 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation
Jul 18, 2022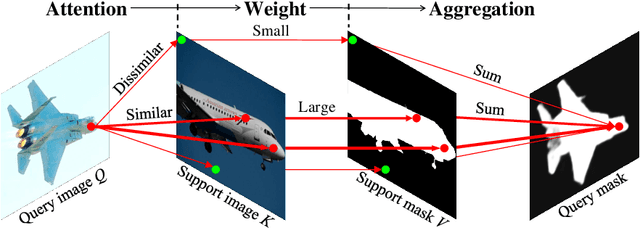


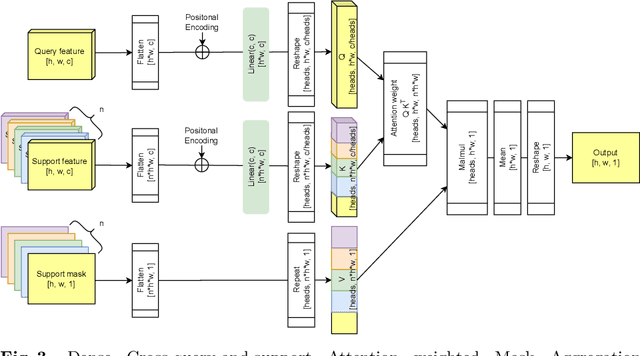
Research into Few-shot Semantic Segmentation (FSS) has attracted great attention, with the goal to segment target objects in a query image given only a few annotated support images of the target class. A key to this challenging task is to fully utilize the information in the support images by exploiting fine-grained correlations between the query and support images. However, most existing approaches either compressed the support information into a few class-wise prototypes, or used partial support information (e.g., only foreground) at the pixel level, causing non-negligible information loss. In this paper, we propose Dense pixel-wise Cross-query-and-support Attention weighted Mask Aggregation (DCAMA), where both foreground and background support information are fully exploited via multi-level pixel-wise correlations between paired query and support features. Implemented with the scaled dot-product attention in the Transformer architecture, DCAMA treats every query pixel as a token, computes its similarities with all support pixels, and predicts its segmentation label as an additive aggregation of all the support pixels' labels -- weighted by the similarities. Based on the unique formulation of DCAMA, we further propose efficient and effective one-pass inference for n-shot segmentation, where pixels of all support images are collected for the mask aggregation at once. Experiments show that our DCAMA significantly advances the state of the art on standard FSS benchmarks of PASCAL-5i, COCO-20i, and FSS-1000, e.g., with 3.1%, 9.7%, and 3.6% absolute improvements in 1-shot mIoU over previous best records. Ablative studies also verify the design DCAMA.
Deformer: Towards Displacement Field Learning for Unsupervised Medical Image Registration
Jul 07, 2022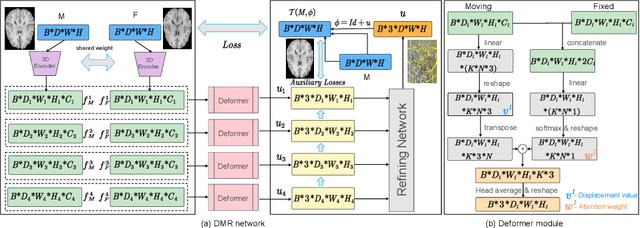
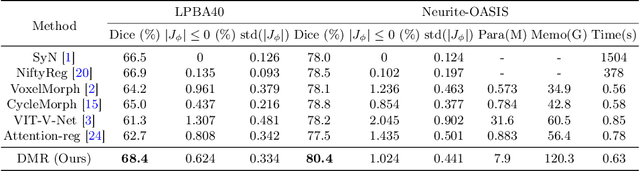
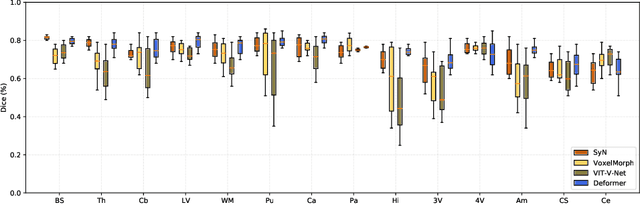
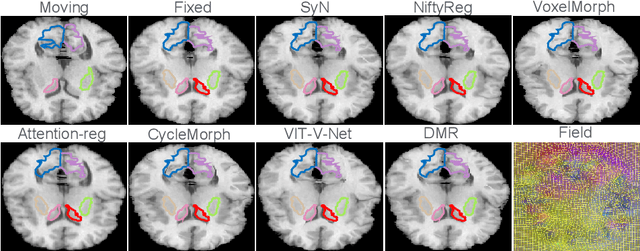
Recently, deep-learning-based approaches have been widely studied for deformable image registration task. However, most efforts directly map the composite image representation to spatial transformation through the convolutional neural network, ignoring its limited ability to capture spatial correspondence. On the other hand, Transformer can better characterize the spatial relationship with attention mechanism, its long-range dependency may be harmful to the registration task, where voxels with too large distances are unlikely to be corresponding pairs. In this study, we propose a novel Deformer module along with a multi-scale framework for the deformable image registration task. The Deformer module is designed to facilitate the mapping from image representation to spatial transformation by formulating the displacement vector prediction as the weighted summation of several bases. With the multi-scale framework to predict the displacement fields in a coarse-to-fine manner, superior performance can be achieved compared with traditional and learning-based approaches. Comprehensive experiments on two public datasets are conducted to demonstrate the effectiveness of the proposed Deformer module as well as the multi-scale framework.
A Dynamic-Adversarial Mining Approach to the Security of Machine Learning
Mar 24, 2018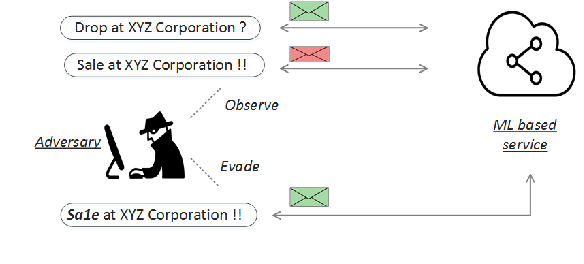

