 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapt Data to Model: Adaptive Transformation Optimization for Domain-shared Time Series Foundation Models
Feb 28, 2026Large time series models (LTMs) have emerged as powerful tools for universal forecasting, yet they often struggle with the inherent diversity and nonstationarity of real-world time series data, leading to an unsatisfactory trade-off between forecasting accuracy and generalization. Rather than continually finetuning new LTM instances for each domain, we propose a data-centric framework, time-series adaptive transformation optimization (TATO), that enables a single frozen pre-trained LTM to adapt to diverse downstream domains through an optimally configured transformation pipeline. Specifically, TATO constructs three representative types of transformations, including context slicing, scale normalization, and outlier correction, to help LTMs better align with target domain characteristics. To ensure robustness, we incorporate carefully selected time series augmentations and a two-stage ranking mechanism that filters out pipelines underperforming on specific metrics. Extensive experiments on state-of-the-art LTMs and widely used datasets demonstrate that TATO consistently and significantly improves domain-adaptive forecasting performance, achieving a maximum reduction in MSE of 65.4\% and an average reduction of 13.6\%. Moreover, TATO is highly efficient, typically completing optimization in under 2 minutes, making it practical for real-world deployment. The source code is available at https://github.com/thulab/TATO.
DiTS: Multimodal Diffusion Transformers Are Time Series Forecasters
Feb 06, 2026While generative modeling on time series facilitates more capable and flexible probabilistic forecasting, existing generative time series models do not address the multi-dimensional properties of time series data well. The prevalent architecture of Diffusion Transformers (DiT), which relies on simplistic conditioning controls and a single-stream Transformer backbone, tends to underutilize cross-variate dependencies in covariate-aware forecasting. Inspired by Multimodal Diffusion Transformers that integrate textual guidance into video generation, we propose Diffusion Transformers for Time Series (DiTS), a general-purpose architecture that frames endogenous and exogenous variates as distinct modalities. To better capture both inter-variate and intra-variate dependencies, we design a dual-stream Transformer block tailored for time-series data, comprising a Time Attention module for autoregressive modeling along the temporal dimension and a Variate Attention module for cross-variate modeling. Unlike the common approach for images, which flattens 2D token grids into 1D sequences, our design leverages the low-rank property inherent in multivariate dependencies, thereby reducing computational costs. Experiments show that DiTS achieves state-of-the-art performance across benchmarks, regardless of the presence of future exogenous variate observations, demonstrating unique generative forecasting strengths over traditional deterministic deep forecasting models.
TimesBERT: A BERT-Style Foundation Model for Time Series Understanding
Feb 28, 2025



Time series analysis is crucial in diverse scenarios. Beyond forecasting, considerable real-world tasks are categorized into classification, imputation, and anomaly detection, underscoring different capabilities termed time series understanding in this paper. While GPT-style models have been positioned as foundation models for time series forecasting, the BERT-style architecture, which has made significant advances in natural language understanding, has not been fully unlocked for time series understanding, possibly attributed to the undesirable dropout of essential elements of BERT. In this paper, inspired by the shared multi-granularity structure between multivariate time series and multisentence documents, we design TimesBERT to learn generic representations of time series including temporal patterns and variate-centric characteristics. In addition to a natural adaptation of masked modeling, we propose a parallel task of functional token prediction to embody vital multi-granularity structures. Our model is pre-trained on 260 billion time points across diverse domains. Leveraging multi-granularity representations, TimesBERT achieves state-of-the-art performance across four typical downstream understanding tasks, outperforming task-specific models and language pre-trained backbones, positioning it as a versatile foundation model for time series understanding.
TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables
Feb 29, 2024



Recent studies have demonstrated remarkable performance in time series forecasting. However, due to the partially-observed nature of real-world applications, solely focusing on the target of interest, so-called endogenous variables, is usually insufficient to guarantee accurate forecasting. Notably, a system is often recorded into multiple variables, where the exogenous series can provide valuable external information for endogenous variables. Thus, unlike prior well-established multivariate or univariate forecasting that either treats all the variables equally or overlooks exogenous information, this paper focuses on a practical setting, which is time series forecasting with exogenous variables. We propose a novel framework, TimeXer, to utilize external information to enhance the forecasting of endogenous variables. With a deftly designed embedding layer, TimeXer empowers the canonical Transformer architecture with the ability to reconcile endogenous and exogenous information, where patch-wise self-attention and variate-wise cross-attention are employed. Moreover, a global endogenous variate token is adopted to effectively bridge the exogenous series into endogenous temporal patches. Experimentally, TimeXer significantly improves time series forecasting with exogenous variables and achieves consistent state-of-the-art performance in twelve real-world forecasting benchmarks.
