 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Brittleness in Sequence Models: on Systematic Generalization in Symbolic Mathematics
Sep 28, 2021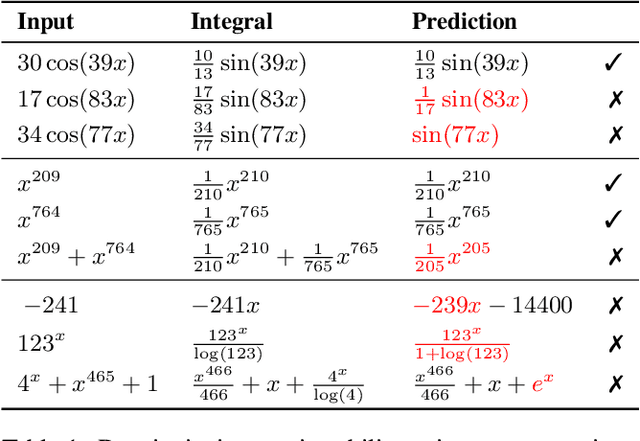
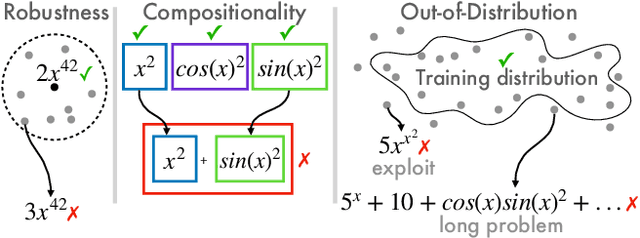

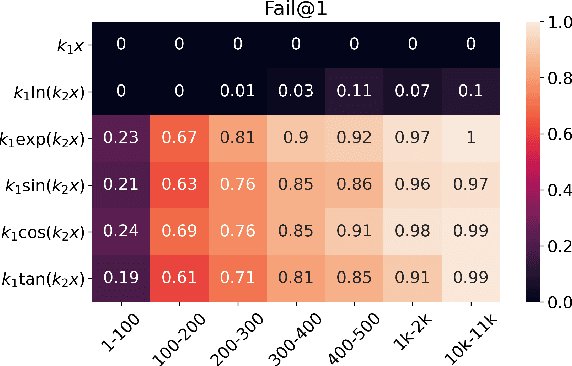
Neural sequence models trained with maximum likelihood estimation have led to breakthroughs in many tasks, where success is defined by the gap between training and test performance. However, their ability to achieve stronger forms of generalization remains unclear. We consider the problem of symbolic mathematical integration, as it requires generalizing systematically beyond the test set. We develop a methodology for evaluating generalization that takes advantage of the problem domain's structure and access to a verifier. Despite promising in-distribution performance of sequence-to-sequence models in this domain, we demonstrate challenges in achieving robustness, compositionality, and out-of-distribution generalization, through both carefully constructed manual test suites and a genetic algorithm that automatically finds large collections of failures in a controllable manner. Our investigation highlights the difficulty of generalizing well with the predominant modeling and learning approach, and the importance of evaluating beyond the test set, across different aspects of generalization.
MERLOT: Multimodal Neural Script Knowledge Models
Jun 10, 2021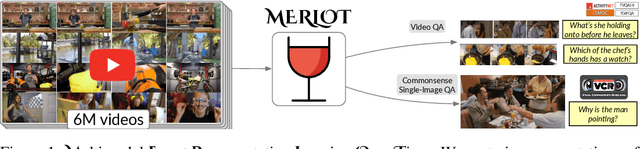
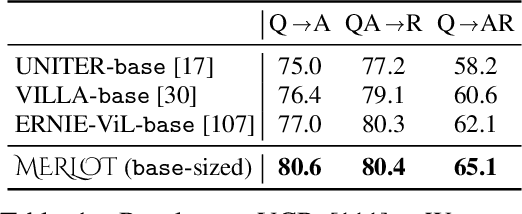
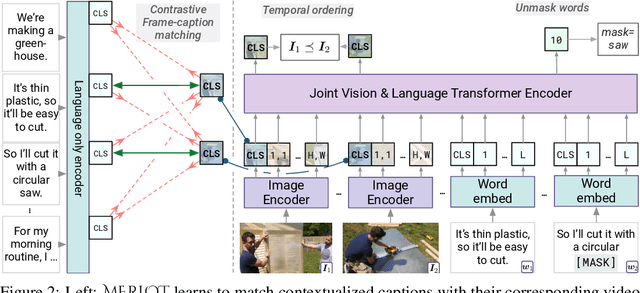
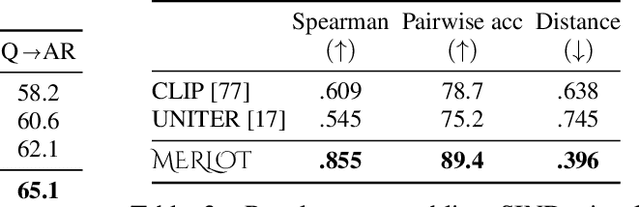
As humans, we understand events in the visual world contextually, performing multimodal reasoning across time to make inferences about the past, present, and future. We introduce MERLOT, a model that learns multimodal script knowledge by watching millions of YouTube videos with transcribed speech -- in an entirely label-free, self-supervised manner. By pretraining with a mix of both frame-level (spatial) and video-level (temporal) objectives, our model not only learns to match images to temporally corresponding words, but also to contextualize what is happening globally over time. As a result, MERLOT exhibits strong out-of-the-box representations of temporal commonsense, and achieves state-of-the-art performance on 12 different video QA datasets when finetuned. It also transfers well to the world of static images, allowing models to reason about