 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Probabilistic Fusion of Learned Priors into Standard Pipelines for 3D Reconstruction
Jul 27, 2022
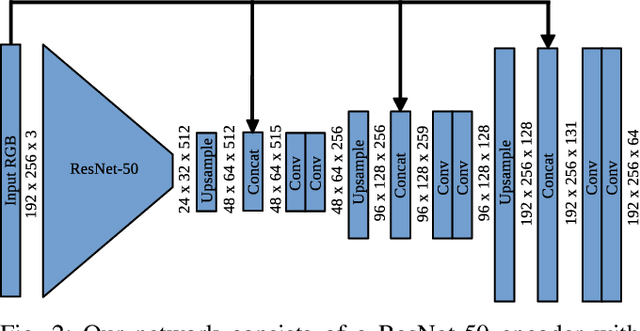
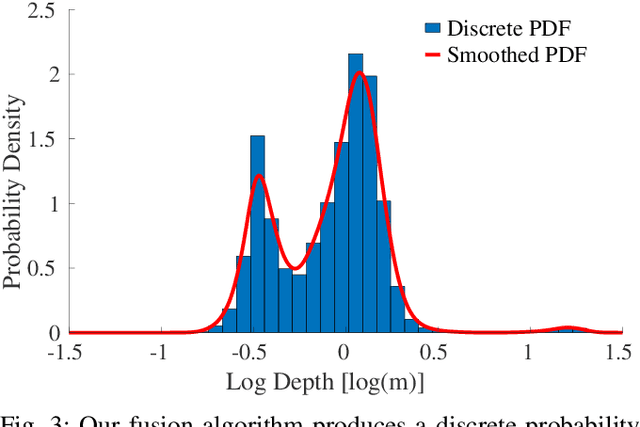

The best way to combine the results of deep learning with standard 3D reconstruction pipelines remains an open problem. While systems that pass the output of traditional multi-view stereo approaches to a network for regularisation or refinement currently seem to get the best results, it may be preferable to treat deep neural networks as separate components whose results can be probabilistically fused into geometry-based systems. Unfortunately, the error models required to do this type of fusion are not well understood, with many different approaches being put forward. Recently, a few systems have achieved good results by having their networks predict probability distributions rather than single values. We propose using this approach to fuse a learned single-view depth prior into a standard 3D reconstruction system. Our system is capable of incrementally producing dense depth maps for a set of keyframes. We train a deep neural network to predict discrete, nonparametric probability distributions for the depth of each pixel from a single image. We then fuse this "probability volume" with another probability volume based on the photometric consistency between subsequent frames and the keyframe image. We argue that combining the probability volumes from these two sources will result in a volume that is better conditioned. To extract depth maps from the volume, we minimise a cost function that includes a regularisation term based on network predicted surface normals and occlusion boundaries. Through a series of experiments, we demonstrate that each of these components improves the overall performance of the system.
DeepFusion: Real-Time Dense 3D Reconstruction for Monocular SLAM using Single-View Depth and Gradient Predictions
Jul 25, 2022



While the keypoint-based maps created by sparse monocular simultaneous localisation and mapping (SLAM) systems are useful for camera tracking, dense 3D reconstructions may be desired for many robotic tasks. Solutions involving depth cameras are limited in range and to indoor spaces, and dense reconstruction systems based on minimising the photometric error between frames are typically poorly constrained and suffer from scale ambiguity. To address these issues, we propose a 3D reconstruction system that leverages the output of a convolutional neural network (CNN) to produce fully dense depth maps for keyframes that include metric scale. Our system, DeepFusion, is capable of producing real-time dense reconstructions on a GPU. It fuses the output of a semi-dense multiview stereo algorithm with the depth and gradient predictions of a CNN in a probabilistic fashion, using learned uncertainties produced by the network. While the network only needs to be run once per keyframe, we are able to optimise for the depth map with each new frame so as to constantly make use of new geometric constraints. Based on its performance on synthetic and real-world datasets, we demonstrate that DeepFusion is capable of performing at least as well as other comparable systems.
