 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqual Confusion Fairness: Measuring Group-Based Disparities in Automated Decision Systems
Jul 02, 2023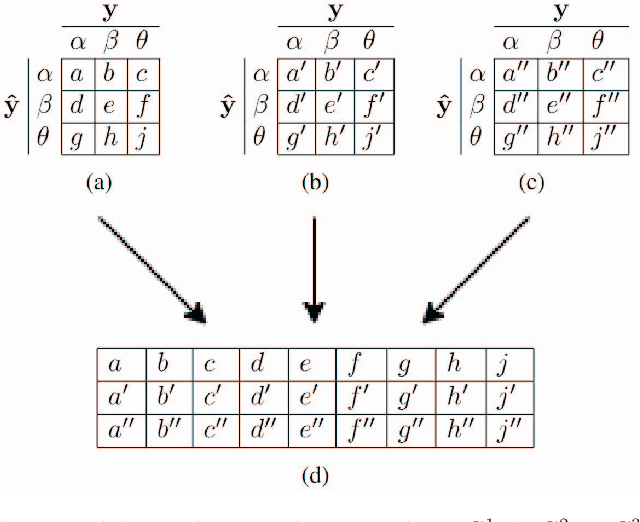
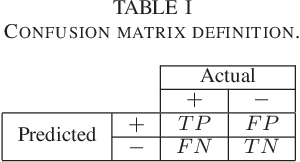
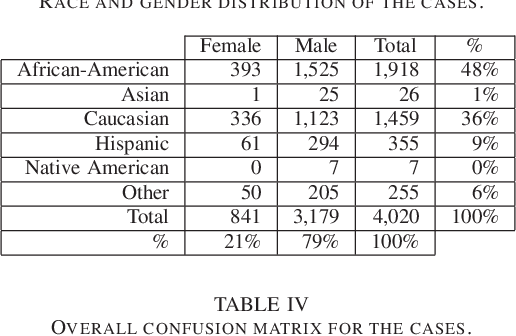
As artificial intelligence plays an increasingly substantial role in decisions affecting humans and society, the accountability of automated decision systems has been receiving increasing attention from researchers and practitioners. Fairness, which is concerned with eliminating unjust treatment and discrimination against individuals or sensitive groups, is a critical aspect of accountability. Yet, for evaluating fairness, there is a plethora of fairness metrics in the literature that employ different perspectives and assumptions that are often incompatible. This work focuses on group fairness. Most group fairness metrics desire a parity between selected statistics computed from confusion matrices belonging to different sensitive groups. Generalizing this intuition, this paper proposes a new equal confusion fairness test to check an automated decision system for fairness and a new confusion parity error to quantify the extent of any unfairness. To further analyze the source of potential unfairness, an appropriate post hoc analysis methodology is also presented. The usefulness of the test, metric, and post hoc analysis is demonstrated via a case study on the controversial case of COMPAS, an automated decision system employed in the US to assist judges with assessing recidivism risks. Overall, the methods and metrics provided here may assess automated decision systems' fairness as part of a more extensive accountability assessment, such as those based on the system accountability benchmark.
