 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity Theater: On the Vulnerability of Classifiers to Exploratory Attacks
Mar 24, 2018



The increasing scale and sophistication of cyberattacks has led to the adoption of machine learning based classification techniques, at the core of cybersecurity systems. These techniques promise scale and accuracy, which traditional rule or signature based methods cannot. However, classifiers operating in adversarial domains are vulnerable to evasion attacks by an adversary, who is capable of learning the behavior of the system by employing intelligently crafted probes. Classification accuracy in such domains provides a false sense of security, as detection can easily be evaded by carefully perturbing the input samples. In this paper, a generic data driven framework is presented, to analyze the vulnerability of classification systems to black box probing based attacks. The framework uses an exploration exploitation based strategy, to understand an adversary's point of view of the attack defense cycle. The adversary assumes a black box model of the defender's classifier and can launch indiscriminate attacks on it, without information of the defender's model type, training data or the domain of application. Experimental evaluation on 10 real world datasets demonstrates that even models having high perceived accuracy (>90%), by a defender, can be effectively circumvented with a high evasion rate (>95%, on average). The detailed attack algorithms, adversarial model and empirical evaluation, serve.
A Dynamic-Adversarial Mining Approach to the Security of Machine Learning
Mar 24, 2018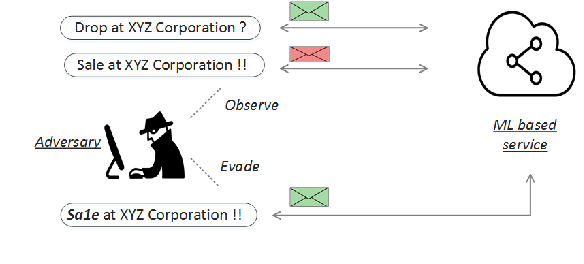

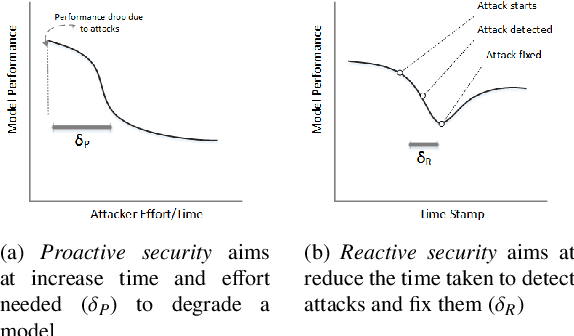

Operating in a dynamic real world environment requires a forward thinking and adversarial aware design for classifiers, beyond fitting the model to the training data. In such scenarios, it is necessary to make classifiers - a) harder to evade, b) easier to detect changes in the data distribution over time, and c) be able to retrain and recover from model degradation. While most works in the security of machine learning has concentrated on the evasion resistance (a) problem, there is little work in the areas of reacting to attacks (b and c). Additionally, while streaming data research concentrates on the ability to react to changes to the data distribution, they often take an adversarial agnostic view of the security problem. This makes them vulnerable to adversarial activity, which is aimed towards evading the concept drift detection mechanism itself. In this paper, we analyze the security of machine learning, from a dynamic and adversarial aware perspective. The existing techniques of Restrictive one class classifier models, Complex learning models and Randomization based ensembles, are shown to be myopic as they approach security as a static task. These methodologies are ill suited for a dynamic environment, as they leak excessive information to an adversary, who can subsequently launch attacks which are indistinguishable from the benign data. Based on empirical vulnerability analysis against a sophisticated adversary, a novel feature importance hiding approach for classifier design, is proposed. The proposed design ensures that future attacks on classifiers can be detected and recovered from. The proposed work presents motivation, by serving as a blueprint, for future work in the area of Dynamic-Adversarial mining, which combines lessons learned from Streaming data mining, Adversarial learning and Cybersecurity.
Handling Adversarial Concept Drift in Streaming Data
Mar 24, 2018



Classifiers operating in a dynamic, real world environment, are vulnerable to adversarial activity, which causes the data distribution to change over time. These changes are traditionally referred to as concept drift, and several approaches have been developed in literature to deal with the problem of drift handling and detection. However, most concept drift handling techniques, approach it as a domain independent task, to make them applicable to a wide gamut of reactive systems. These techniques were developed from an adversarial agnostic perspective, where they are naive and assume that drift is a benign change, which can be fixed by updating the model. However, this is not the case when an active adversary is trying to evade the deployed classification system. In such an environment, the properties of concept drift are unique, as the drift is intended to degrade the system and at the same time designed to avoid detection by traditional concept drift detection techniques. This special category of drift is termed as adversarial drift, and this paper analyzes its characteristics and impact, in a streaming environment. A novel framework for dealing with adversarial concept drift is proposed, called the Predict-Detect streaming framework. Experimental evaluation of the framework, on generated adversarial drifting data streams, demonstrates that this framework is able to provide reliable unsupervised indication of drift, and is able to recover from drifts swiftly. While traditional partially labeled concept drift detection methodologies fail to detect adversarial drifts, the proposed framework is able to detect such drifts and operates with <6% labeled data, on average. Also, the framework provides benefits for active learning over imbalanced data streams, by innately providing for feature space honeypots, where minority class adversarial samples may be captured.
* Journal paper
On the Reliable Detection of Concept Drift from Streaming Unlabeled Data
Mar 31, 2017



