 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming BS Down-Tilt for Air-Ground ISAC Coverage: Antenna Design, Beamforming and User Scheduling
Jan 18, 2026Integrated sensing and communication holds great promise for low-altitude economy applications. However, conventional downtilted base stations primarily provide sectorized forward lobes for ground services, failing to sense air targets due to backward blind zones. In this paper, a novel antenna structure is proposed to enable air-ground beam steering, facilitating simultaneous full-space sensing and communication (S&C). Specifically, instead of inserting a reflector behind the antenna array for backlobe mitigation, an omni-steering plate is introduced to collaborate with the active array for omnidirectional beamforming. Building on this hardware innovation, sum S&C mutual information (MI) is maximized, jointly optimizing user scheduling, passive coefficients of the omni-steering plate, and beamforming of the active array. The problem is decomposed into two subproblems: one for optimizing passive coefficients via Riemannian gradient on the manifold, and the other for optimizing user scheduling and active array beamforming. Exploiting relationships among S&C MI, data decoding MMSE, and parameter estimation MMSE, the original subproblem is equivalently transformed into a sum weighted MMSE problem, rigorously established via the Lagrangian and first-order optimality conditions. Simulations show that the proposed algorithm outperforms baselines in sum-MI and MSE, while providing 360 sensing coverage. Beampattern analysis further demonstrates effective user scheduling and accurate target alignment.
Neural Architecture for Fast and Reliable Coagulation Assessment in Clinical Settings: Leveraging Thromboelastography
Jan 12, 2026In an ideal medical environment, real-time coagulation monitoring can enable early detection and prompt remediation of risks. However, traditional Thromboelastography (TEG), a widely employed diagnostic modality, can only provide such outputs after nearly 1 hour of measurement. The delay might lead to elevated mortality rates. These issues clearly point out one of the key challenges for medical AI development: Mak-ing reasonable predictions based on very small data sets and accounting for variation between different patient populations, a task where conventional deep learning methods typically perform poorly. We present Physiological State Reconstruc-tion (PSR), a new algorithm specifically designed to take ad-vantage