Accuracy, Fairness, and Interpretability of Machine Learning Criminal Recidivism Models
Sep 14, 2022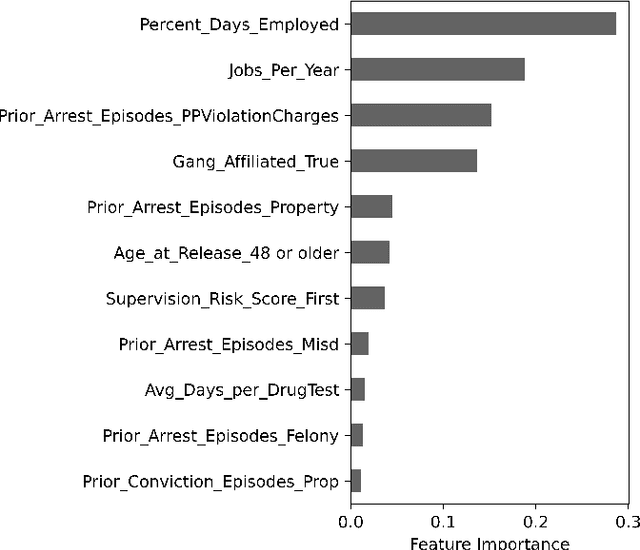
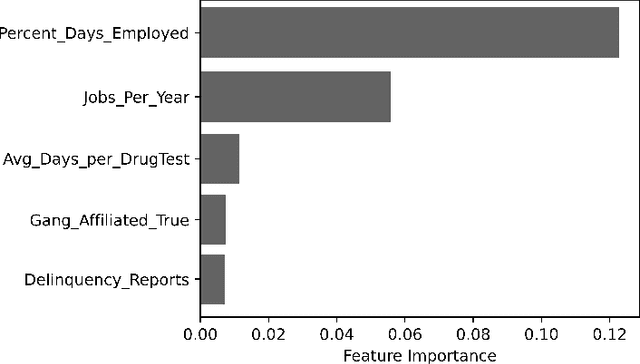
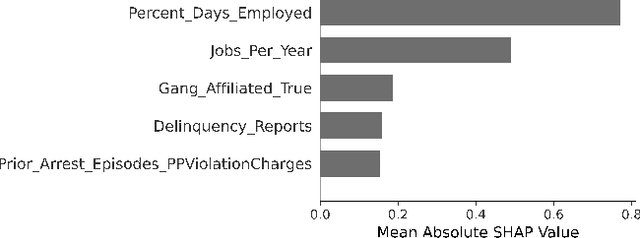
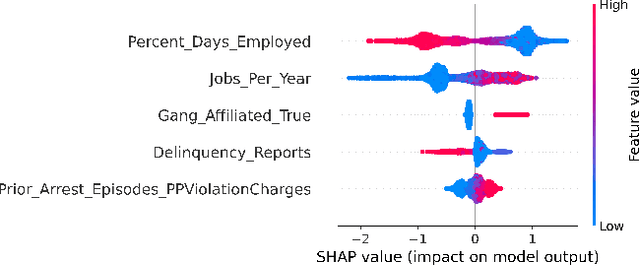
Criminal recidivism models are tools that have gained widespread adoption by parole boards across the United States to assist with parole decisions. These models take in large amounts of data about an individual and then predict whether an individual would commit a crime if released on parole. Although such models are not the only or primary factor in making the final parole decision, questions have been raised about their accuracy, fairness, and interpretability. In this paper, various machine learning-based criminal recidivism models are created based on a real-world parole decision dataset from the state of Georgia in the United States. The recidivism models are comparatively evaluated for their accuracy, fairness, and interpretability. It is found that there are noted differences and trade-offs between accuracy, fairness, and being inherently interpretable. Therefore, choosing the best model depends on the desired balance between accuracy, fairness, and interpretability, as no model is perfect or consistently the best across different criteria.