TimeSiam: A Pre-Training Framework for Siamese Time-Series Modeling
Feb 04, 2024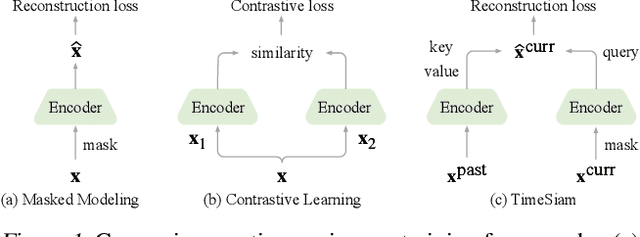
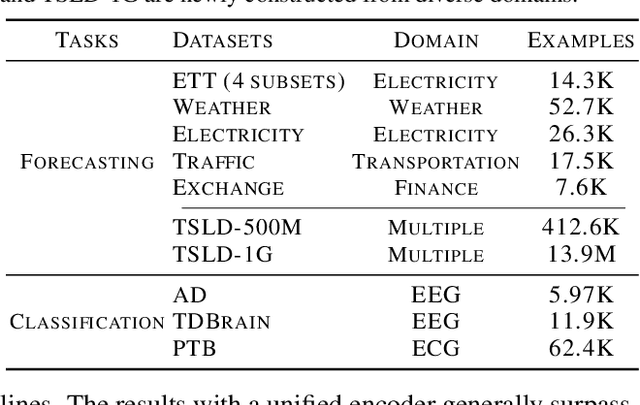
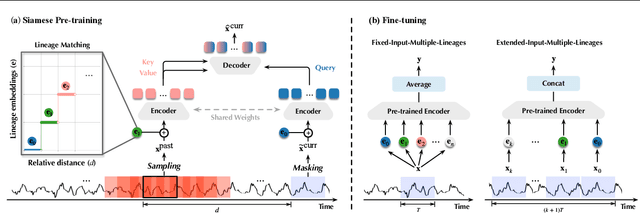
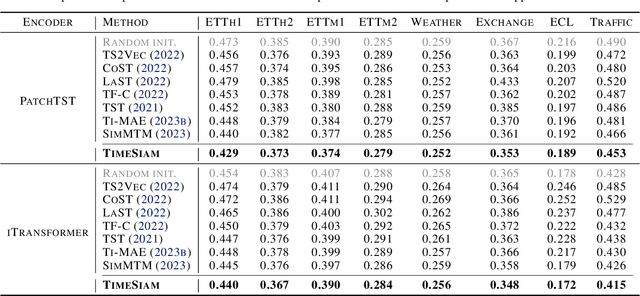
Time series pre-training has recently garnered wide attention for its potential to reduce labeling expenses and benefit various downstream tasks. Prior methods are mainly based on pre-training techniques well-acknowledged in vision or language, such as masked modeling and contrastive learning. However, randomly masking time series or calculating series-wise similarity will distort or neglect inherent temporal correlations crucial in time series data. To emphasize temporal correlation modeling, this paper proposes TimeSiam as a simple but effective self-supervised pre-training framework for Time series based on Siamese networks. Concretely, TimeSiam pre-trains Siamese encoders to capture intrinsic temporal correlations between randomly sampled past and current subseries. With a simple data augmentation method (e.g.~masking), TimeSiam can benefit from diverse augmented subseries and learn internal time-dependent representations through a past-to-current reconstruction. Moreover, learnable lineage embeddings are also introduced to distinguish temporal distance between sampled series and further foster the learning of diverse temporal correlations. TimeSiam consistently outperforms extensive advanced pre-training baselines, demonstrating superior forecasting and classification capabilities across 13 standard benchmarks in both intra- and cross-domain scenarios.