 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Uncertainty Calibration of Deep Neural Networks via Truth Discovery and Geometric Optimization
Jun 25, 2021
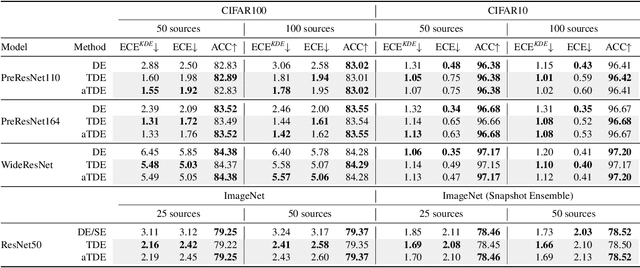

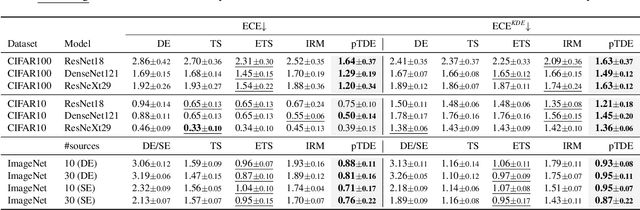
Deep Neural Networks (DNNs), despite their tremendous success in recent years, could still cast doubts on their predictions due to the intrinsic uncertainty associated with their learning process. Ensemble techniques and post-hoc calibrations are two types of approaches that have individually shown promise in improving the uncertainty calibration of DNNs. However, the synergistic effect of the two types of methods has not been well explored. In this paper, we propose a truth discovery framework to integrate ensemble-based and post-hoc calibration methods. Using the geometric variance of the ensemble candidates as a good indicator for sample uncertainty, we design an accuracy-preserving truth estimator with provably no accuracy drop. Furthermore, we show that post-hoc calibration can also be enhanced by truth discovery-regularized optimization. On large-scale datasets including CIFAR and ImageNet, our method shows consistent improvement against state-of-the-art calibration approaches on both histogram-based and kernel density-based evaluation metrics. Our codes are available at https://github.com/horsepurve/truly-uncertain.
Meta-Learning with Neural Tangent Kernels
Feb 09, 2021
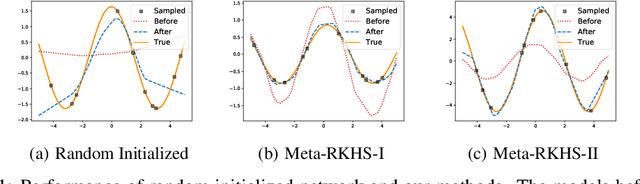