of dynamic changes between individuals and to max-imize useful information produced by small amounts of clini-cal data through mapping to reliable predictions and diagnosis. We develop MDFE to facilitate integration of varied temporal signals using multi-domain learning, and jointly learn high-level temporal interactions together with attentions via HLA; furthermore, the parameterized DAM we designed maintains the stability of the computed vital signs. PSR evaluates with 4 TEG-specialized data sets and establishes remarkable perfor-mance -- predictions of R2 > 0.98 for coagulation traits and error reduction around half compared to the state-of-the-art methods, and halving the inferencing time too. Drift-aware learning suggests a new future, with potential uses well be-yond thrombophilia discovery towards medical AI applica-tions with data scarcity.
WiCo-PG: Wireless Channel Foundation Model for Pathloss Map Generation via Synesthesia of Machines
Nov 19, 2025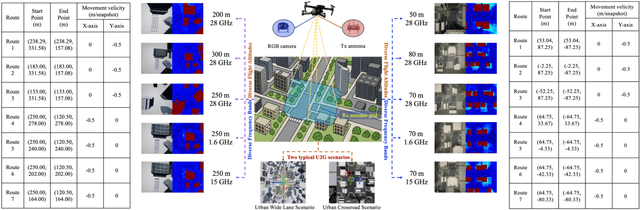
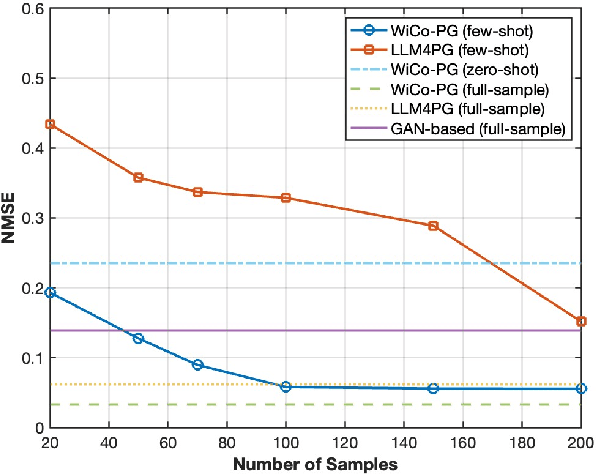
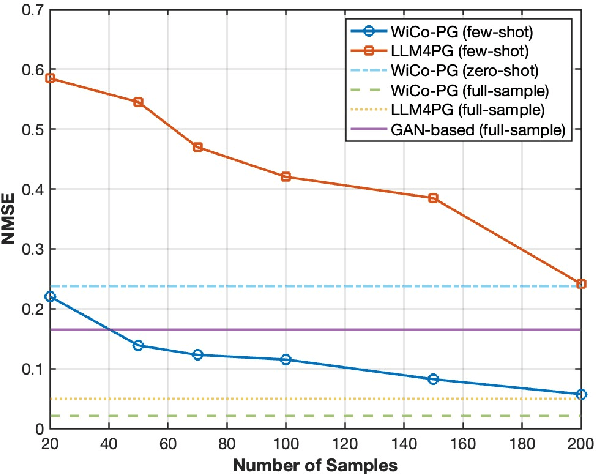
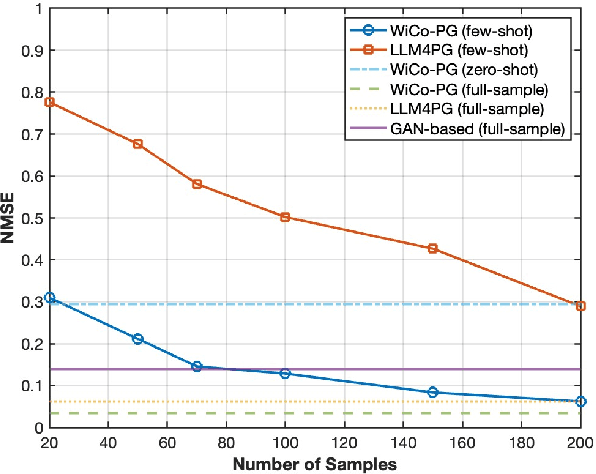
A wireless channel foundation model for pathloss map generation (WiCo-PG) via Synesthesia of Machines (SoM) is developed for the first time. Considering sixth-generation (6G) uncrewed aerial vehicle (UAV)-to-ground (U2G) scenarios, a new multi-modal sensing-communication dataset is constructed for WiCo-PG pre-training, including multiple U2G scenarios, diverse flight altitudes, and diverse frequency bands. Based on the constructed dataset, the proposed WiCo-PG enables cross-modal pathloss map generation by leveraging RGB images from different scenarios and flight altitudes. In WiCo-PG, a novel network architecture designed for cross-modal pathloss map generation based on dual vector quantized generative adversarial networks (VQGANs) and Transformer is proposed. Furthermore, a novel frequency-guided shared-routed mixture of experts (S-R MoE) architecture is designed for cross-modal pathloss map generation. Simulation results demonstrate that the proposed WiCo-PG achieves improved pathloss map generation accuracy through pre-training with a normalized mean squared error (NMSE) of 0.012, outperforming the large language model (LLM)-based scheme, i.e., LLM4PG, and the conventional deep learning-based scheme by more than 6.98 dB. The enhanced generality of the proposed WiCo-PG can further outperform the LLM4PG by at least 1.37 dB using 2.7% samples in few-shot generalization.
