 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAN3D: Fast 3D Medical Image Segmentation via Compact Context Aggregation
Sep 22, 2021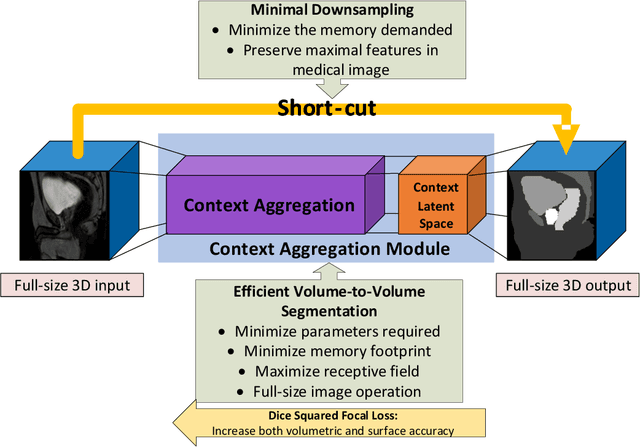

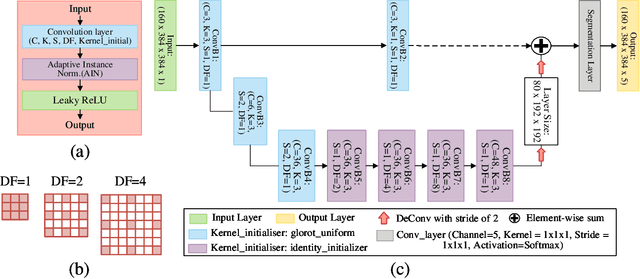
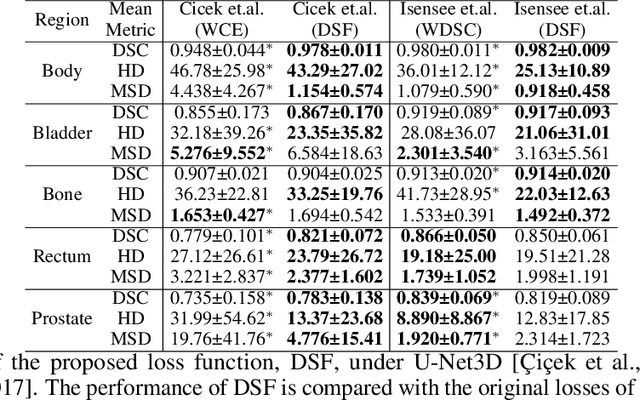
Direct automatic segmentation of objects from 3D medical imaging, such as magnetic resonance (MR) imaging, is challenging as it often involves accurately identifying a number of individual objects with complex geometries within a large volume under investigation. To address these challenges, most deep learning approaches typically enhance their learning capability by substantially increasing the complexity or the number of trainable parameters within their models. Consequently, these models generally require long inference time on standard workstations operating clinical MR systems and are restricted to high-performance computing hardware due to their large memory requirement. Further, to fit 3D dataset through these large models using limited computer memory, trade-off techniques such as patch-wise training are often used which sacrifice the fine-scale geometric information from input images which could be clinically significant for diagnostic purposes. To address these challenges, we present a compact convolutional neural network with a shallow memory footprint to efficiently reduce the number of model parameters required for state-of-art performance. This is critical for practical employment as most clinical environments only have low-end hardware with limited computing power and memory. The proposed network can maintain data integrity by directly processing large full-size 3D input volumes with no patches required and significantly reduces the computational time required for both training and inference. We also propose a novel loss function with extra shape constraint to improve the accuracy for imbalanced classes in 3D MR images.
Manipulating Medical Image Translation with Manifold Disentanglement
Nov 27, 2020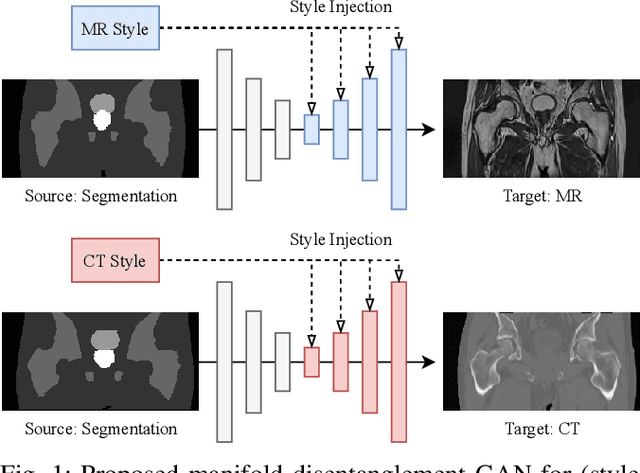
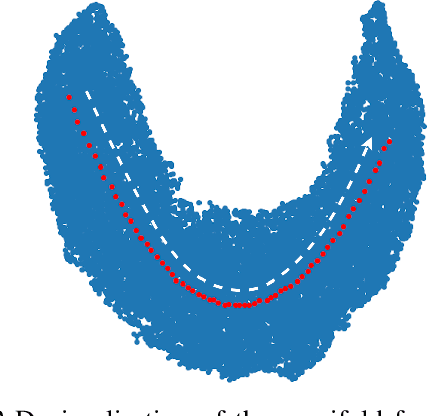

Medical image translation (e.g. CT to MR) is a challenging task as it requires I) faithful translation of domain-invariant features (e.g. shape information of anatomical structures) and II) realistic synthesis of target-domain features (e.g. tissue appearance in MR). In this work, we propose Manifold Disentanglement Generative Adversarial Network (MDGAN), a novel image translation framework that explicitly models these two types of features. It employs a fully convolutional generator to model domain-invariant features, and it uses style codes to separately model target-domain features as a manifold. This design aims to explicitly disentangle domain-invariant features and domain-specific features while gaining individual control of both. The image translation process is formulated as a stylisation task, where the input is "stylised" (translated) into diverse target-domain images based on style codes sampled from the learnt manifold. We test MDGAN for multi-modal medical image translation, where we create two domain-specific manifold clusters on the manifold to translate segmentation maps into pseudo-CT and pseudo-MR images, respectively. We show that by traversing a path across the MR manifold cluster, the target output can be manipulated while still retaining the shape information from the input.