Error Parity Fairness: Testing for Group Fairness in Regression Tasks
Aug 16, 2022
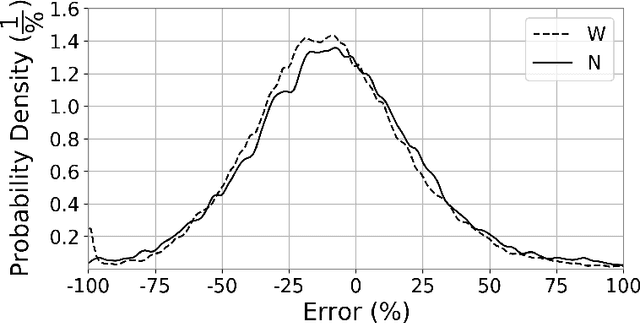
The applications of Artificial Intelligence (AI) surround decisions on increasingly many aspects of human lives. Society responds by imposing legal and social expectations for the accountability of such automated decision systems (ADSs). Fairness, a fundamental constituent of AI accountability, is concerned with just treatment of individuals and sensitive groups (e.g., based on sex, race). While many studies focus on fair learning and fairness testing for the classification tasks, the literature is rather limited on how to examine fairness in regression tasks. This work presents error parity as a regression fairness notion and introduces a testing methodology to assess group fairness based on a statistical hypothesis testing procedure. The error parity test checks whether prediction errors are distributed similarly across sensitive groups to determine if an ADS is fair. It is followed by a suitable permutation test to compare groups on several statistics to explore disparities and identify impacted groups. The usefulness and applicability of the proposed methodology are demonstrated via a case study on COVID-19 projections in the US at the county level, which revealed race-based differences in forecast errors. Overall, the proposed regression fairness testing methodology fills a gap in the fair machine learning literature and may serve as a part of larger accountability assessments and algorithm audits.
System Cards for AI-Based Decision-Making for Public Policy
Mar 01, 2022
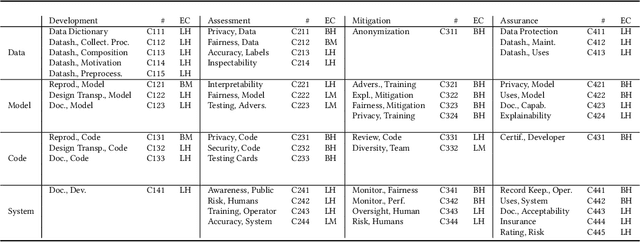
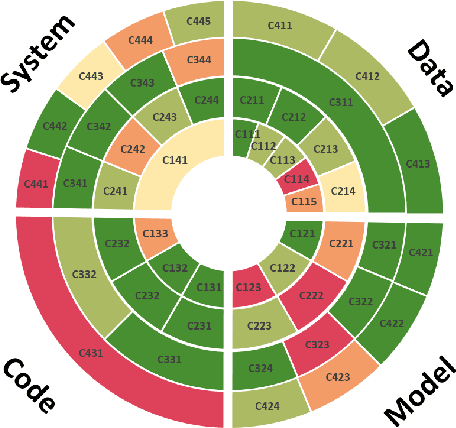
Decisions in public policy are increasingly being made or assisted by automated decision-making algorithms. Many of these algorithms process personal data for tasks such as predicting recidivism, assisting welfare decisions, identifying individuals using face recognition, and more. While potentially improving efficiency and effectiveness, such algorithms are not inherently free from issues such as bias, opaqueness, lack of explainability, maleficence, and the like. Given that the outcomes of these algorithms have significant impacts on individuals and society and are open to analysis and contestation after deployment, such issues must be accounted for before deployment. Formal audits are a way towards ensuring algorithms that are used in public policy meet the appropriate accountability standards. This work, based on an extensive analysis of the literature, proposes a unifying framework for system accountability benchmark for formal audits of artificial intelligence-based decision-aiding systems in public policy as well as system cards that serve as scorecards presenting the outcomes of such audits. The benchmark consists of 50 criteria organized within a four by four matrix consisting of the dimensions of (i) data, (ii) model, (iii) code, (iv) system and (a) development, (b) assessment, (c) mitigation, (d) assurance. Each criterion is described and discussed alongside a suggested measurement scale indicating whether the evaluations are to be performed by humans or computers and whether the evaluation outcomes are binary or on an ordinal scale. The proposed system accountability benchmark reflects the state-of-the-art developments for accountable systems, serves as a checklist for future algorithm audits, and paves the way for sequential work as future research.