NetGPT: A Native-AI Network Architecture Beyond Provisioning Personalized Generative Services
Jul 23, 2023



Large language models (LLMs) have triggered tremendous success to empower daily life by generative information, and the personalization of LLMs could further contribute to their applications due to better alignment with human intents. Towards personalized generative services, a collaborative cloud-edge methodology sounds promising, as it facilitates the effective orchestration of heterogeneous distributed communication and computing resources. In this article, after discussing the pros and cons of several candidate cloud-edge collaboration techniques, we put forward NetGPT to capably deploy appropriate LLMs at the edge and the cloud in accordance with their computing capacity. In addition, edge LLMs could efficiently leverage location-based information for personalized prompt completion, thus benefiting the interaction with cloud LLMs. After deploying representative open-source LLMs (e.g., GPT-2-base and LLaMA model) at the edge and the cloud, we present the feasibility of NetGPT on the basis of low-rank adaptation-based light-weight fine-tuning. Subsequently, we highlight substantial essential changes required for a native artificial intelligence (AI) network architecture towards NetGPT, with special emphasis on deeper integration of communications and computing resources and careful calibration of logical AI workflow. Furthermore, we demonstrate several by-product benefits of NetGPT, given edge LLM's astonishing capability to predict trends and infer intents, which possibly leads to a unified solution for intelligent network management \& orchestration. In a nutshell, we argue that NetGPT is a promising native-AI network architecture beyond provisioning personalized generative services.
RHFedMTL: Resource-Aware Hierarchical Federated Multi-Task Learning
Jun 01, 2023The rapid development of artificial intelligence (AI) over massive applications including Internet-of-things on cellular network raises the concern of technical challenges such as privacy, heterogeneity and resource efficiency. Federated learning is an effective way to enable AI over massive distributed nodes with security. However, conventional works mostly focus on learning a single global model for a unique task across the network, and are generally less competent to handle multi-task learning (MTL) scenarios with stragglers at the expense of acceptable computation and communication cost. Meanwhile, it is challenging to ensure the privacy while maintain a coupled multi-task learning across multiple base stations (BSs) and terminals. In this paper, inspired by the natural cloud-BS-terminal hierarchy of cellular works, we provide a viable resource-aware hierarchical federated MTL (RHFedMTL) solution to meet the heterogeneity of tasks, by solving different tasks within the BSs and aggregating the multi-task result in the cloud without compromising the privacy. Specifically, a primal-dual method has been leveraged to effectively transform the coupled MTL into some local optimization sub-problems within BSs. Furthermore, compared with existing methods to reduce resource cost by simply changing the aggregation frequency, we dive into the intricate relationship between resource consumption and learning accuracy, and develop a resource-aware learning strategy for local terminals and BSs to meet the resource budget. Extensive simulation results demonstrate the effectiveness and superiority of RHFedMTL in terms of improving the learning accuracy and boosting the convergence rate.
Semantics-enhanced Temporal Graph Networks for Content Caching and Energy Saving
Feb 02, 2023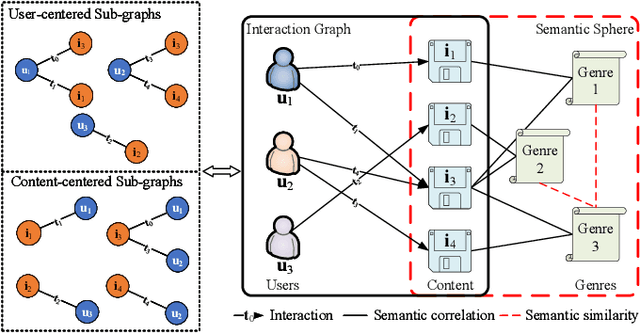
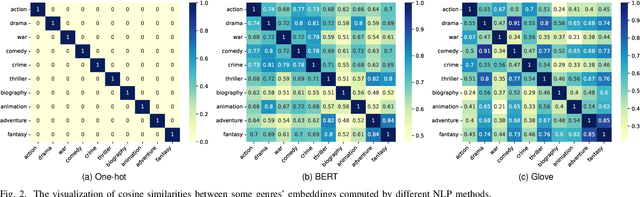

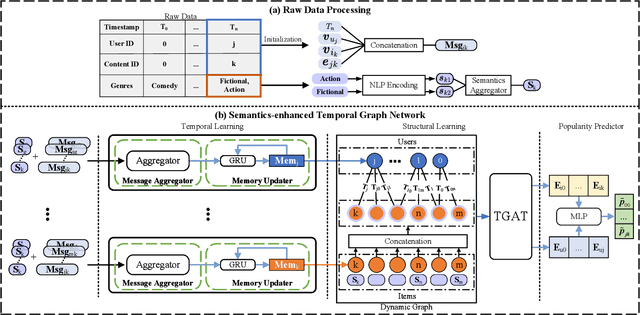
The enormous amount of network equipment and users implies a tremendous growth of Internet traffic for multimedia services. To mitigate the traffic pressure, architectures with in-network storage are proposed to cache popular content at nodes in close proximity to users to shorten the backhaul links. Meanwhile, the reduction of transmission distance also contributes to the energy saving. However, due to limited storage, only a fraction of the content can be cached, while caching the most popular content is cost-effective. Correspondingly, it becomes essential to devise an effective popularity prediction method. In this regard, existing efforts adopt dynamic graph neural network (DGNN) models, but it remains challenging to tackle sparse datasets. In this paper, we first propose a reformative temporal graph network, which is named STGN, that utilizes extra semantic messages to enhance the temporal and structural learning of a DGNN model, since the consideration of semantics can help establish implicit paths within the sparse interaction graph and hence improve the prediction performance. Furthermore, we propose a user-specific attention mechanism to fine-grainedly aggregate various semantics. Finally, extensive simulations verify the superiority of our STGN models and demonstrate their high potential in energy-saving.
