 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetadata Matters for Time Series: Informative Forecasting with Transformers
Oct 04, 2024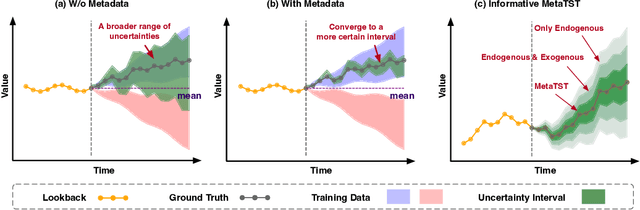



Time series forecasting is prevalent in extensive real-world applications, such as financial analysis and energy planning. Previous studies primarily focus on time series modality, endeavoring to capture the intricate variations and dependencies inherent in time series. Beyond numerical time series data, we notice that metadata (e.g.~dataset and variate descriptions) also carries valuable information essential for forecasting, which can be used to identify the application scenario and provide more interpretable knowledge than digit sequences. Inspired by this observation, we propose a Metadata-informed Time Series Transformer (MetaTST), which incorporates multiple levels of context-specific metadata into Transformer forecasting models to enable informative time series forecasting. To tackle the unstructured nature of metadata, MetaTST formalizes them into natural languages by pre-designed templates and leverages large language models (LLMs) to encode these texts into metadata tokens as a supplement to classic series tokens, resulting in an informative embedding. Further, a Transformer encoder is employed to communicate series and metadata tokens, which can extend series representations by metadata information for more accurate forecasting. This design also allows the model to adaptively learn context-specific patterns across various scenarios, which is particularly effective in handling large-scale, diverse-scenario forecasting tasks. Experimentally, MetaTST achieves state-of-the-art compared to advanced time series models and LLM-based methods on widely acknowledged short- and long-term forecasting benchmarks, covering both single-dataset individual and multi-dataset joint training settings.
Deep Time Series Models: A Comprehensive Survey and Benchmark
Jul 18, 2024



Time series, characterized by a sequence of data points arranged in a discrete-time order, are ubiquitous in real-world applications. Different from other modalities, time series present unique challenges due to their complex and dynamic nature, including the entanglement of nonlinear patterns and time-variant trends. Analyzing time series data is of great significance in real-world scenarios and has been widely studied over centuries. Recent years have witnessed remarkable breakthroughs in the time series community, with techniques shifting from traditional statistical methods to advanced deep learning models. In this paper, we delve into the design of deep time series models across various analysis tasks and review the existing literature from two perspectives: basic modules and model architectures. Further, we develop and release Time Series Library (TSLib) as a fair benchmark of deep time series models for diverse analysis tasks, which implements 24 mainstream models, covers 30 datasets from different domains, and supports five prevalent analysis tasks. Based on TSLib, we thoroughly evaluate 12 advanced deep time series models on different tasks. Empirical results indicate that models with specific structures are well-suited for distinct analytical tasks, which offers insights for research and adoption of deep time series models. Code is available at https://github.com/thuml/Time-Series-Library.
Diffusion Tuning: Transferring Diffusion Models via Chain of Forgetting
Jun 02, 2024
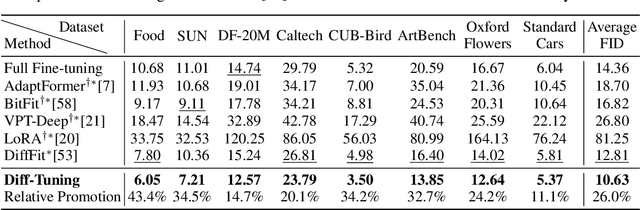
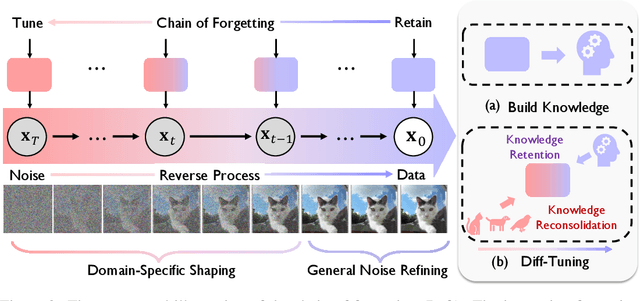

Diffusion models have significantly advanced the field of generative modeling. However, training a diffusion model is computationally expensive, creating a pressing need to adapt off-the-shelf diffusion models for downstream generation tasks. Current fine-tuning methods focus on parameter-efficient transfer learning but overlook the fundamental transfer characteristics of diffusion models. In this paper, we investigate the transferability of diffusion models and observe a monotonous chain of forgetting trend of transferability along the reverse process. Based on this observation and novel theoretical insights, we present Diff-Tuning, a frustratingly simple transfer approach that leverages the chain of forgetting tendency. Diff-Tuning encourages the fine-tuned model to retain the pre-trained knowledge at the end of the denoising chain close to the generated data while discarding the other noise side. We conduct comprehensive experiments to evaluate Diff-Tuning, including the transfer of pre-trained Diffusion Transformer models to eight downstream generations and the adaptation of Stable Diffusion to five control conditions with ControlNet. Diff-Tuning achieves a 26% improvement over standard fine-tuning and enhances the convergence speed of ControlNet by 24%. Notably, parameter-efficient transfer learning techniques for diffusion models can also benefit from Diff-Tuning.
TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables
Feb 29, 2024



