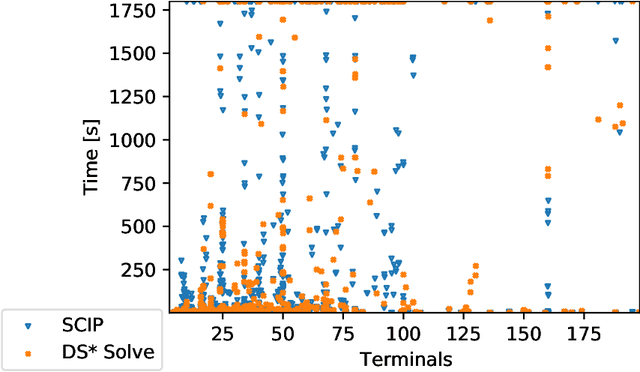
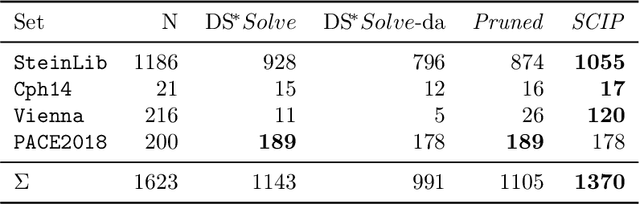
The Steiner tree problem is a well-known problem in network design, routing, and VLSI design. Given a graph, edge costs, and a set of dedicated vertices (terminals), the Steiner tree problem asks to output a sub-graph that connects all terminals at minimum cost. A state-of-the-art algorithm to solve the Steiner tree problem by means of dynamic programming is the Dijkstra-Steiner algorithm. The algorithm builds a Steiner tree of the entire instance by systematically searching for smaller instances, based on subsets of the terminals, and combining Steiner trees for these smaller instances. The search heavily relies on a guiding heuristic function in order to prune the search space. However, to ensure correctness, this algorithm allows only for limited heuristic functions, namely, those that satisfy a so-called consistency condition. In this paper, we enhance the Dijkstra-Steiner algorithm and establish a revisited algorithm, called DS*. The DS* algorithm allows for arbitrary lower bounds as heuristics relaxing the previous condition on the heuristic function. Notably, we can now use linear programming based lower bounds. Further, we capture new requirements for a heuristic function in a condition, which we call admissibility. We show that admissibility is indeed weaker than consistency and establish correctness of the DS* algorithm when using an admissible heuristic function. We implement DS* and combine it with modern preprocessing, resulting in an open-source solver (DS* Solve). Finally, we compare its performance on standard benchmarks and observe a competitive behavior.
A Time Leap Challenge for SAT Solving
Aug 05, 2020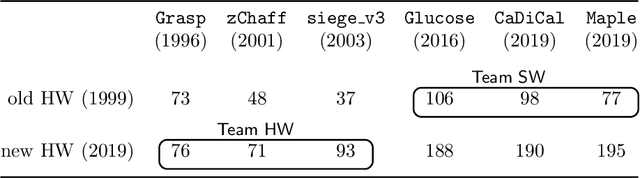
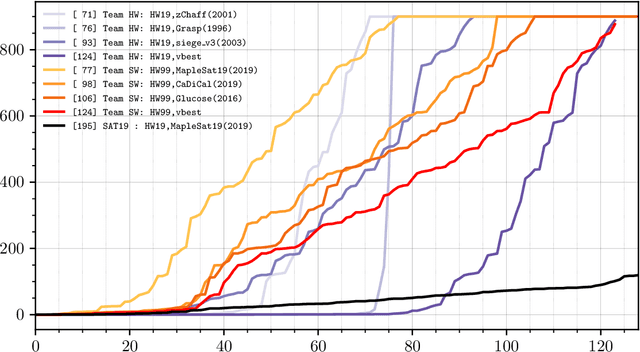
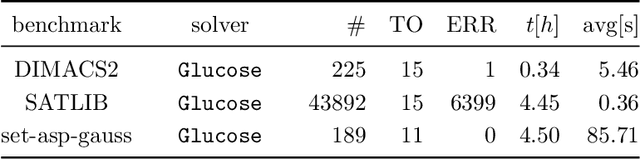
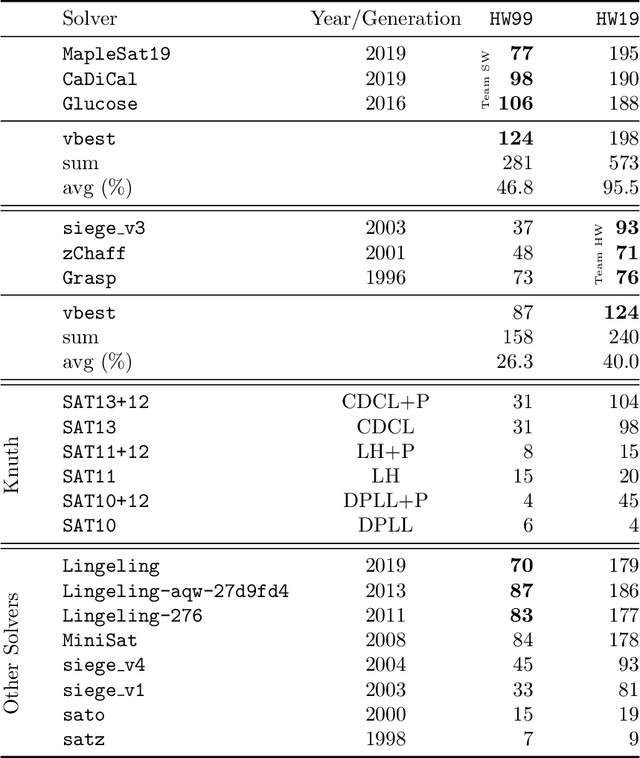
We compare the impact of hardware advancement and algorithm advancement for SAT solving over the last two decades. In particular, we compare 20-year-old SAT-solvers on new computer hardware with modern SAT-solvers on 20-year-old hardware. Our findings show that the progress on the algorithmic side has at least as much impact as the progress on the hardware side.