 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbGen: Teaching with Reassembled Corpora
May 19, 2026Adapting small instruction-tuned models to specialized domains often relies on supervised fine-tuning (SFT) on curated instruction-response examples, which is expensive to collect at scale. Synthetic training examples generated by a teacher LLM from a domain corpus can reduce this cost, but existing pipelines can produce homogenized outputs and do not consistently capture cross-passage or cross-document dependencies. We introduce EmbGen, a synthetic data generation pipeline that decomposes a corpus into entity-description pairs, reassembles them using semantic structure inferred from embedding similarity, and then generates question-answer (QA) pairs via proximity, intra-cluster, and inter-cluster sampling with cluster-specialized system prompts. We evaluate EmbGen against EntiGraph, InstructLab and Knowledge-Instruct on three datasets of varied semantic heterogeneity, under fixed token budgets (5 and 20 million tokens). We use lexical overlap metrics, an LLM-as-a-judge rubric, and Binary Accuracy, a composed metric combining Factual Accuracy and Completeness for evaluation. EmbGen improves Binary Accuracy on the most heterogeneous dataset by 12.5% at 5M and 88.9% at 20M tokens budget, relative to the strongest baseline, while remaining competitive across other datasets with lower heterogeneity.
Towards the Probabilistic Fusion of Learned Priors into Standard Pipelines for 3D Reconstruction
Jul 27, 2022
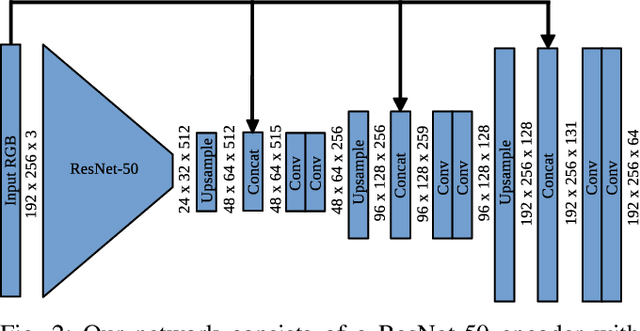
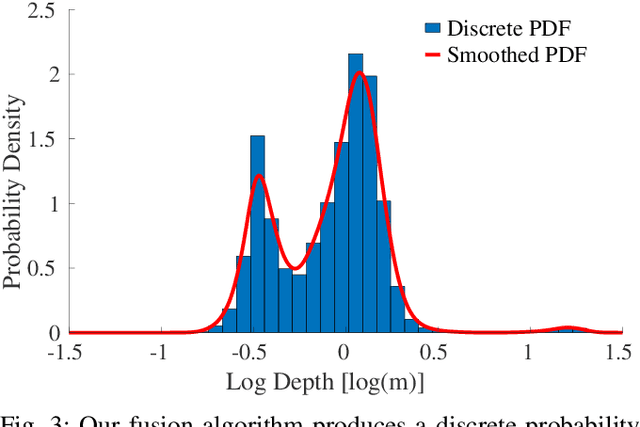

The best way to combine the results of deep learning with standard 3D reconstruction pipelines remains an open problem. While systems that pass the output of traditional multi-view stereo approaches to a network for regularisation or refinement currently seem to get the best results, it may be preferable to treat deep neural networks as separate components whose results can be probabilistically fused into geometry-based systems. Unfortunately, the error models required to do this type of fusion are not well understood, with many different approaches being put forward. Recently, a few systems have achieved good results by having their networks predict probability distributions rather than single values. We propose using this approach to fuse a learned single-view depth prior into a standard 3D reconstruction system. Our system is capable of incrementally producing dense depth maps for a set of keyframes. We train a deep neural network to predict discrete, nonparametric probability distributions for the depth of each pixel from a single image. We then fuse this "probability volume" with another probability volume based on the photometric consistency between subsequent frames and the keyframe image. We argue that combining the probability volumes from these two sources will result in a volume that is better conditioned. To extract depth maps from the volume, we minimise a cost function that includes a regularisation term based on network predicted surface normals and occlusion boundaries. Through a series of experiments, we demonstrate that each of these components improves the overall performance of the system.
Scalable Uncertainty for Computer Vision with Functional Variational Inference
Mar 06, 2020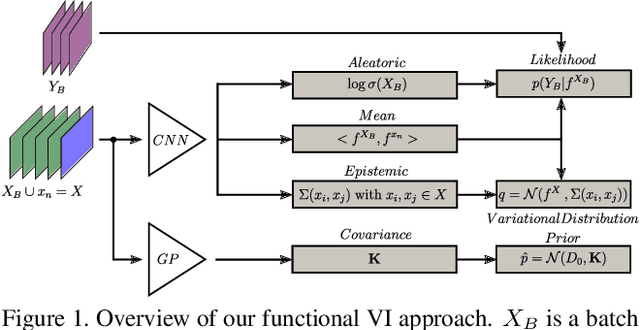