Recent studies have demonstrated remarkable performance in time series forecasting. However, due to the partially-observed nature of real-world applications, solely focusing on the target of interest, so-called endogenous variables, is usually insufficient to guarantee accurate forecasting. Notably, a system is often recorded into multiple variables, where the exogenous series can provide valuable external information for endogenous variables. Thus, unlike prior well-established multivariate or univariate forecasting that either treats all the variables equally or overlooks exogenous information, this paper focuses on a practical setting, which is time series forecasting with exogenous variables. We propose a novel framework, TimeXer, to utilize external information to enhance the forecasting of endogenous variables. With a deftly designed embedding layer, TimeXer empowers the canonical Transformer architecture with the ability to reconcile endogenous and exogenous information, where patch-wise self-attention and variate-wise cross-attention are employed. Moreover, a global endogenous variate token is adopted to effectively bridge the exogenous series into endogenous temporal patches. Experimentally, TimeXer significantly improves time series forecasting with exogenous variables and achieves consistent state-of-the-art performance in twelve real-world forecasting benchmarks.
TimeSiam: A Pre-Training Framework for Siamese Time-Series Modeling
Feb 04, 2024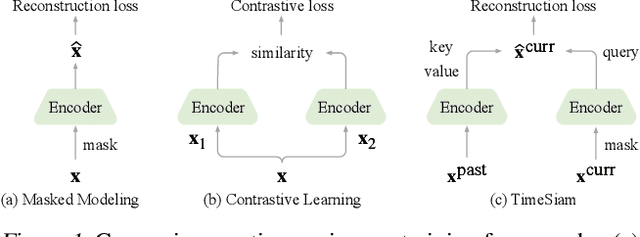
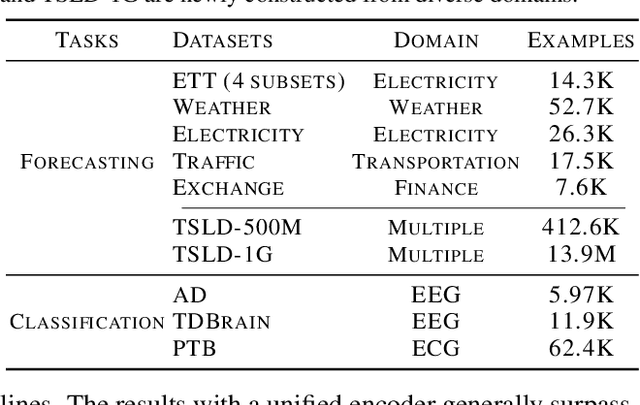
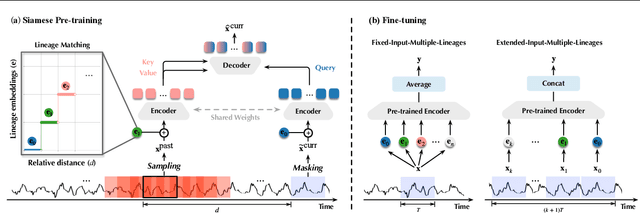
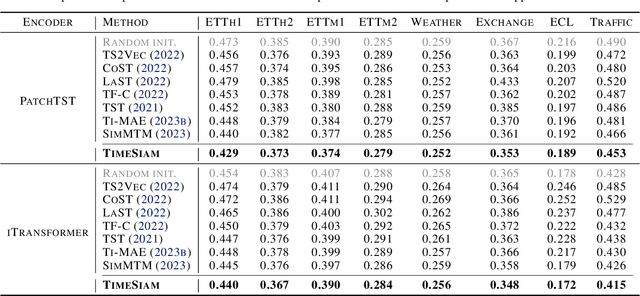
Time series pre-training has recently garnered wide attention for its potential to reduce labeling expenses and benefit various downstream tasks. Prior methods are mainly based on pre-training techniques well-acknowledged in vision or language, such as masked modeling and contrastive learning. However, randomly masking time series or calculating series-wise similarity will distort or neglect inherent temporal correlations crucial in time series data. To emphasize temporal correlation modeling, this paper proposes TimeSiam as a simple but effective self-supervised pre-training framework for Time series based on Siamese networks. Concretely, TimeSiam pre-trains Siamese encoders to capture intrinsic temporal correlations between randomly sampled past and current subseries. With a simple data augmentation method (e.g.~masking), TimeSiam can benefit from diverse augmented subseries and learn internal time-dependent representations through a past-to-current reconstruction. Moreover, learnable lineage embeddings are also introduced to distinguish temporal distance between sampled series and further foster the learning of diverse temporal correlations. TimeSiam consistently outperforms extensive advanced pre-training baselines, demonstrating superior forecasting and classification capabilities across 13 standard benchmarks in both intra- and cross-domain scenarios.
SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling
Feb 03, 2023Time series analysis is widely used in extensive areas. Recently, to reduce labeling expenses and benefit various tasks, self-supervised pre-training has attracted immense interest. One mainstream paradigm is masked modeling, which successfully pre-trains deep models by learning to reconstruct the masked content based on the unmasked part. However, since the semantic information of time series is mainly contained in temporal variations, the standard way of randomly masking a portion of time points will ruin vital temporal variations of time series seriously, making the reconstruction task too difficult to guide representation learning. We thus present SimMTM, a Simple pre-training framework for Masked Time-series Modeling. By relating masked modeling to manifold learning, SimMTM proposes to recover masked time points by the weighted aggregation of multiple neighbors outside the manifold, which eases the reconstruction task by assembling ruined but complementary temporal variations from multiple masked series. SimMTM further learns to uncover the local structure of the manifold helpful for masked modeling. Experimentally, SimMTM achieves state-of-the-art fine-tuning performance in two canonical time series analysis tasks: forecasting and classification, covering both in- and cross-domain settings.