 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Cards for AI-Based Decision-Making for Public Policy
Paper and Code
Mar 01, 2022
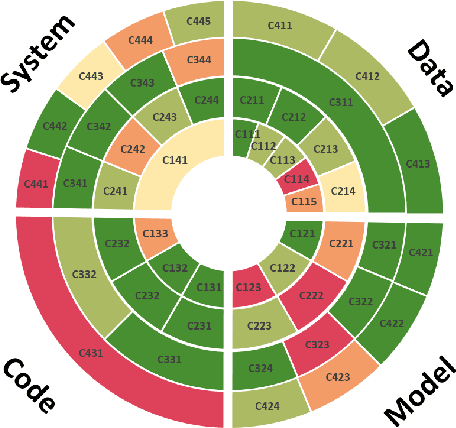
Decisions in public policy are increasingly being made or assisted by automated decision-making algorithms. Many of these algorithms process personal data for tasks such as predicting recidivism, assisting welfare decisions, identifying individuals using face recognition, and more. While potentially improving efficiency and effectiveness, such algorithms are not inherently free from issues such as bias, opaqueness, lack of explainability, maleficence, and the like. Given that the outcomes of these algorithms have significant impacts on individuals and society and are open to analysis and contestation after deployment, such issues must be accounted for before deployment. Formal audits are a way towards ensuring algorithms that are used in public policy meet the appropriate accountability standards. This work, based on an extensive analysis of the literature, proposes a unifying framework for system accountability benchmark for formal audits of artificial intelligence-based decision-aiding systems in public policy as well as system cards that serve as scorecards presenting the outcomes of such audits. The benchmark consists of 50 criteria organized within a four by four matrix consisting of the dimensions of (i) data, (ii) model, (iii) code, (iv) system and (a) development, (b) assessment, (c) mitigation, (d) assurance. Each criterion is described and discussed alongside a suggested measurement scale indicating whether the evaluations are to be performed by humans or computers and whether the evaluation outcomes are binary or on an ordinal scale. The proposed system accountability benchmark reflects the state-of-the-art developments for accountable systems, serves as a checklist for future algorithm audits, and paves the way for sequential work as future research.