the dynamic context behind visual scenes. On Visual Commonsense Reasoning, MERLOT answers questions correctly with 80.6% accuracy, outperforming state-of-the-art models of similar size by over 3%, even those that make heavy use of auxiliary supervised data (like object bounding boxes). Ablation analyses demonstrate the complementary importance of: 1) training on videos versus static images; 2) scaling the magnitude and diversity of the pretraining video corpus; and 3) using diverse objectives that encourage full-stack multimodal reasoning, from the recognition to cognition level.
Behind the Scene: Revealing the Secrets of Pre-trained Vision-and-Language Models
May 15, 2020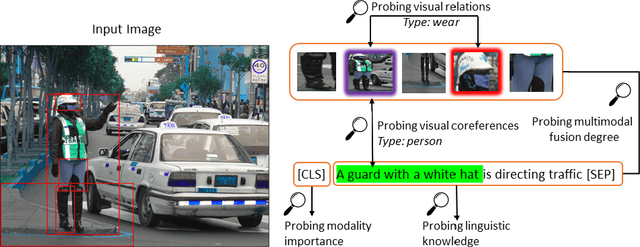


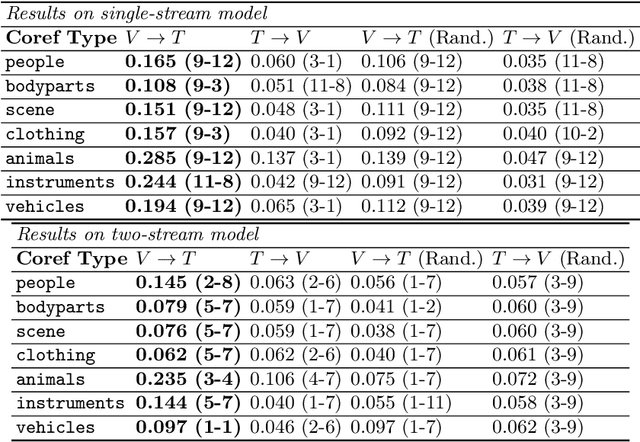
Recent Transformer-based large-scale pre-trained models have revolutionized vision-and-language (V+L) research. Models such as ViLBERT, LXMERT and UNITER have significantly lifted state of the art across a wide range of V+L benchmarks with joint image-text pre-training. However, little is known about the inner mechanisms that destine their impressive success. To reveal the secrets behind the scene of these powerful models, we present VALUE (Vision-And-Language Understanding Evaluation), a set of meticulously designed probing tasks (e.g., Visual Coreference Resolution, Visual Relation Detection, Linguistic Probing Tasks) generalizable to standard pre-trained V+L models, aiming to decipher the inner workings of multimodal pre-training (e.g., the implicit knowledge garnered in individual attention heads, the inherent cross-modal alignment learned through contextualized multimodal embeddings). Through extensive analysis of each archetypal model architecture via these probing tasks, our key observations are: (i) Pre-trained models exhibit a propensity for attending over text rather than images during inference. (ii) There exists a subset of attention heads that are tailored for capturing cross-modal interactions. (iii) Learned attention matrix in pre-trained models demonstrates patterns coherent with the latent alignment between image regions and textual words. (iv) Plotted attention patterns reveal visually-interpretable relations among image regions. (v) Pure linguistic knowledge is also effectively encoded in the attention heads. These are valuable insights serving to guide future work towards designing better model architecture and objectives for multimodal pre-training.