 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Noise Shift for Denoising Generative Models via Noise Awareness Guidance
Oct 14, 2025Existing denoising generative models rely on solving discretized reverse-time SDEs or ODEs. In this paper, we identify a long-overlooked yet pervasive issue in this family of models: a misalignment between the pre-defined noise level and the actual noise level encoded in intermediate states during sampling. We refer to this misalignment as noise shift. Through empirical analysis, we demonstrate that noise shift is widespread in modern diffusion models and exhibits a systematic bias, leading to sub-optimal generation due to both out-of-distribution generalization and inaccurate denoising updates. To address this problem, we propose Noise Awareness Guidance (NAG), a simple yet effective correction method that explicitly steers sampling trajectories to remain consistent with the pre-defined noise schedule. We further introduce a classifier-free variant of NAG, which jointly trains a noise-conditional and a noise-unconditional model via noise-condition dropout, thereby eliminating the need for external classifiers. Extensive experiments, including ImageNet generation and various supervised fine-tuning tasks, show that NAG consistently mitigates noise shift and substantially improves the generation quality of mainstream diffusion models.
Domain Guidance: A Simple Transfer Approach for a Pre-trained Diffusion Model
Apr 02, 2025Recent advancements in diffusion models have revolutionized generative modeling. However, the impressive and vivid outputs they produce often come at the cost of significant model scaling and increased computational demands. Consequently, building personalized diffusion models based on off-the-shelf models has emerged as an appealing alternative. In this paper, we introduce a novel perspective on conditional generation for transferring a pre-trained model. From this viewpoint, we propose *Domain Guidance*, a straightforward transfer approach that leverages pre-trained knowledge to guide the sampling process toward the target domain. Domain Guidance shares a formulation similar to advanced classifier-free guidance, facilitating better domain alignment and higher-quality generations. We provide both empirical and theoretical analyses of the mechanisms behind Domain Guidance. Our experimental results demonstrate its substantial effectiveness across various transfer benchmarks, achieving over a 19.6% improvement in FID and a 23.4% improvement in FD$_\text{DINOv2}$ compared to standard fine-tuning. Notably, existing fine-tuned models can seamlessly integrate Domain Guidance to leverage these benefits, without additional training.
Diffusion Tuning: Transferring Diffusion Models via Chain of Forgetting
Jun 02, 2024
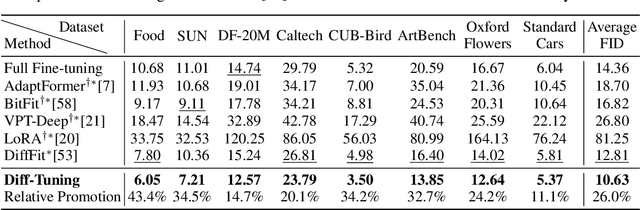
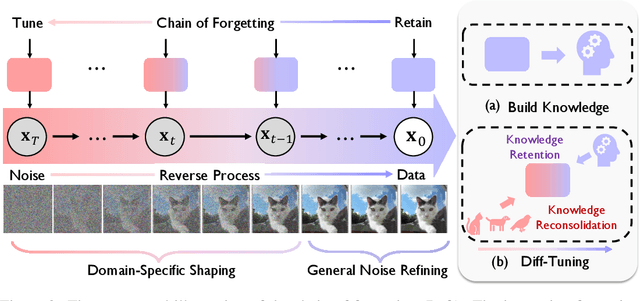

Diffusion models have significantly advanced the field of generative modeling. However, training a diffusion model is computationally expensive, creating a pressing need to adapt off-the-shelf diffusion models for downstream generation tasks. Current fine-tuning methods focus on parameter-efficient transfer learning but overlook the fundamental transfer characteristics of diffusion models. In this paper, we investigate the transferability of diffusion models and observe a monotonous chain of forgetting trend of transferability along the reverse process. Based on this observation and novel theoretical insights, we present Diff-Tuning, a frustratingly simple transfer approach that leverages the chain of forgetting tendency. Diff-Tuning encourages the fine-tuned model to retain the pre-trained knowledge at the end of the denoising chain close to the generated data while discarding the other noise side. We conduct comprehensive experiments to evaluate Diff-Tuning, including the transfer of pre-trained Diffusion Transformer models to eight downstream generations and the adaptation of Stable Diffusion to five control conditions with ControlNet. Diff-Tuning achieves a 26% improvement over standard fine-tuning and enhances the convergence speed of ControlNet by 24%. Notably, parameter-efficient transfer learning techniques for diffusion models can also benefit from Diff-Tuning.