AoI-based Temporal Attention Graph Neural Network for Popularity Prediction and Content Caching
Aug 18, 2022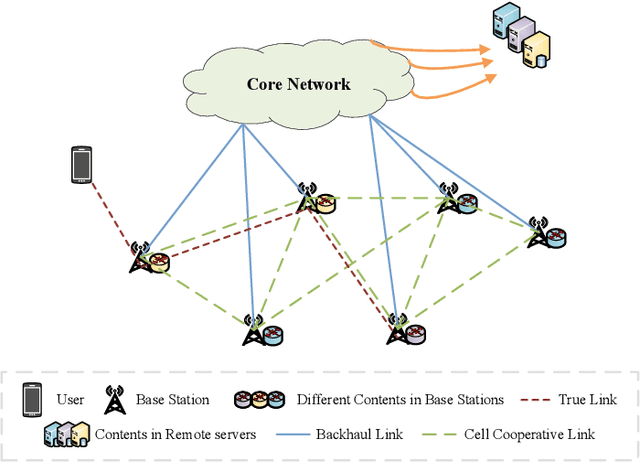
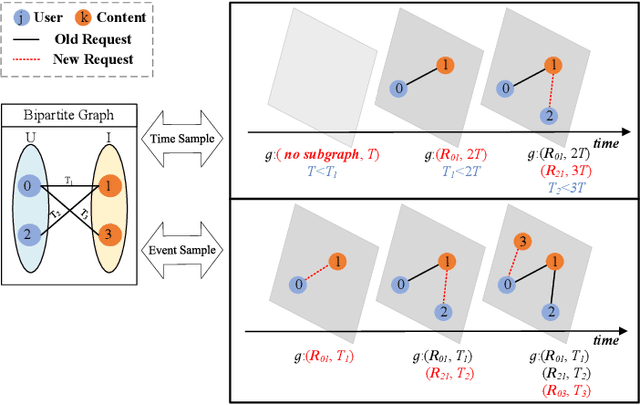
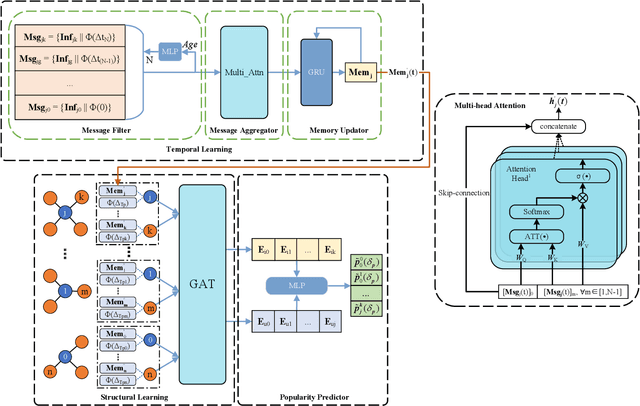
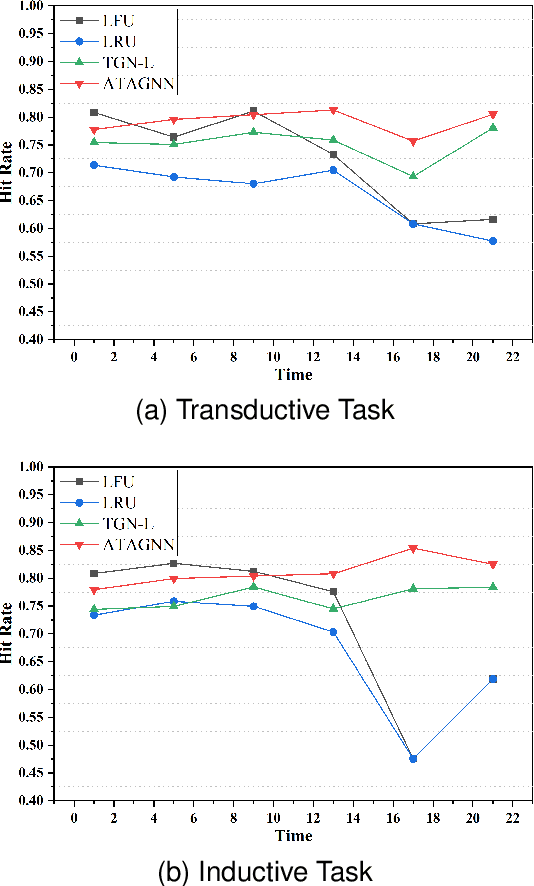
Along with the fast development of network technology and the rapid growth of network equipment, the data throughput is sharply increasing. To handle the problem of backhaul bottleneck in cellular network and satisfy people's requirements about latency, the network architecture like information-centric network (ICN) intends to proactively keep limited popular content at the edge of network based on predicted results. Meanwhile, the interactions between the content (e.g., deep neural network models, Wikipedia-alike knowledge base) and users could be regarded as a dynamic bipartite graph. In this paper, to maximize the cache hit rate, we leverage an effective dynamic graph neural network (DGNN) to jointly learn the structural and temporal patterns embedded in the bipartite graph. Furthermore, in order to have deeper insights into the dynamics within the evolving graph, we propose an age of information (AoI) based attention mechanism to extract valuable historical information while avoiding the problem of message staleness. Combining this aforementioned prediction model, we also develop a cache