 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively scalable Sinkhorn distances via the Nyström method
Dec 12, 2018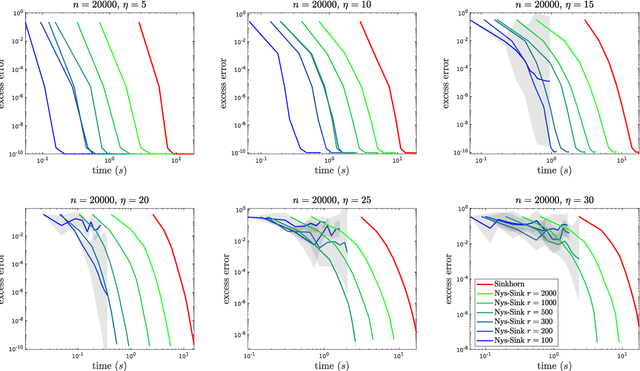
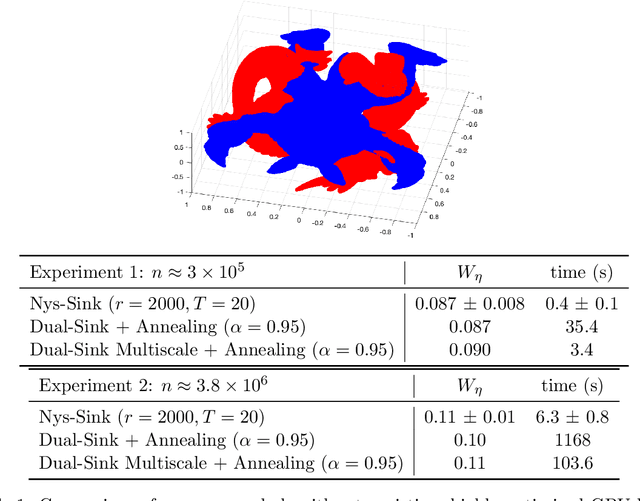
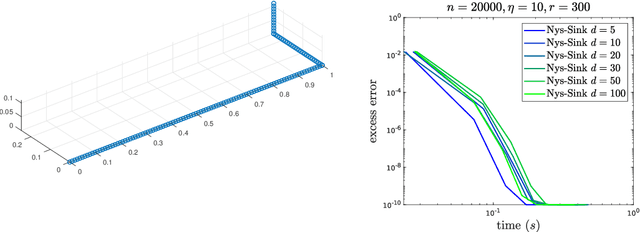
The Sinkhorn distance, a variant of the Wasserstein distance with entropic regularization, is an increasingly popular tool in machine learning and statistical inference. We give a simple, practical, parallelizable algorithm NYS-SINK, based on Nystr\"om approximation, for computing Sinkhorn distances on a massive scale. As we show in numerical experiments, our algorithm easily computes Sinkhorn distances on data sets hundreds of times larger than can be handled by state-of-the-art approaches. We also give provable guarantees establishing that the running time and memory requirements of our algorithm adapt to the intrinsic dimension of the underlying data.
Best Arm Identification for Contaminated Bandits
Oct 19, 2018


This paper studies active learning in the context of robust statistics. Specifically, we propose a variant of the Best Arm Identification problem for \emph{contaminated bandits}, where each arm pull has probability $\varepsilon$ of generating a sample from an arbitrary contamination distribution instead of the true underlying distribution. The goal is to identify the best (or approximately best) true distribution with high probability, with a secondary goal of providing guarantees on the quality of this distribution. The primary challenge of the contaminated bandit setting is that the true distributions are only partially identifiable, even with infinite samples. To address this, we first develop tight, non-asymptotic sample complexity bounds for high-probability estimation of the first two robust moments (median and median absolute deviation) from contaminated samples, which may be of independent interest. Using these results, we adapt several classical Best Arm Identification algorithms to the contaminated bandit setting and derive sample complexity upper bounds for our problem. Finally, we provide matching information-theoretic lower bounds on the sample complexity (up to a small logarithmic factor). Our results suggest an inherent robustness of classical Best Arm Identification algorithms.
Online learning over a finite action set with limited switching
Jun 13, 2018