CodeMapping: Real-Time Dense Mapping for Sparse SLAM using Compact Scene Representations
Jul 19, 2021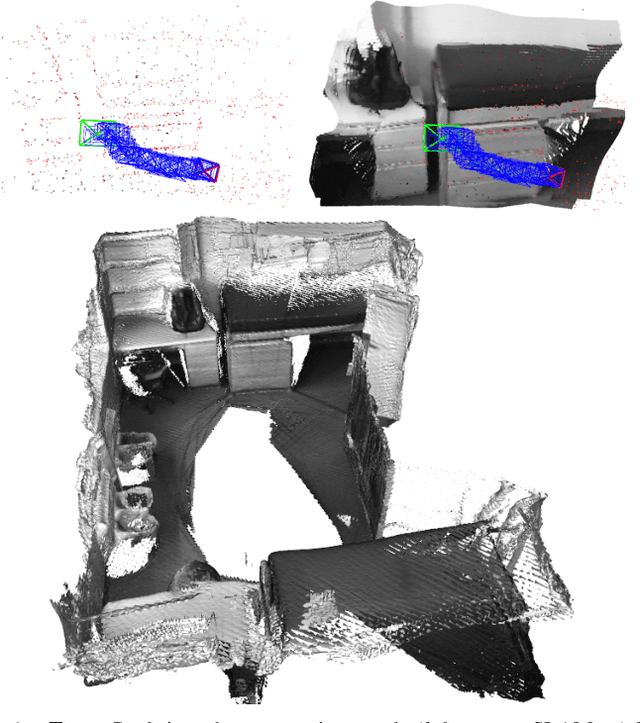

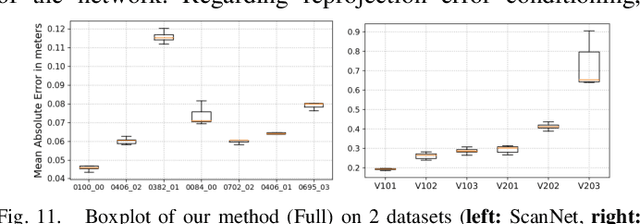

We propose a novel dense mapping framework for sparse visual SLAM systems which leverages a compact scene representation. State-of-the-art sparse visual SLAM systems provide accurate and reliable estimates of the camera trajectory and locations of landmarks. While these sparse maps are useful for localization, they cannot be used for other tasks such as obstacle avoidance or scene understanding. In this paper we propose a dense mapping framework to complement sparse visual SLAM systems which takes as input the camera poses, keyframes and sparse points produced by the SLAM system and predicts a dense depth image for every keyframe. We build on CodeSLAM and use a variational autoencoder (VAE) which is conditioned on intensity, sparse depth and reprojection error images from sparse SLAM to predict an uncertainty-aware dense depth map. The use of a VAE then enables us to refine the dense depth images through multi-view optimization which improves the consistency of overlapping frames. Our mapper runs in a separate thread in parallel to the SLAM system in a loosely coupled manner. This flexible design allows for integration with arbitrary metric sparse SLAM systems without delaying the main SLAM process. Our dense mapper can be used not only for local mapping but also globally consistent dense 3D reconstruction through TSDF fusion. We demonstrate our system running with ORB-SLAM3 and show accurate dense depth estimation which could enable applications such as robotics and augmented reality.