selection algorithm to make caching decisions in accordance with the prediction results. Extensive results demonstrate that our model can obtain a higher prediction accuracy than other state-of-the-art schemes in two real-world datasets. The results of hit rate further verify the superiority of the caching policy based on our proposed model over other traditional ways.
Rethinking Modern Communication from Semantic Coding to Semantic Communication
Oct 16, 2021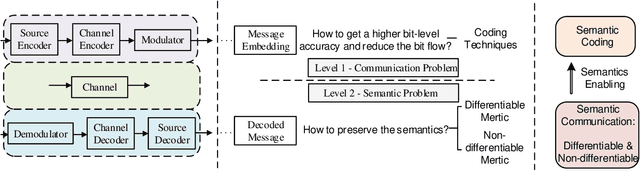
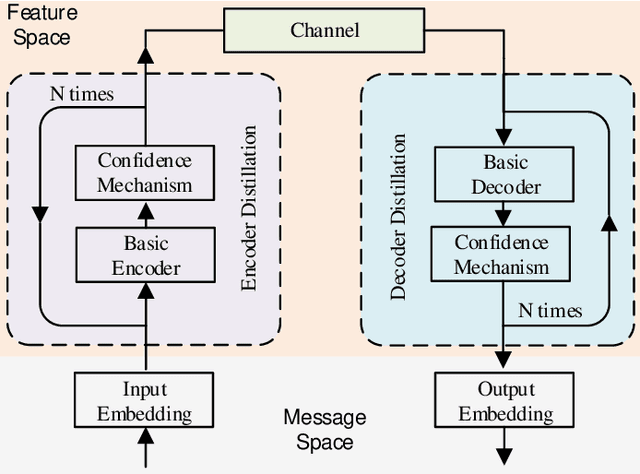
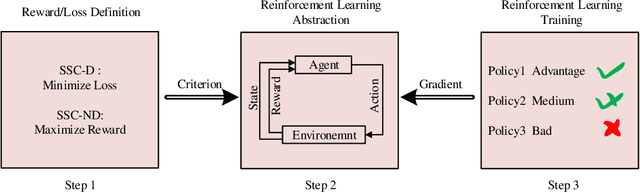
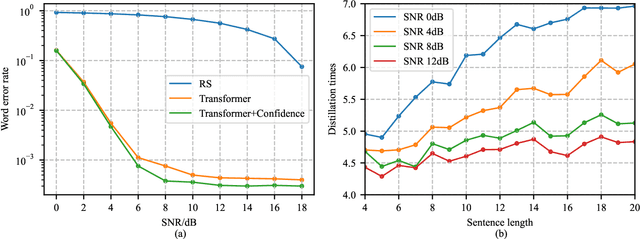
Modern communications are usually designed to pursue a higher bit-level precision and fewer bits required to transmit a message. This article rethinks these two major features and introduces the concept and advantage of semantics that characterizes a new kind of semantics-aware communication mechanism, incorporating both the semantic encoding and the semantic communication problem. Within the unified framework, we analyze the underlying defects of existing semantics-aware techniques and establish a confidence-based distillation mechanism for the joint semantics-noise coding (JSNC) problem, and a reinforcement learning (RL)-powered semantic communication paradigm that endows a system the ability to convey the semantics instead of pursuing the