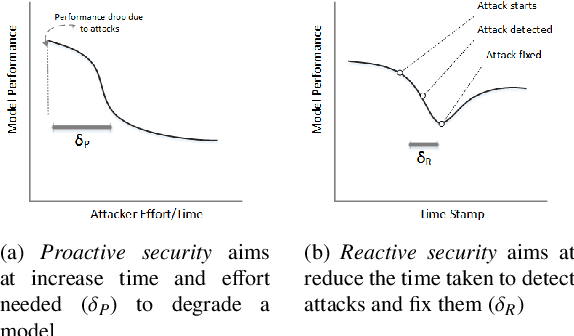

Operating in a dynamic real world environment requires a forward thinking and adversarial aware design for classifiers, beyond fitting the model to the training data. In such scenarios, it is necessary to make classifiers - a) harder to evade, b) easier to detect changes in the data distribution over time, and c) be able to retrain and recover from model degradation. While most works in the security of machine learning has concentrated on the evasion resistance (a) problem, there is little work in the areas of reacting to attacks (b and c). Additionally, while streaming data research concentrates on the ability to react to changes to the data distribution, they often take an adversarial agnostic view of the security problem. This makes them vulnerable to adversarial activity, which is aimed towards evading the concept drift detection mechanism itself. In this paper, we analyze the security of machine learning, from a dynamic and adversarial aware perspective. The existing techniques of Restrictive one class classifier models, Complex learning models and Randomization based ensembles, are shown to be myopic as they approach security as a static task. These methodologies are ill suited for a dynamic environment, as they leak excessive information to an adversary, who can subsequently launch attacks which are indistinguishable from the benign data. Based on empirical vulnerability analysis against a sophisticated adversary, a novel feature importance hiding approach for classifier design, is proposed. The proposed design ensures that future attacks on classifiers can be detected and recovered from. The proposed work presents motivation, by serving as a blueprint, for future work in the area of Dynamic-Adversarial mining, which combines lessons learned from Streaming data mining, Adversarial learning and Cybersecurity.