A Case Study of Deep Learning Based Multi-Modal Methods for Predicting the Age-Suitability Rating of Movie Trailers
Jan 26, 2021
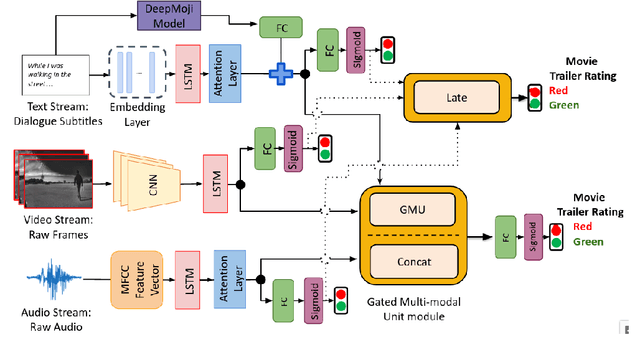
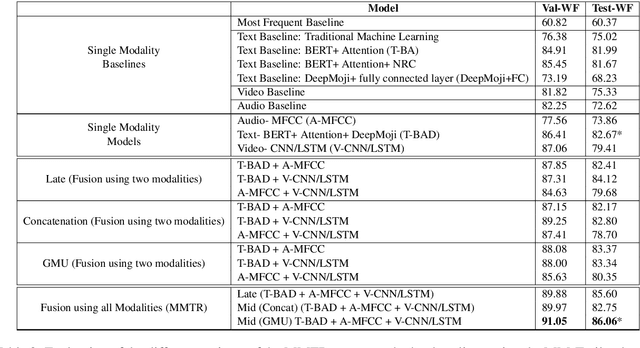
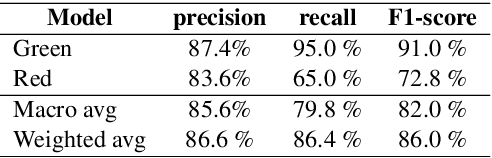
In this work, we explore different approaches to combine modalities for the problem of automated age-suitability rating of movie trailers. First, we introduce a new dataset containing videos of movie trailers in English downloaded from IMDB and YouTube, along with their corresponding age-suitability rating labels. Secondly, we propose a multi-modal deep learning pipeline addressing the movie trailer age suitability rating problem. This is the first attempt to combine video, audio, and speech information for this problem, and our experimental results show that multi-modal approaches significantly outperform the best mono and bimodal models in this task.
DBLFace: Domain-Based Labels for NIR-VIS Heterogeneous Face Recognition
Oct 08, 2020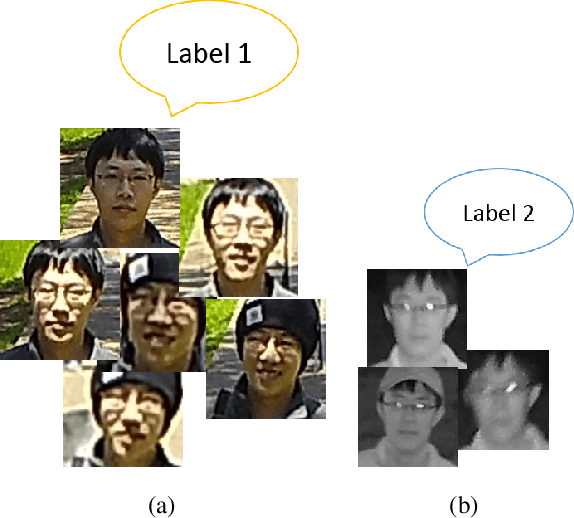
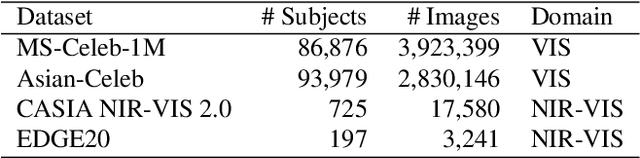
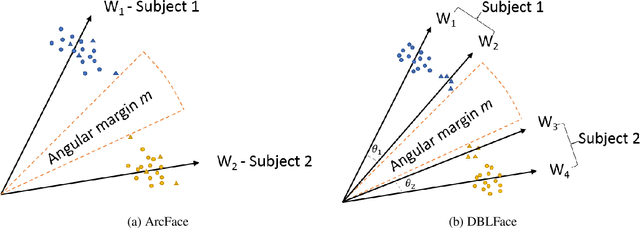
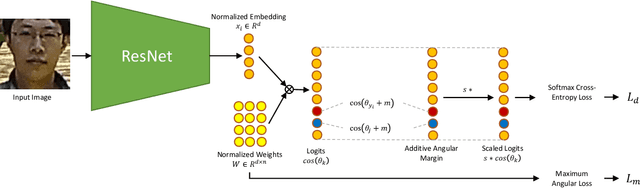
Deep learning-based domain-invariant feature learning methods are advancing in near-infrared and visible (NIR-VIS) heterogeneous face recognition. However, these methods are prone to overfitting due to the large intra-class variation and the lack of NIR images for training. In this paper, we introduce Domain-Based Label Face (DBLFace), a learning approach based on the assumption that a subject is not represented by a single label but by a set of labels. Each label represents images of a specific domain. In particular, a set of two labels per subject, one for the NIR images and one for the VIS images, are used for training a NIR-VIS face recognition model. The classification of images into different domains reduces the intra-class variation and