Fabric Image Representation Encoding Networks for Large-scale 3D Medical Image Analysis
Jun 30, 2020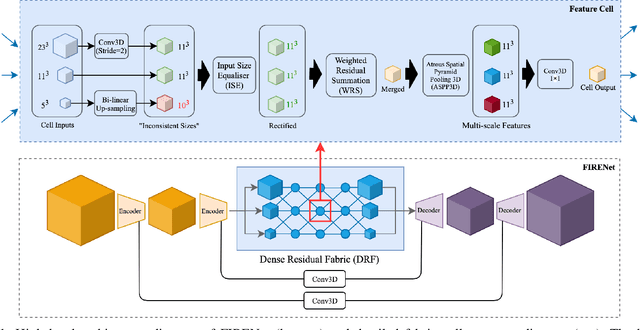
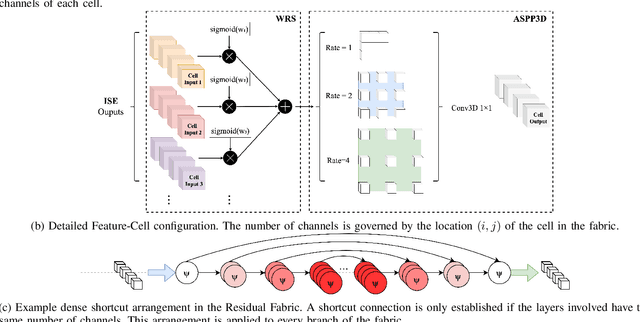
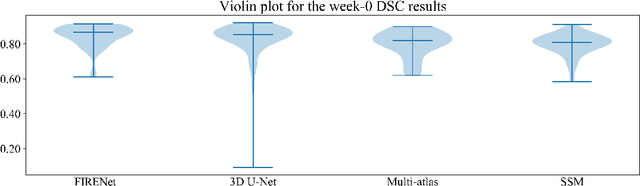
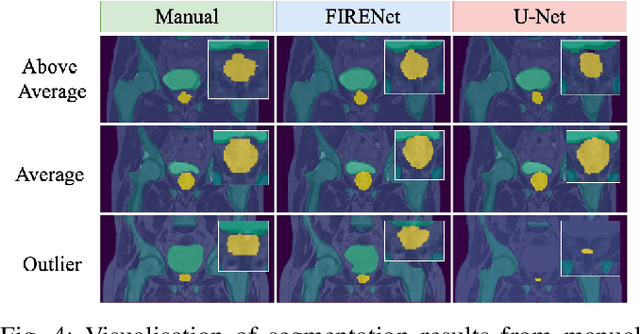
Deep neural networks are parameterised by weights that encode feature representations, whose performance is dictated through generalisation by using large-scale feature-rich datasets. The lack of large-scale labelled 3D medical imaging datasets restrict constructing such generalised networks. In this work, a novel 3D segmentation network, Fabric Image Representation Networks (FIRENet), is proposed to extract and encode generalisable feature representations from multiple medical image datasets in a large-scale manner. FIRENet learns image specific feature representations by way of 3D fabric network architecture that contains exponential number of sub-architectures to handle various protocols and coverage of anatomical regions and structures. The fabric network uses Atrous Spatial Pyramid Pooling (ASPP) extended to 3D to extract local and image-level features at a fine selection of scales. The fabric is constructed with weighted edges allowing the learnt features to dynamically adapt to the training data at an architecture level. Conditional padding modules, which are integrated into the network to reinsert voxels discarded by feature pooling, allow the network to inherently process different-size images at their original resolutions. FIRENet was trained for feature learning via automated semantic segmentation of pelvic structures and obtained a state-of-the-art median DSC score of 0.867. FIRENet was also simultaneously trained on MR (Magnatic Resonance) images acquired from 3D examinations of musculoskeletal elements in the (hip, knee, shoulder) joints and a public OAI knee dataset to perform automated segmentation of bone across anatomy. Transfer learning was used to show that the features learnt through the pelvic segmentation helped achieve improved mean DSC scores of 0.962, 0.963, 0.945 and 0.986 for automated segmentation of bone across datasets.