Classifiers deployed in the real world operate in a dynamic environment, where the data distribution can change over time. These changes, referred to as concept drift, can cause the predictive performance of the classifier to drop over time, thereby making it obsolete. To be of any real use, these classifiers need to detect drifts and be able to adapt to them, over time. Detecting drifts has traditionally been approached as a supervised task, with labeled data constantly being used for validating the learned model. Although effective in detecting drifts, these techniques are impractical, as labeling is a difficult, costly and time consuming activity. On the other hand, unsupervised change detection techniques are unreliable, as they produce a large number of false alarms. The inefficacy of the unsupervised techniques stems from the exclusion of the characteristics of the learned classifier, from the detection process. In this paper, we propose the Margin Density Drift Detection (MD3) algorithm, which tracks the number of samples in the uncertainty region of a classifier, as a metric to detect drift. The MD3 algorithm is a distribution independent, application independent, model independent, unsupervised and incremental algorithm for reliably detecting drifts from data streams. Experimental evaluation on 6 drift induced datasets and 4 additional datasets from the cybersecurity domain demonstrates that the MD3 approach can reliably detect drifts, with significantly fewer false alarms compared to unsupervised feature based drift detectors. The reduced false alarms enables the signaling of drifts only when they are most likely to affect classification performance. As such, the MD3 approach leads to a detection scheme which is credible, label efficient and general in its applicability.
Evaluating Complex Task through Crowdsourcing: Multiple Views Approach
Mar 30, 2017



With the popularity of massive open online courses, grading through crowdsourcing has become a prevalent approach towards large scale classes. However, for getting grades for complex tasks, which require specific skills and efforts for grading, crowdsourcing encounters a restriction of insufficient knowledge of the workers from the crowd. Due to knowledge limitation of the crowd graders, grading based on partial perspectives becomes a big challenge for evaluating complex tasks through crowdsourcing. Especially for those tasks which not only need specific knowledge for grading, but also should be graded as a whole instead of being decomposed into smaller and simpler subtasks. We propose a framework for grading complex tasks via multiple views, which are different grading perspectives defined by experts for the task, to provide uniformity. Aggregation algorithm based on graders variances are used to combine the grades for each view. We also detect bias patterns of the graders, and debias them regarding each view of the task. Bias pattern determines how the behavior is biased among graders, which is detected by a statistical technique. The proposed approach is analyzed on a synthetic data set. We show that our model gives more accurate results compared to the grading approaches without different views and debiasing algorithm.
Data Driven Exploratory Attacks on Black Box Classifiers in Adversarial Domains
Mar 23, 2017
While modern day web applications aim to create impact at the civilization level, they have become vulnerable to adversarial activity, where the next cyber-attack can take any shape and can originate from anywhere. The increasing scale and sophistication of attacks, has prompted the need for a data driven solution, with machine learning forming the core of many cybersecurity systems. Machine learning was not designed with security in mind, and the essential assumption of stationarity, requiring that the training and testing data follow similar distributions, is violated in an adversarial domain. In this paper, an adversary's view point of a classification based system, is presented. Based on a formal adversarial model, the Seed-Explore-Exploit framework is presented, for simulating the generation of data driven and reverse engineering attacks on classifiers. Experimental evaluation, on 10 real world datasets and using the Google Cloud Prediction Platform, demonstrates the innate vulnerability of classifiers and the ease with which evasion can be carried out, without any explicit information about the classifier type, the training data or the application domain. The proposed framework, algorithms and empirical evaluation, serve as a white hat analysis of the vulnerabilities, and aim to foster the development of secure machine learning frameworks.
Submodular Optimization for Efficient Semi-supervised Support Vector Machines
Aug 23, 2011



In this work we present a quadratic programming approximation of the Semi-Supervised Support Vector Machine (S3VM) problem, namely approximate QP-S3VM, that can be efficiently solved using off the shelf optimization packages. We prove that this approximate formulation establishes a relation between the low density separation and the graph-based models of semi-supervised learning (SSL) which is important to develop a unifying framework for semi-supervised learning methods. Furthermore, we propose the novel idea of representing SSL problems as submodular set functions and use efficient submodular optimization algorithms to solve them. Using this new idea we develop a representation of the approximate QP-S3VM as a maximization of a submodular set function which makes it possible to optimize using efficient greedy algorithms. We demonstrate that the proposed methods are accurate and provide significant improvement in time complexity over the state of the art in the literature.