lessens the negative impact of data imbalance in training. To train a network with sets of labels, we introduce a domain-based angular margin loss and a maximum angular loss to maintain the inter-class discrepancy and to enforce the close relationship of labels in a set. Quantitative experiments confirm that DBLFace significantly improves the rank-1 identification rate by 6.7% on the EDGE20 dataset and achieves state-of-the-art performance on the CASIA NIR-VIS 2.0 dataset.
DETCID: Detection of Elongated Touching Cells with Inhomogeneous Illumination using a Deep Adversarial Network
Jul 13, 2020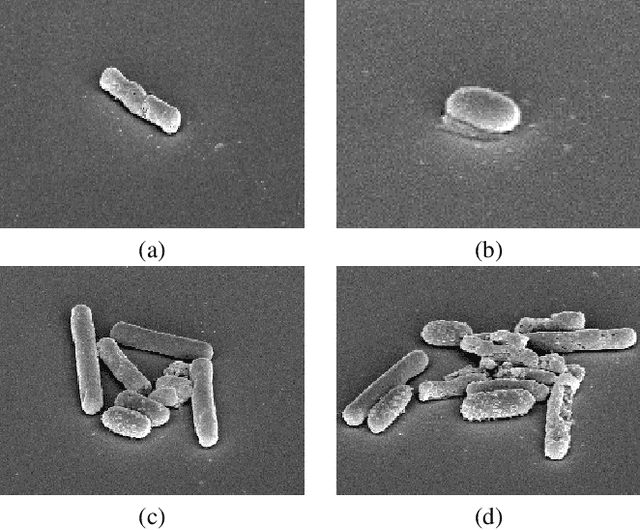
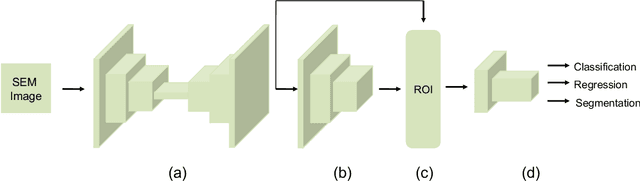
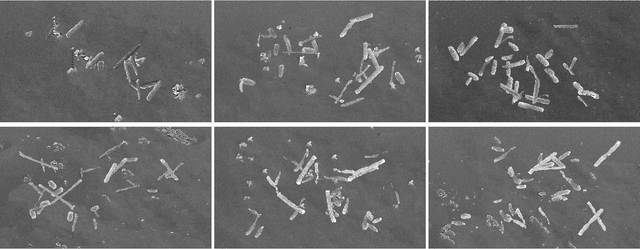

Clostridioides difficile infection (C. diff) is the most common cause of death due to secondary infection in hospital patients in the United States. Detection of C. diff cells in scanning electron microscopy (SEM) images is an important task to quantify the efficacy of the under-development treatments. However, detecting C. diff cells in SEM images is a challenging problem due to the presence of inhomogeneous illumination and occlusion. An Illumination normalization pre-processing step destroys the texture and adds noise to the image. Furthermore, cells are often clustered together resulting in touching cells and occlusion. In this paper, DETCID, a deep cell detection method using adversarial training, specifically robust to inhomogeneous illumination and occlusion, is proposed. An adversarial network is developed to provide region proposals and pass the proposals to a feature extraction network. Furthermore, a modified IoU metric is developed to allow the detection of touching cells in various orientations. The results indicate that DETCID outperforms the state-of-the-art in detection of touching cells in SEM images by at least 20 percent improvement of mean average precision.