Bi-tuning of Pre-trained Representations
Nov 12, 2020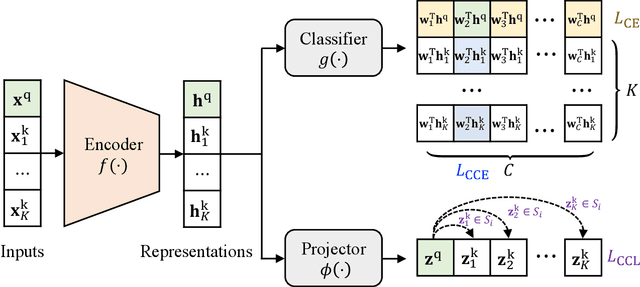
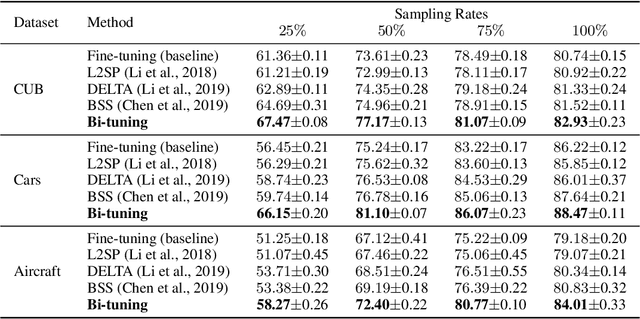
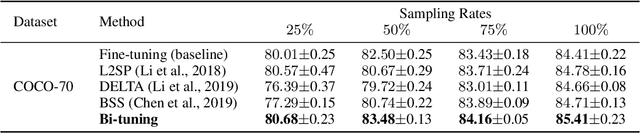
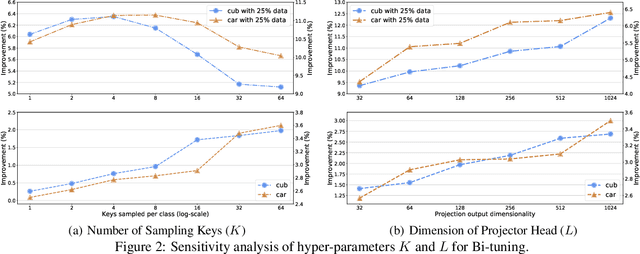
It is common within the deep learning community to first pre-train a deep neural network from a large-scale dataset and then fine-tune the pre-trained model to a specific downstream task. Recently, both supervised and unsupervised pre-training approaches to learning representations have achieved remarkable advances, which exploit the discriminative knowledge of labels and the intrinsic structure of data, respectively. It follows natural intuition that both discriminative knowledge and intrinsic structure of the downstream task can be useful for fine-tuning, however, existing fine-tuning methods mainly leverage the former and discard the latter. A question arises: How to fully explore the intrinsic structure of data for boosting fine-tuning? In this paper, we propose Bi-tuning, a general learning framework to fine-tuning both supervised and unsupervised pre-trained representations to downstream tasks. Bi-tuning generalizes the vanilla fine-tuning by integrating two heads upon the backbone of pre-trained representations: a classifier head with an improved contrastive cross-entropy loss to better leverage the label information in an instance-contrast way, and a projector head with a newly-designed categorical contrastive learning loss to fully exploit the intrinsic structure of data in a category-consistent way. Comprehensive experiments confirm that Bi-tuning achieves state-of-the-art results for fine-tuning tasks of both supervised and unsupervised pre-trained models by large margins (e.g. 10.7\% absolute rise in accuracy on CUB in low-data regime).