DeepFactors: Real-Time Probabilistic Dense Monocular SLAM
Jan 14, 2020
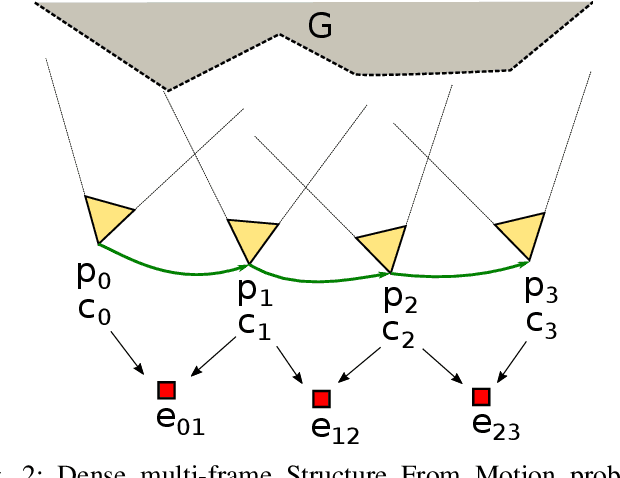

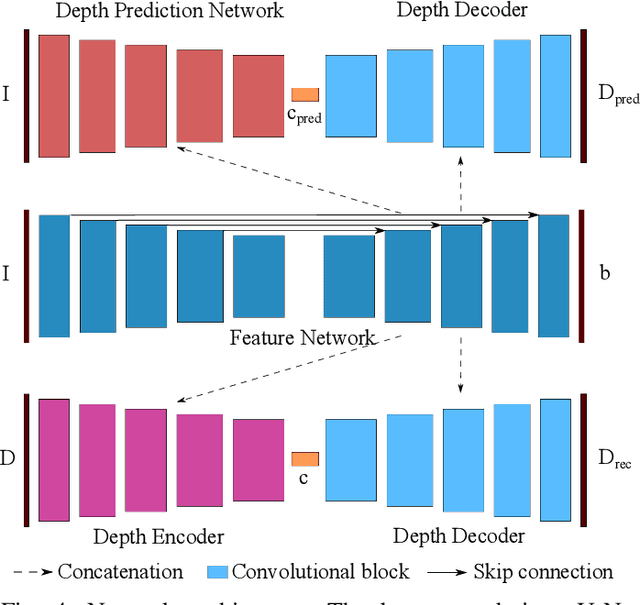
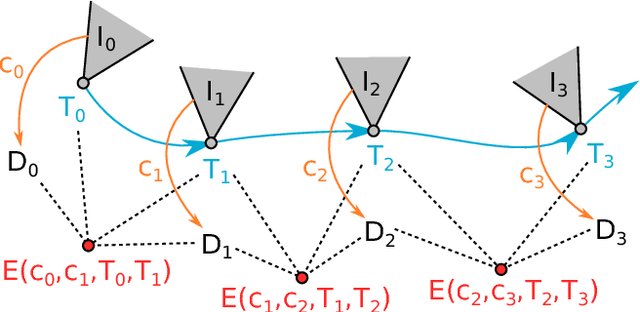
The ability to estimate rich geometry and camera motion from monocular imagery is fundamental to future interactive robotics and augmented reality applications. Different approaches have been proposed that vary in scene geometry representation (sparse landmarks, dense maps), the consistency metric used for optimising the multi-view problem, and the use of learned priors. We present a SLAM system that unifies these methods in a probabilistic framework while still maintaining real-time performance. This is achieved through the use of a learned compact depth map representation and reformulating three different types of errors: photometric, reprojection and geometric, which we make use of within standard factor graph software. We evaluate our system on trajectory estimation and depth reconstruction on real-world sequences and present various examples of estimated dense geometry.