On Improving the Generalization of Face Recognition in the Presence of Occlusions
Jun 11, 2020

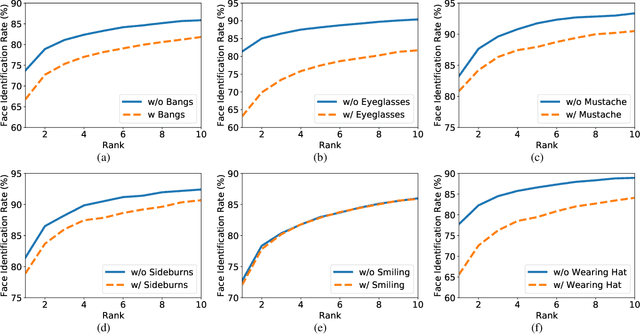

In this paper, we address a key limitation of existing 2D face recognition methods: robustness to occlusions. To accomplish this task, we systematically analyzed the impact of facial attributes on the performance of a state-of-the-art face recognition method and through extensive experimentation, quantitatively analyzed the performance degradation under different types of occlusion. Our proposed Occlusion-aware face REcOgnition (OREO) approach learned discriminative facial templates despite the presence of such occlusions. First, an attention mechanism was proposed that extracted local identity-related region. The local features were then aggregated with the global representations to form a single template. Second, a simple, yet effective, training strategy was introduced to balance the non-occluded and occluded facial images. Extensive experiments demonstrated that OREO improved the generalization ability of face recognition under occlusions by (10.17%) in a single-image-based setting and outperformed the baseline by approximately (2%) in terms of rank-1 accuracy in an image-set-based scenario.
Adversarial Representation Learning for Text-to-Image Matching
Aug 28, 2019
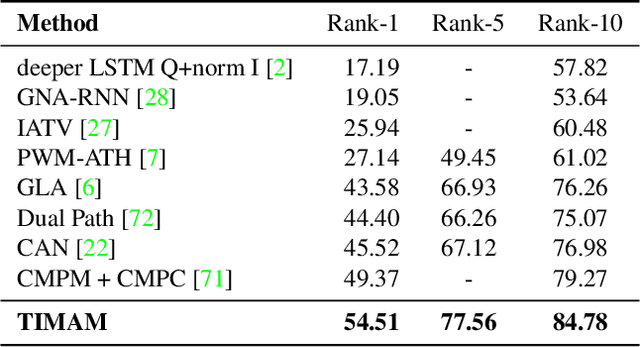

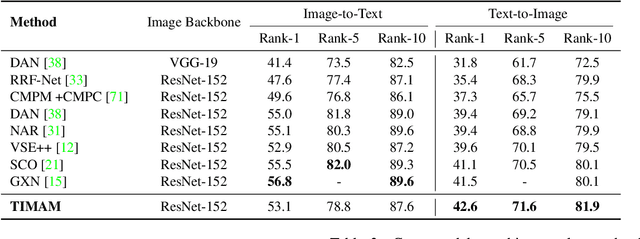
For many computer vision applications such as image captioning, visual question answering, and person search, learning discriminative feature representations at both image and text level is an essential yet challenging problem. Its challenges originate from the large word variance in the text domain as well as the difficulty of accurately measuring the distance between the features of the two modalities. Most prior work focuses on the latter challenge, by introducing loss functions that help the network learn better feature representations but fail to account for the complexity of the textual input. With that in mind, we introduce TIMAM: a Text-Image Modality Adversarial Matching approach that learns modality-invariant feature representations using adversarial and cross-modal matching objectives. In addition, we demonstrate that BERT, a publicly-available language model that extracts word embeddings, can successfully be applied in the text-to-image matching domain. The proposed approach achieves state-of-the-art cross-modal matching performance on four widely-used publicly-available datasets resulting in absolute improvements ranging from 2% to 5% in terms of rank-1 accuracy.
