 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Brittleness in Sequence Models: on Systematic Generalization in Symbolic Mathematics
Paper and Code
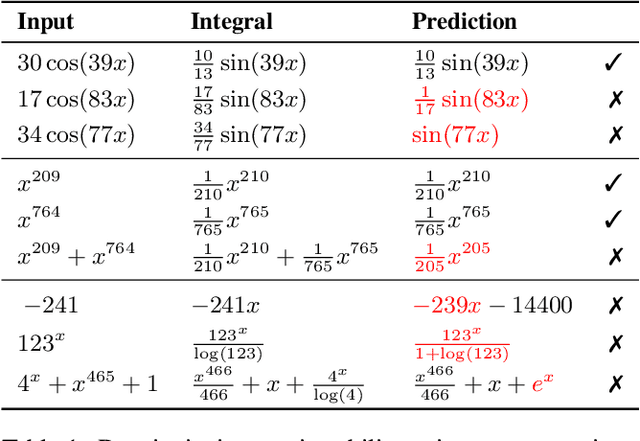
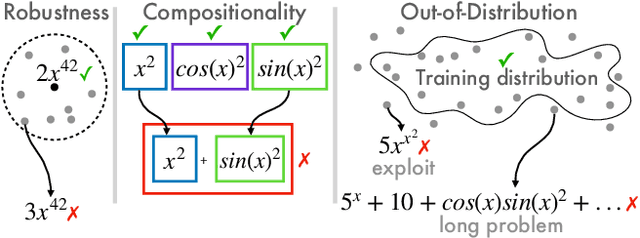

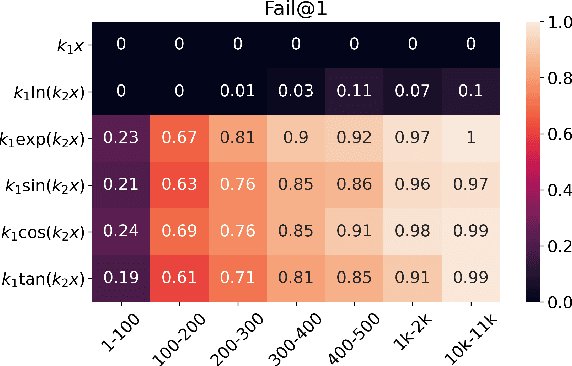
Neural sequence models trained with maximum likelihood estimation have led to breakthroughs in many tasks, where success is defined by the gap between training and test performance. However, their ability to achieve stronger forms of generalization remains unclear. We consider the problem of symbolic mathematical integration, as it requires generalizing systematically beyond the test set. We develop a methodology for evaluating generalization that takes advantage of the problem domain's structure and access to a verifier. Despite promising in-distribution performance of sequence-to-sequence models in this domain, we demonstrate challenges in achieving robustness, compositionality, and out-of-distribution generalization, through both carefully constructed manual test suites and a genetic algorithm that automatically finds large collections of failures in a controllable manner. Our investigation highlights the difficulty of generalizing well with the predominant modeling and learning approach, and the importance of evaluating beyond the test set, across different aspects of generalization.