LS-Net: Learning to Solve Nonlinear Least Squares for Monocular Stereo
Sep 09, 2018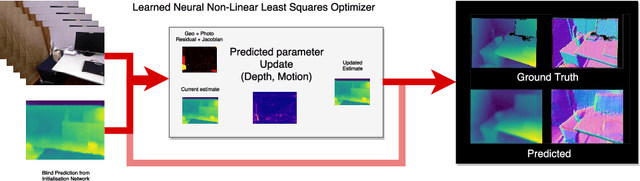
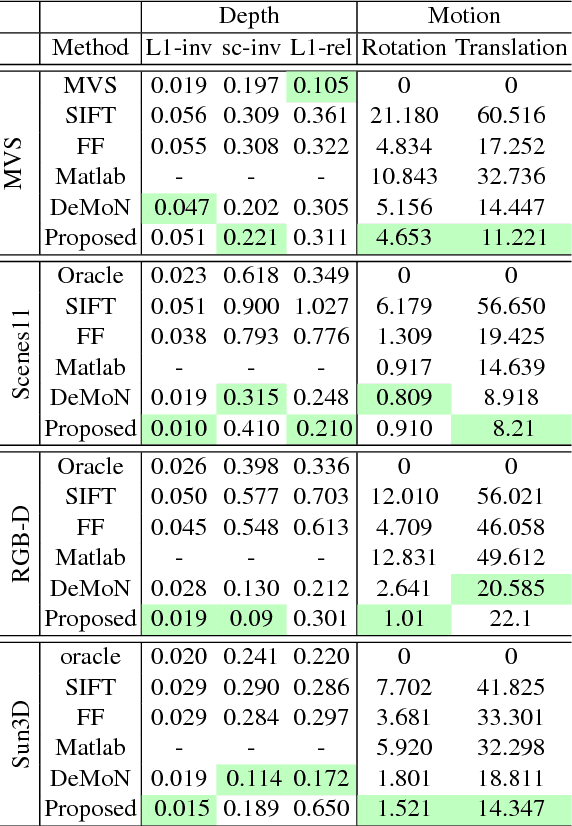
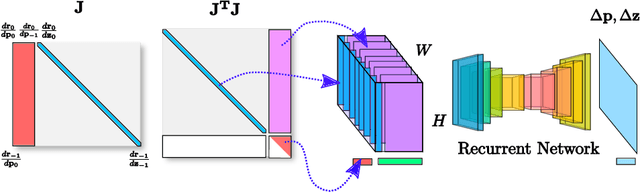
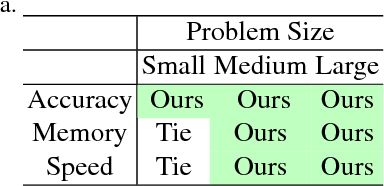
Sum-of-squares objective functions are very popular in computer vision algorithms. However, these objective functions are not always easy to optimize. The underlying assumptions made by solvers are often not satisfied and many problems are inherently ill-posed. In this paper, we propose LS-Net, a neural nonlinear least squares optimization algorithm which learns to effectively optimize these cost functions even in the presence of adversities. Unlike traditional approaches, the proposed solver requires no hand-crafted regularizers or priors as these are implicitly learned from the data. We apply our method to the problem of motion stereo ie. jointly estimating the motion and scene geometry from pairs of images of a monocular sequence. We show that our learned optimizer is able to efficiently and effectively solve this challenging optimization problem.
CodeSLAM - Learning a Compact, Optimisable Representation for Dense Visual SLAM
Apr 03, 2018
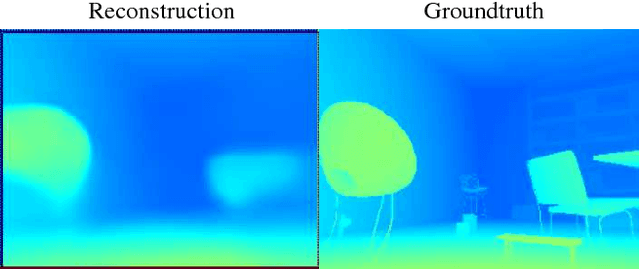
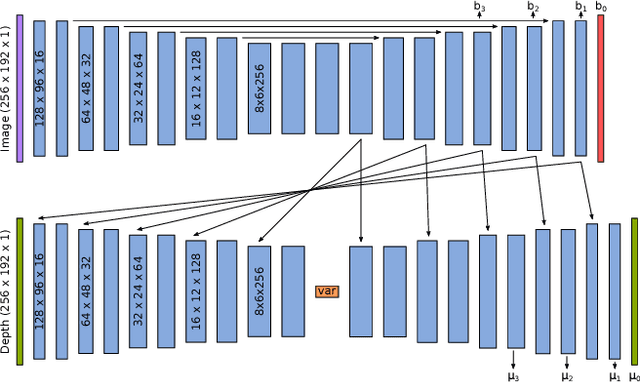
The representation of geometry in real-time 3D perception systems continues to be a critical research issue. Dense maps capture complete surface shape and can be augmented with semantic labels, but their high dimensionality makes them computationally costly to store and process, and unsuitable for rigorous probabilistic inference. Sparse feature-based representations avoid these problems, but capture only partial scene information and are mainly useful for localisation only. We present a new compact but dense representation of scene geometry which is conditioned on the intensity data from a single image and generated from a code consisting of a small number of parameters. We are inspired by work both on learned depth from images, and auto-encoders. Our approach is suitable for use in a keyframe-based monocular dense SLAM system: While each keyframe with a code can produce a depth map, the code can be optimised efficiently jointly with pose variables and together with the codes of overlapping keyframes to attain global consistency. Conditioning the depth map on the image allows the code to only represent aspects of the local geometry which cannot directly be predicted from the image. We explain how to learn our code representation, and demonstrate its advantageous properties in monocular SLAM.