Occlusion-guided compact template learning for ensemble deep network-based pose-invariant face recognition
Apr 15, 2019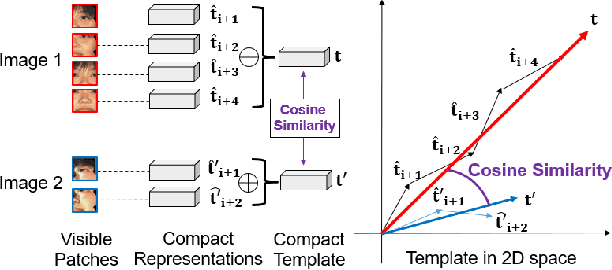

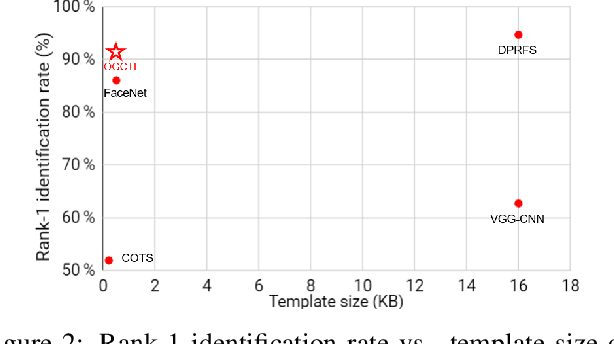
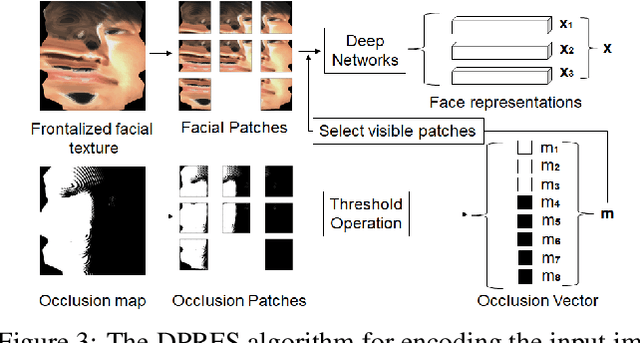
Concatenation of the deep network representations extracted from different facial patches helps to improve face recognition performance. However, the concatenated facial template increases in size and contains redundant information. Previous solutions aim to reduce the dimensionality of the facial template without considering the occlusion pattern of the facial patches. In this paper, we propose an occlusion-guided compact template learning (OGCTL) approach that only uses the information from visible patches to construct the compact template. The compact face representation is not sensitive to the number of patches that are used to construct the facial template and is more suitable for incorporating the information from different view angles for image-set based face recognition. Instead of using occlusion masks in face matching (e.g., DPRFS [38]), the proposed method uses occlusion masks in template construction and achieves significantly better image-set based face verification performance on a challenging database with a template size that is an order-of-magnitude smaller than DPRFS.