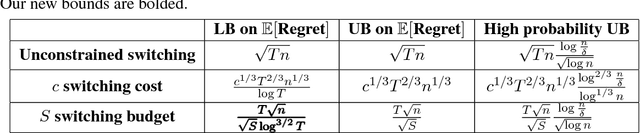

This paper studies the value of switching actions in the Prediction From Experts (PFE) problem and Adversarial Multi-Armed Bandits (MAB) problem. First, we revisit the well-studied and practically motivated setting of PFE with switching costs. Many algorithms are known to achieve the minimax optimal order of $O(\sqrt{T \log n})$ in expectation for both regret and number of switches, where $T$ is the number of iterations and $n$ the number of actions. However, no high probability (h.p.) guarantees are known. Our main technical contribution is the first algorithms which with h.p. achieve this optimal order for both regret and switches. This settles an open problem of [Devroye et al., 2015], and directly implies the first h.p. guarantees for several problems of interest. Next, to investigate the value of switching actions at a more granular level, we introduce the setting of switching budgets, in which algorithms are limited to $S \leq T$ switches between actions. This entails a limited number of free switches, in contrast to the unlimited number of expensive switches in the switching cost setting. Using the above result and several reductions, we unify previous work and completely characterize the complexity of this switching budget setting up to small polylogarithmic factors: for both PFE and MAB, for all switching budgets $S \leq T$, and for both expectation and h.p. guarantees. For PFE, we show the optimal rate is $\tilde{\Theta}(\sqrt{T\log n})$ for $S = \Omega(\sqrt{T\log n})$, and $\min(\tilde{\Theta}(\tfrac{T\log n}{S}), T)$ for $S = O(\sqrt{T \log n})$. Interestingly, the bandit setting does not exhibit such a phase transition; instead we show the minimax rate decays steadily as $\min(\tilde{\Theta}(\tfrac{T\sqrt{n}}{\sqrt{S}}), T)$ for all ranges of $S \leq T$. These results recover and generalize the known minimax rates for the (arbitrary) switching cost setting.
Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration
Feb 07, 2018
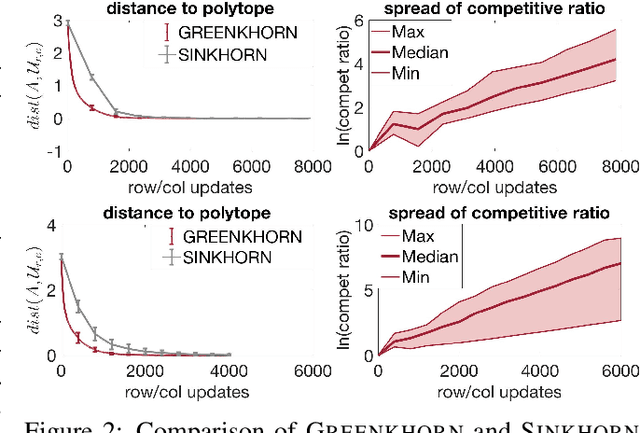
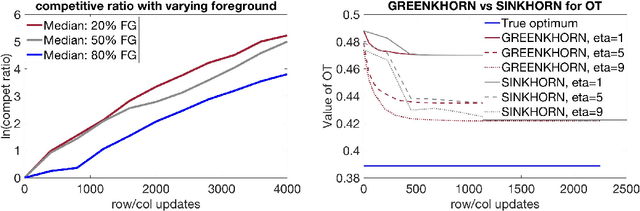
Computing optimal transport distances such as the earth mover's distance is a fundamental problem in machine learning, statistics, and computer vision. Despite the recent introduction of several algorithms with good empirical performance, it is unknown whether general optimal transport distances can be approximated in near-linear time. This paper demonstrates that this ambitious goal is in fact achieved by Cuturi's Sinkhorn Distances. This result relies on a new analysis of Sinkhorn iteration, which also directly suggests a new greedy coordinate descent algorithm, Greenkhorn, with the same theoretical guarantees. Numerical simulations illustrate that Greenkhorn significantly outperforms the classical Sinkhorn algorithm in practice.