bit level accuracy. On top of these technical contributions, this work provides a new insight to understand how the semantics are processed and represented in a semantics-aware coding and communication system, and verifies the significant benefits of doing so.
Learning Deep Representations by Mutual Information for Person Re-identification
Aug 16, 2019
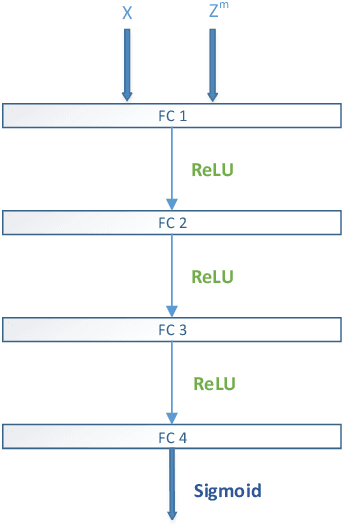

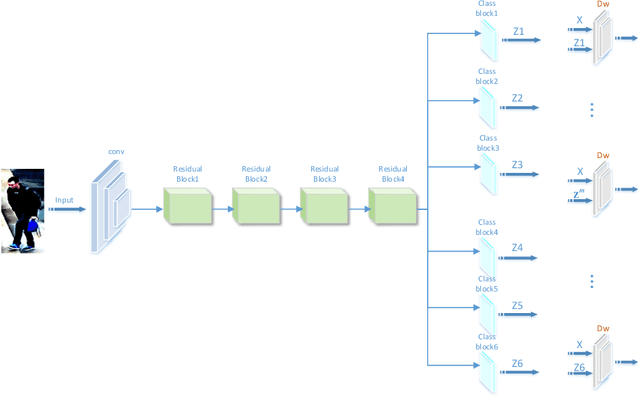
Most existing person re-identification (ReID) methods have good feature representations to distinguish pedestrians with deep convolutional neural network (CNN) and metric learning methods. However, these works concentrate on the similarity between encoder output and ground-truth, ignoring the correlation between input and encoder output, which affects the performance of identifying different pedestrians. To address this limitation, We design a Deep InfoMax (DIM) network to maximize the mutual information (MI) between the input image and encoder output, which doesn't need any auxiliary labels. To evaluate the effectiveness of the DIM network, we propose end-to-end Global-DIM and Local-DIM models. Additionally, the DIM network provides a new solution for cross-dataset unsupervised ReID issue as it needs no extra labels. The experiments prove the superiority of MI theory on the ReID issue, which achieves the state-of-the-art results.