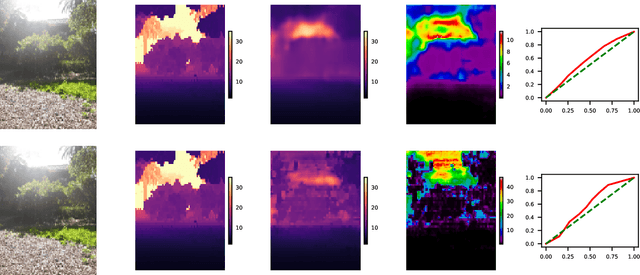
As Deep Learning continues to yield successful applications in Computer Vision, the ability to quantify all forms of uncertainty is a paramount requirement for its safe and reliable deployment in the real-world. In this work, we leverage the formulation of variational inference in function space, where we associate Gaussian Processes (GPs) to both Bayesian CNN priors and variational family. Since GPs are fully determined by their mean and covariance functions, we are able to obtain predictive uncertainty estimates at the cost of a single forward pass through any chosen CNN architecture and for any supervised learning task. By leveraging the structure of the induced covariance matrices, we propose numerically efficient algorithms which enable fast training in the context of high-dimensional tasks such as depth estimation and semantic segmentation. Additionally, we provide sufficient conditions for constructing regression loss functions whose probabilistic counterparts are compatible with aleatoric uncertainty quantification.
X-Section: Cross-section Prediction for Enhanced RGBD Fusion
Apr 08, 2019
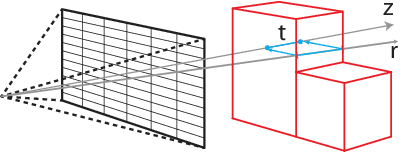

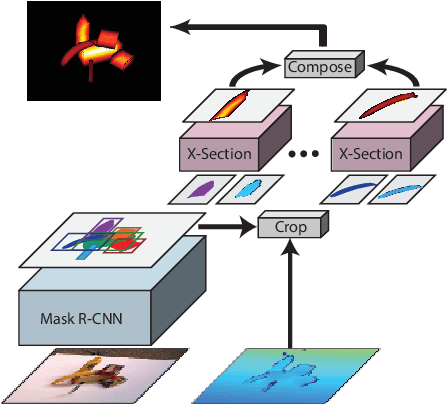
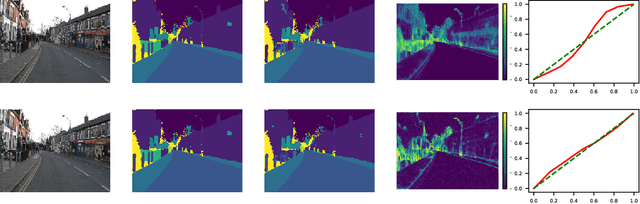
Detailed 3D reconstruction is an important challenge with application to robotics, augmented and virtual reality, which has seen impressive progress throughout the past years. Advancements were driven by the availability of depth cameras (RGB-D), as well as increased compute power, e.g.\ in the form of GPUs -- but also thanks to inclusion of machine learning in the process. Here, we propose X-Section, an RGB-D 3D reconstruction approach that leverages deep learning to make object-level predictions about thicknesses that can be readily integrated into a volumetric multi-view fusion process, where we propose an extension to the popular KinectFusion approach. In essence, our method allows to complete shape in general indoor scenes behind what is sensed by the RGB-D camera, which may be crucial e.g.\ for robotic manipulation tasks or efficient scene exploration. Predicting object thicknesses rather than volumes allows us to work with comparably high spatial resolution without exploding memory and training data requirements on the employed Convolutional Neural Networks. In a series of qualitative and quantitative evaluations, we demonstrate how we accurately predict object thickness and reconstruct general 3D scenes containing multiple objects.