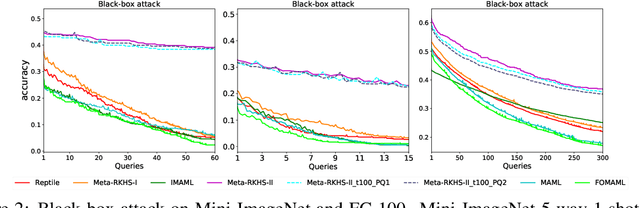
Model Agnostic Meta-Learning (MAML) has emerged as a standard framework for meta-learning, where a meta-model is learned with the ability of fast adapting to new tasks. However, as a double-looped optimization problem, MAML needs to differentiate through the whole inner-loop optimization path for every outer-loop training step, which may lead to both computational inefficiency and sub-optimal solutions. In this paper, we generalize MAML to allow meta-learning to be defined in function spaces, and propose the first meta-learning paradigm in the Reproducing Kernel Hilbert Space (RKHS) induced by the meta-model's Neural Tangent Kernel (NTK). Within this paradigm, we introduce two meta-learning algorithms in the RKHS, which no longer need a sub-optimal iterative inner-loop adaptation as in the MAML framework. We achieve this goal by 1) replacing the adaptation with a fast-adaptive regularizer in the RKHS; and 2) solving the adaptation analytically based on the NTK theory. Extensive experimental studies demonstrate advantages of our paradigm in both efficiency and quality of solutions compared to related meta-learning algorithms. Another interesting feature of our proposed methods is that they are demonstrated to be more robust to adversarial attacks and out-of-distribution adaptation than popular baselines, as demonstrated in our experiments.
Consistent $k$-Median: Simpler, Better and Robust
Aug 13, 2020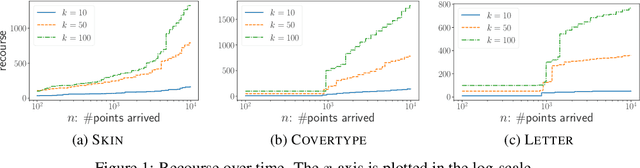
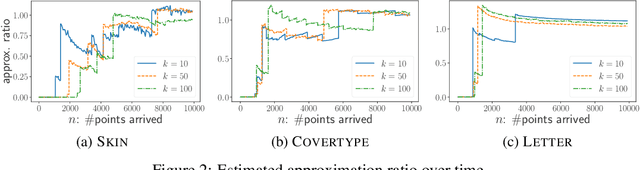
In this paper we introduce and study the online consistent $k$-clustering with outliers problem, generalizing the non-outlier version of the problem studied in [Lattanzi-Vassilvitskii, ICML17]. We show that a simple local-search based online algorithm can give a bicriteria constant approximation for the problem with $O(k^2 \log^2 (nD))$ swaps of medians (recourse) in total, where $D$ is the diameter of the metric. When restricted to the problem without outliers, our algorithm is simpler, deterministic and gives better approximation ratio and recourse, compared to that of [Lattanzi-Vassilvitskii, ICML17].
Graph Neural Networks with Composite Kernels
May 16, 2020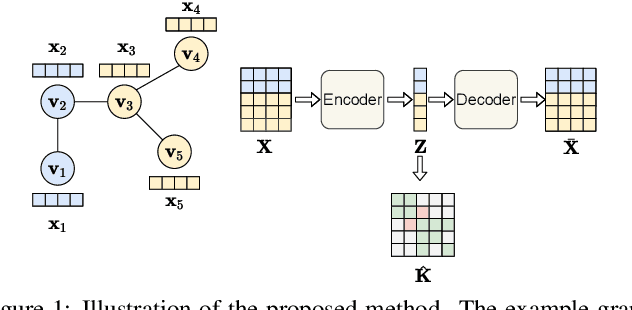

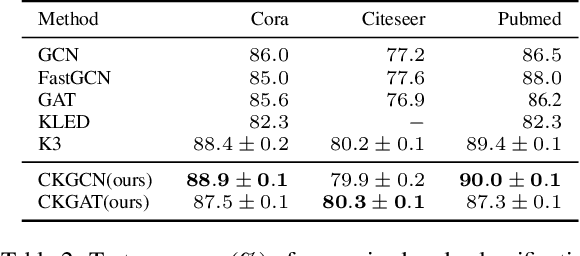

Learning on graph structured data has drawn increasing interest in recent years. Frameworks like Graph Convolutional Networks (GCNs) have demonstrated their ability to capture structural information and obtain good performance in various tasks. In these frameworks, node aggregation schemes are typically used to capture structural information: a node's feature vector is recursively computed by aggregating features of its neighboring nodes. However, most of aggregation schemes treat all connections in a graph equally, ignoring node feature similarities. In this paper, we re-interpret node aggregation from the perspective of kernel weighting, and present a framework to consider feature similarity in an aggregation scheme. Specifically, we show that normalized adjacency matrix is equivalent to a neighbor-based kernel matrix in a Krein Space. We then propose feature aggregation as the composition of the original neighbor-based kernel and a learnable kernel to encode feature similarities in a feature space. We further show how the proposed method can be extended to Graph Attention Network (GAT). Experimental results demonstrate better performance of our proposed framework in several real-world applications.