 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation
Paper and Code
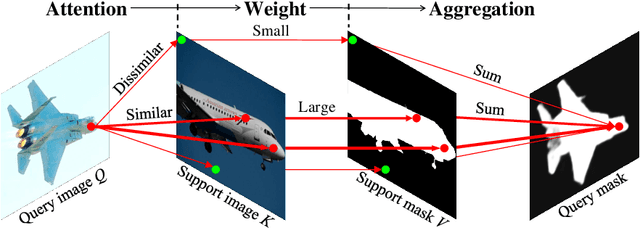


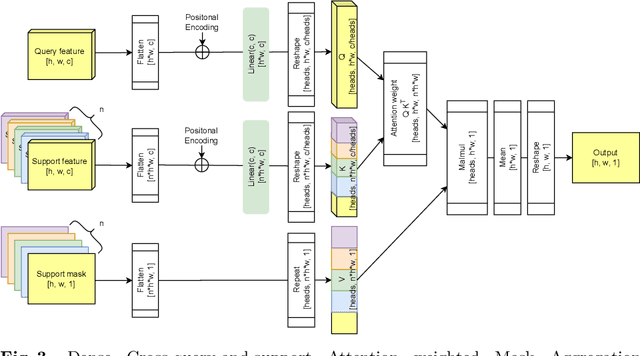
Research into Few-shot Semantic Segmentation (FSS) has attracted great attention, with the goal to segment target objects in a query image given only a few annotated support images of the target class. A key to this challenging task is to fully utilize the information in the support images by exploiting fine-grained correlations between the query and support images. However, most existing approaches either compressed the support information into a few class-wise prototypes, or used partial support information (e.g., only foreground) at the pixel level, causing non-negligible information loss. In this paper, we propose Dense pixel-wise Cross-query-and-support Attention weighted Mask Aggregation (DCAMA), where both foreground and background support information are fully exploited via multi-level pixel-wise correlations between paired query and support features. Implemented with the scaled dot-product attention in the Transformer architecture, DCAMA treats every query pixel as a token, computes its similarities with all support pixels, and predicts its segmentation label as an additive aggregation of all the support pixels' labels -- weighted by the similarities. Based on the unique formulation of DCAMA, we further propose efficient and effective one-pass inference for n-shot segmentation, where pixels of all support images are collected for the mask aggregation at once. Experiments show that our DCAMA significantly advances the state of the art on standard FSS benchmarks of PASCAL-5i, COCO-20i, and FSS-1000, e.g., with 3.1%, 9.7%, and 3.6% absolute improvements in 1-shot mIoU over previous best records. Ablative studies also verify the design DCAMA.