Semantic Texture for Robust Dense Tracking
Aug 29, 2017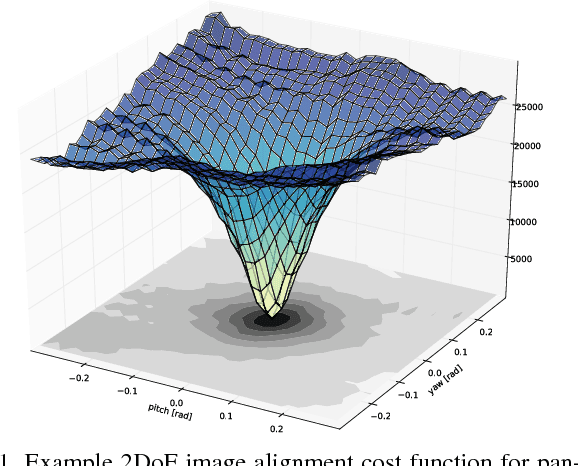
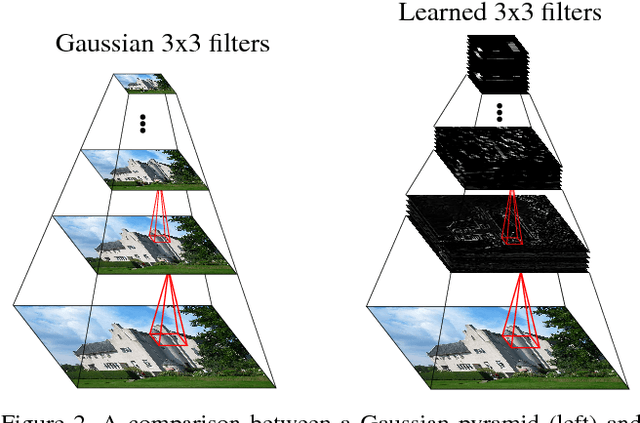
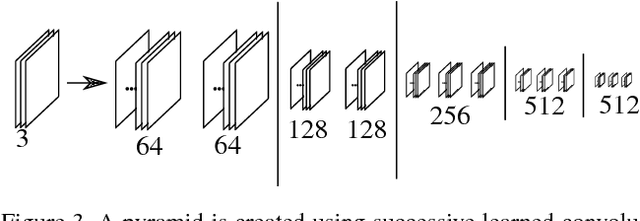

We argue that robust dense SLAM systems can make valuable use of the layers of features coming from a standard CNN as a pyramid of `semantic texture' which is suitable for dense alignment while being much more robust to nuisance factors such as lighting than raw RGB values. We use a straightforward Lucas-Kanade formulation of image alignment, with a schedule of iterations over the coarse-to-fine levels of a pyramid, and simply replace the usual image pyramid by the hierarchy of convolutional feature maps from a pre-trained CNN. The resulting dense alignment performance is much more robust to lighting and other variations, as we show by camera rotation tracking experiments on time-lapse sequences captured over many hours. Looking towards the future of scene representation for real-time visual SLAM, we further demonstrate that a selection using simple criteria of a small number of the total set of features output by a CNN gives just as accurate but much more efficient tracking performance.