 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Texture for Robust Dense Tracking
Paper and Code
Aug 29, 2017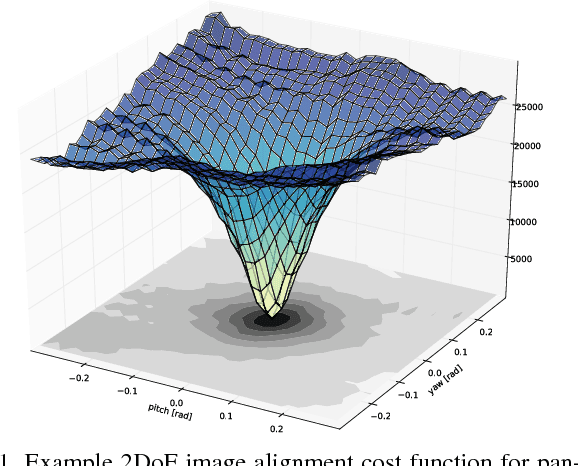
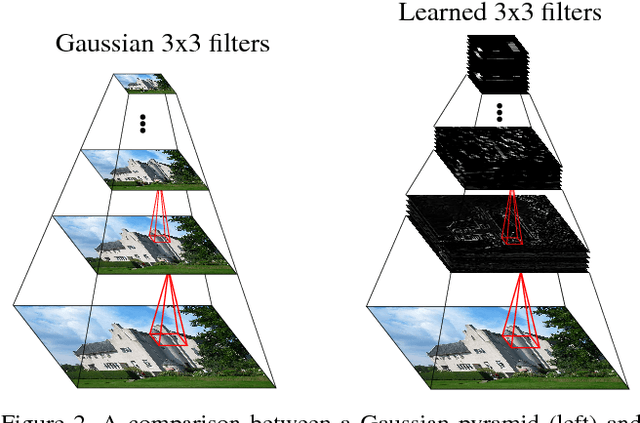
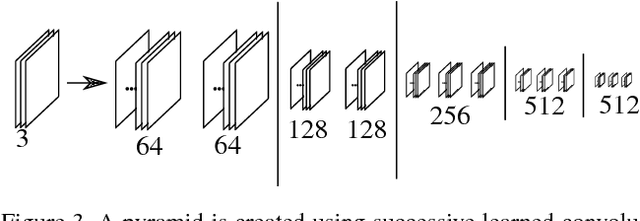

We argue that robust dense SLAM systems can make valuable use of the layers of features coming from a standard CNN as a pyramid of `semantic texture' which is suitable for dense alignment while being much more robust to nuisance factors such as lighting than raw RGB values. We use a straightforward Lucas-Kanade formulation of image alignment, with a schedule of iterations over the coarse-to-fine levels of a pyramid, and simply replace the usual image pyramid by the hierarchy of convolutional feature maps from a pre-trained CNN. The resulting dense alignment performance is much more robust to lighting and other variations, as we show by camera rotation tracking experiments on time-lapse sequences captured over many hours. Looking towards the future of scene representation for real-time visual SLAM, we further demonstrate that a selection using simple criteria of a small number of the total set of features output by a CNN gives just as accurate but much more efficient tracking performance.